On considère deux jeux de 54 cartes à jouer. Pour les mélanger, on créer un troisième paquet en empilant les cartes aléatoirement piochées dans un des deux jeux. Quand l’un des deux jeux est vide, on empile le jeu restant sur le troisième paquet. On modélisera les deux jeux de 54 cartes par deux listes contenant respectivement les entiers de 101 à 154 et de 201 à 254. Écrire une fonction python qui réalise le mélange.
Exercice 2 (Bataille, pile)
On considère un jeu de 52 cartes à jouer (pas de joker) que l’on modélise par une liste contenant quatre fois les entiers de 1 à 13. La valeur d’une carte est égale à son numéro. On distribue ensuite aléatoirement 13 cartes à quatre joueurs qui les empilent consciencieusement devant eux. A chaque tour de jeu, les quatre joueurs posent la carte au sommet de leur pile au milieu. Celui qui a la carte la plus forte remporte le pli, c’est à dire les quatre cartes du tour. S’il y a égalité, on tire au sort le joueur qui gagne rafle le pli. Le joueur qui a la fin a le plus de points gagne la partie. Écrire un programme Python qui simule ce jeu.
Exercice 3 (La bonne syntaxe,pile)
L’analyse syntaxique est une phase indispensable de la compilation des programmes. Les piles sont particulièrement bien adaptées à ce genre de traitements. On va se limiter à la reconnaissance des expressions bien parenthésés. Nous devons écrire un programme qui :—accepte les expressions comme (a), (a b)((c d e)) ou (((a)(b c d))(e)) où a, b, etc. sont des expressions quelconques sans parenthèses—rejette les expressions comme a )(, (a b)((c) ou (((a b)(c d e f))))On remarque d’abord que les expressions a, b, c .. qui apparaissent n’ont aucune importance pour savoir si l’expression est bien parenthésée. On va lire l’expression sous la forme d’une chaine de caractères et utiliser une pile. Lors de la lecture dela chaine, on empile les ”(”. Pour les ”)”, on vérifie d’abord si le sommet de la pile est ”(”, dans ce cas, on dépile. Sinon, on empile le ”(”. A la fin de l’algorithme, si l’expression est bien parenthésée, la pile est vide.Écrire un algorithme utilisant une pile et ses primitives.
Exercice 4 (Évaluation d’une expression arithmétique, pile)
Nous allons voir ici une utilisation des piles pour évaluer des expressions arithmétiques.Par exemple, on souhaite évaluer(3×(5+2×3)+4)×2On se contentera d’évaluer des expressions correctement écrites avec seulement des nombres à un seul chiffre et uniquement des sommes et des produits.
1. On commence par écrire l’expression en notation ”postfixé” ou inverse polonaise Dans cette notation, on écrit les opérations après les nombres plutôt qu’avant.Par exemple,2+3s’écrira2,3,+
Ecrire l’expression(3×(5+2×3)+4)×2 en postfixé.
2. En lisant de gauche à droite l’expression postfixé, on construit une Pile suivant les règles suivantes :—Si on lit un nombre, on l’empile—Si on lit une opération, on dépile deux nombres et on effectue l’opération entre ces deux nombres et on l’empile.
3. Ecrire en pseudo code, une séquence qui permet d’évaluer l’expression.
4. Implémenter l’algorithme en python.
Exercice 5 (file)
Dans un supermarché il y a 5 caisses et une file d’attente commune. Dès qu’une caisse est libre, le client en tête de file y est envoyé. Le temps de passage en caisse est aléatoirement compris entre 3 et 10 minutes. Il y a dix clients dans la file d’attente.
1. Réaliser une simulation de leurs passages en caisses et afficher en combien de minutes tous les clients sont passés.
2. Refaire quelques essais avec plus de clients.
Pour la file d’attente , vous utiliserez une file avec l’objet deque sous python, voir description objet deque ici.
Par exemple voici la liste d’attente:
from collections import deque #import container deque
file_attente=['1','2','3','4','5','6','7','8','9','10'] #la liste d'attente commune avec 10 clients
d = deque(file_attente) #création file client
Retire et renvoie un élément de l’extrémité droite de la deque. S’il n’y a aucun élément, lève une exception IndexError.
popleft()
Retire et renvoie un élément de l’extrémité gauche de la deque. S’il n’y a aucun élément, lève une exception IndexError.
Pour la liste des caisses, vous utiliserez une liste [0,0,0,0,0], premier élément temps caisse 1, ici à 0, puis temps caisse 2 ou un dictionnaire {1: 0, 2: 0, 3: 0, 4: 0, 5: 0}, clé 1 = caisse 1 avec sa valeur = temps ici à 0.
Exercice 6
Un poste de contrôle est alimenté en pièces toutes les 7 minutes. Ces pièces sont de quatre types qui nécessitent respectivement
4, 6, 8 et 9 minutes pour être contrôlés. Les fréquences des quatre types sont identiques.
1. A l’aide d’une file, simuler le fonctionnement du poste de contrôle pendant 1 heure, puis 80 heures.
2. Calculer le nombre de pièces en attente de contrôle
3. Déterminer la durée de séjour des pièces dans le poste de contrôle. Afficher celle de la dernière
4. Le contrôleur fait une pause de 15 minutes toutes les 4 heures. Déterminer le nombre d’heures effectives de travail.
Exercice 7
Un restaurant de 50 tables à 2 couverts ouvre ses portes pendant 4 heures chaque soir. L’intervalle de temps entre l’arrivée de deux groupes de clients est d’environ 2 minutes. Les groupes sont constitués aléatoirement de 2 à 6 convives avec des fréquences identiques.
Les tables peuvent être rassemblées pour les groupes de plus de 2 personnes. Lorsqu’un groupe arrive, il attend que des tables en nombre suffisant soient libres.
Une fois assis, le groupe reste pendant une durée aléatoirement comprise entre 60 et 120 minutes.
Simuler le fonctionnement du restaurant pendant une soirée.
Afficher le nombre de clients servis lors d’un service et nombre moyen de clients par table.
Exercice 2 du sujet 10 de l’épreuve pratique de 2021
Faire l’exercice 2 du Sujet n°10 de l’épreuve pratique de 2021
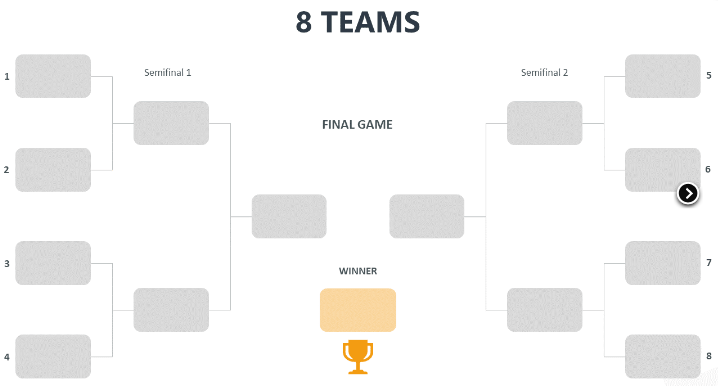
Beaucoup de tournoi sportif sont organisés avec une structure qui représente les matchs joués ou à jouer dans le tournoi. Le principe de base est que chaque branche rassemble deux joueurs (ou deux équipes). Le gagnant avance et le perdant est éliminé. C’est en tout cas le fonctionnement avec élimination Directe.
Ce graphique si on commence par le vainqueur ressemble à un arbre.
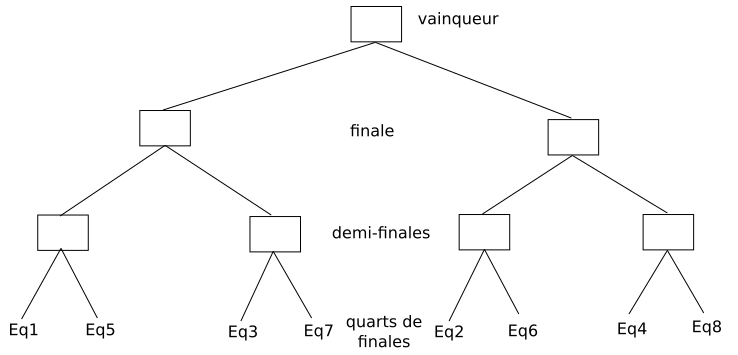
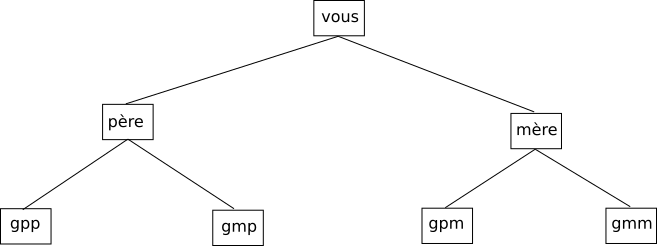
Nous avons ci-dessous ce que l’on appelle une structure en arbre. On peut aussi retrouver cette même structure dans un arbre généalogique :
Dernier exemple, les systèmes de fichiers dans les systèmes de type UNIX ont aussi une structure en arbre.système de fichiers de type UNIX
Les arbres sont des types abstraits très utilisés en informatique. On les utilise notamment quand on a besoin d’une structure hiérarchique des données : dans l’exemple ci-dessous le fichier grub.cfg ne se trouve pas au même niveau que le fichier rapport.odt (le fichier grub.cfg se trouve « plus proche » de la racine / que le fichier rapport.odt). On ne pourrait pas avec une simple liste qui contiendrait les noms des fichiers et des répertoires, rendre compte de cette hiérarchie (plus ou moins « proche » de la racine). On trouve souvent dans cette hiérarchie une notion de temps (les quarts de finale sont avant les demi-finales ou encore votre grand-mère paternelle est née avant votre père), mais ce n’est pas une obligation (voir l’arborescence du système de fichiers).
Les arbres binaires sont des cas particuliers d’arbre : l’arbre du tournoi de rugby et l’arbre « père, mère… » sont des arbres binaires, en revanche, l’arbre représentant la structure du système de fichier n’est pas un arbre binaire. Dans un arbre binaire, on a au maximum 2 branches qui partent d’un élément (pour le système de fichiers, on a 7 branches qui partent de la racine : ce n’est donc pas un arbre binaire). Dans la suite nous allons uniquement travailler sur les arbres binaires.
Soit l’arbre binaire suivant :
Un peu de vocabulaire :
chaque élément de l’arbre est appelé noeud (par exemple : A, B, C, D,…,P et Q sont des noeuds)
le noeud initial (A) est appelé noeud racine ou plus simplement racine
On dira que le noeud E et le noeud D sont les fils du noeud B. On dira que le noeud B est le père des noeuds E et D
Dans un arbre binaire, un noeud possède au plus 2 fils
Un noeud n’ayant aucun fils est appelé feuille (exemples : D, H, N, O, J, K, L, P et Q sont des feuilles)
À partir d’un noeud (qui n’est pas une feuille), on peut définir un sous-arbre gauche et un sous-arbre droite (exemple : à partir de C on va trouver un sous-arbre gauche composé des noeuds F, J et K et un sous-arbre droit composé des noeuds G, L, M, P et Q)
On appelle arête le segment qui relie 2 noeuds.
On appelle profondeur d’un nœud ou d’une feuille dans un arbre binaire le nombre de nœuds du chemin qui va de la racine à ce nœud. La racine d’un arbre est à une profondeur 1, et la profondeur d’un nœud est égale à la profondeur de son prédécesseur plus 1. Si un noeud est à une profondeur p, tous ses successeurs sont à une profondeur p+1. Exemples : profondeur de B = 2 ; profondeur de I = 4 ; profondeur de P = 5 ATTENTION : on trouve aussi dans certains livres la profondeur de la racine égale à 0 (on trouve alors : profondeur de B = 1 ; profondeur de I = 3 ; profondeur de P = 4). Les 2 définitions sont valables, il faut juste préciser si vous considérez que la profondeur de la racine est de 1 ou de 0.
On appelle hauteur d’un arbre la profondeur maximale des nœuds de l’arbre. Exemple : la profondeur de P = 5, c’est un des noeuds les plus profond, donc la hauteur de l’arbre est de 5. ATTENTION : comme on trouve 2 définitions pour la profondeur, on peut trouver 2 résultats différents pour la hauteur : si on considère la profondeur de la racine égale à 1, on aura bien une hauteur de 5, mais si l’on considère que la profondeur de la racine est de 0, on aura alors une hauteur de 4.
Il est aussi important de bien noter que l’on peut aussi voir les arbres comme des structures récursives : les fils d’un noeud sont des arbres (sous-arbre gauche et un sous-arbre droite dans le cas d’un arbre binaire), ces arbres sont eux mêmes constitués d’arbres…
À faire vous-même 1
Trouvez un autre exemple de données qui peuvent être représentées par un arbre binaire (dans le domaine de votre choix). Dessinez au moins une partie de cet arbre binaire. Déterminez la hauteur de l’arbre que vous aurez dessiné.
Python ne propose pas de façon native l’implémentation des arbres binaires. Mais nous aurons, plus tard dans l’année, l’occasion d’implémenter des arbres binaires en Python en utilisant un peu de programmation orientée objet.
Nous aurons aussi très prochainement l’occasion d’étudier des algorithmes permettant de travailler sur les arbres binaires.
Nous avons eu l’occasion d’étudier la structure d’une base de données relationnelle, nous allons maintenant apprendre à réaliser des requêtes, c’est-à-dire que nous allons apprendre à créer une base des données, créer des attributs, ajouter de données, modifier des données et enfin, nous allons surtout apprendre à interroger une base de données afin d’obtenir des informations.
Pour réaliser toutes ces requêtes, nous allons devoir apprendre un langage de requêtes : SQL (Structured Query Language). SQL est propre aux bases de données relationnelles, les autres types de bases de données utilisent d’autres langages pour effectuer des requêtes.
Pour créer une base de données et effectuer des requêtes sur cette dernière, nous allons utiliser le logiciel « DB Browser for SQLite » (il se stue dans APP22(W:)\SQLite_Browser_Portable ).
SQLite est un système de gestion de base de données relationnelle très répandu. Noter qu’il existe d’autres systèmes de gestion de base de données relationnelle comme MySQL ou PostgreSQL. Dans tous les cas, le langage de requête utilisé est le SQL (même si parfois on peut noter quelques petites différences). Ce qui sera vu ici avec SQLite pourra, à quelques petites modifications près, être utilisé avec, par exemple, MySQL.
Nous allons commencer par créer notre base de données :
À faire vous-même 1
Après avoir lancé le logiciel « DB Browser for SQLite », vous devriez obtenir ceci :
Cliquez sur Nouvelle base de données. Après avoir choisi un nom pour votre base de données (par exemple « db_livres.db »), vous devriez avoir la fenêtre suivante :
Cliquez alors sur Annuler
Notre base de données a été créée :
mais pour l’instant elle ne contient aucune table (aucune relation), pour créer une table, cliquez sur l’onglet « Exécuter le SQL ». On obtient alors :
Copiez-collez le texte ci-dessous dans la fenêtre « SQL 1 »
CREATE TABLE LIVRES
(id INT, titre TEXT, auteur TEXT, ann_publi INT, note INT);
Cliquez ensuite sur le petit triangle situé au-dessus de la fenêtre SQL 1 Exécuter (ou appuyez sur F5), vous devriez avoir ceci :
Comme indiqué dans la fenêtre, « Requête exécutée avec succès » !
Vous venez de créer votre première table.
Revenons sur cette première requête :
Le CREATE TABLE LIVRES ne devrait pas vous poser de problème : nous créons une nouvelle table nommée « LIVRES ».
La suite est à peine plus complexe :
nous créons ensuite les attributs :
id
titre
auteur
ann_pulbi
note
Nous avons pour chaque attribut précisé son domaine : id : entier (INT), titre : chaîne de caractères (TEXT), auteur : chaîne de caractères, ann_publi : entier et note : entier
L’attribut « id » va jouer ici le rôle de clé primaire. On peut aussi, par souci de sécurité (afin d’éviter que l’on utilise 2 fois la même valeur pour l’attribut « id »), modifier l’instruction SQL vue ci-dessus, afin de préciser que l’attribut « id » est bien notre clé primaire :
CREATE TABLE LIVRES
(id INT, titre TEXT, auteur TEXT, ann_publi INT, note INT, PRIMARY KEY (id));
Notre système de gestion de base de données nous avertira si l’on tente d’attribuer 2 fois la même valeur à l’attribut »id ».
Nous allons maintenant ajouter des données :
À faire vous-même 2
Toujours dans l’onglet « Exécuter le SQL », après avoir effacé la fenêtre SQL 1, copiez-collez dans cette même fenêtre la requête ci-dessous :
INSERT INTO LIVRES(id,titre,auteur,ann_publi,note)
VALUES
(1,'1984','Orwell',1949,10),
(2,'Dune','Herbert',1965,8),
(3,'Fondation','Asimov',1951,9),
(4,'Le meilleur des mondes','Huxley',1931,7),
(5,'Fahrenheit 451','Bradbury',1953,7),
(6,'Ubik','K.Dick',1969,9),
(7,'Chroniques martiennes','Bradbury',1950,8),
(8,'La nuit des temps','Barjavel',1968,7),
(9,'Blade Runner','K.Dick',1968,8),
(10,'Les Robots','Asimov',1950,9),
(11,'La Planète des singes','Boulle',1963,8),
(12,'Ravage','Barjavel',1943,8),
(13,'Le Maître du Haut Château','K.Dick',1962,8),
(14,'Le monde des Ā','Van Vogt',1945,7),
(15,'La Fin de l’éternité','Asimov',1955,8),
(16,'De la Terre à la Lune','Verne',1865,10);
Ici aussi, aucun problème, la requête a bien été exécutée :
La table LIVRES contient bien les données souhaitées (onglet « Parcourir les données ») :
Nous allons apprendre à effectuer des requêtes d’interrogation sur la base de données que nous venons de créer.
Toutes les requêtes se feront dans la fenêtre SQL 1 de l’onglet « Exécuter le SQL »
À faire vous-même 3
Saisissez la requête SQL suivante :
SELECT id, titre, auteur, ann_publi, note
FROM LIVRES
puis appuyez sur le triangle (ou la touche F5)
Après un temps plus ou moins long, vous devriez voir s’afficher ceci :
Comme vous pouvez le constater, notre requête SQL a permis d’afficher tous les livres. Nous avons ici 2 mots clés du langage SQL SELECTqui permet de sélectionner les attributs qui devront être « affichés » (je mets « affichés » entre guillemets, car le but d’une requête sql n’est pas forcément d’afficher les données) et FROMqui indique la table qui doit être utilisée.
Il est évidemment possible d’afficher seulement certains attributs (ou même un seul) :
À faire vous-même 4
Saisissez la requête SQL suivante :
SELECT titre, auteur
FROM LIVRES
Vérifiez que vous obtenez bien uniquement les titres et les auteurs des livres
À faire vous-même 5
Écrivez et testez une requête permettant d’obtenir uniquement les titres des livres.
N.B. Si vous désirez sélectionner tous les attributs, vous pouvez écrire :
SELECT *
FROM LIVRES
à la place de :
SELECT id, titre, auteur, ann_publi, note
FROM LIVRES
Pour l’instant nos requêtes affichent tous les livres, il est possible d’utiliser la clause WHEREafin d’imposer une (ou des) condition(s) permettant de sélectionner uniquement certaines lignes.
La condition doit suivre le mot-clé WHERE:
À faire vous-même 6
Saisissez et testez la requête SQL suivante :
SELECT titre, ann_publi
FROM LIVRES
WHERE auteur='Asimov'
Vérifiez que vous obtenez bien uniquement les livres écrits par Isaac Asimov.
À faire vous-même 7
Écrivez et testez une requête permettant d’obtenir uniquement les titres des livres écrits par Philip K.Dick.
Il est possible de combiner les conditions à l’aide d’un ORou d’un AND
À faire vous-même 8
Saisissez et testez la requête SQL suivante :
SELECT titre, ann_publi
FROM LIVRES
WHERE auteur='Asimov' AND ann_publi>1953
Vérifiez que nous obtenons bien le livre écrit par Asimov publié après 1953 (comme vous l’avez sans doute remarqué, il est possible d’utiliser les opérateurs d’inégalités).
À faire vous-même 9
D’après vous, quel est le résultat de cette requête :
SELECT titre
FROM LIVRES
WHERE auteur='K.Dick' OR note>=8
À faire vous-même 10
Écrire une requête permettant d’obtenir les titres des livres publiés après 1945 qui ont une note supérieure ou égale à 9.
Il est aussi possible de rajouter la clause SQL ORDER BY afin d’obtenir les résultats classés dans un ordre précis.
À faire vous-même 11
Saisissez et testez la requête SQL suivante :
SELECT titre
FROM LIVRES
WHERE auteur='K.Dick' ORDER BY ann_publi
Nous obtenons les livres de K.Dick classés du plus ancien ou plus récent.
Il est possible d’obtenir un classement en sens inverse à l’aide de la clause DESC
À faire vous-même 12
Saisissez et testez la requête SQL suivante :
SELECT titre
FROM LIVRES
WHERE auteur='K.Dick' ORDER BY ann_publi DESC
Nous obtenons les livres de K.Dick classés du plus récent au plus ancien.
À faire vous-même 13
Que se passe-t-il quand la clause ORDER BY porte sur un attribut de type TEXT ?
Vous pouvez constater qu’une requête du type :
SELECT auteur
FROM LIVRES
affiche plusieurs fois certains auteurs (les auteurs qui ont écrit plusieurs livres présents dans la base de données)
Il est possible d’éviter les doublons grâce à la clause DISTINCT
À faire vous-même 14
Saisissez et testez la requête SQL suivante :
SELECT DISTINCT auteur
FROM LIVRES
Nous avons vu précédemment qu’une base de données peut contenir plusieurs relations (plusieurs tables).
À faire vous-même 15
Créez une nouvelle base de données que vous nommerez par exemple db_livres_auteurs.db
À faire vous-même 16
Créez une table AUTEURS(id INT, nom TEXT, prenom TEXT, ann_naissance INT, langue_ecriture TEXT) à l’aide d’une requête SQL.
À faire vous-même 17
Créez une table LIVRES(id INT, titre TEXT, id_auteur INT, ann_publi INT, note INT) à l’aide d’une requête SQL.
À faire vous-même 18
Ajoutez des données à la table AUTEURS à l’aide de la requête SQL suivante :
Ajoutez des données à la table LIVRES à l’aide de la requête SQL suivante :
INSERT INTO LIVRES
(id,titre,id_auteur,ann_publi,note)
VALUES
(1,'1984',1,1949,10),
(2,'Dune',2,1965,8),
(3,'Fondation',3,1951,9),
(4,'Le meilleur des mondes',4,1931,7),
(5,'Fahrenheit 451',5,1953,7),
(6,'Ubik',6,1969,9),
(7,'Chroniques martiennes',5,1950,8),
(8,'La nuit des temps',7,1968,7),
(9,'Blade Runner',6,1968,8),
(10,'Les Robots',3,1950,9),
(11,'La Planète des singes',8,1963,8),
(12,'Ravage',7,1943,8),
(13,'Le Maître du Haut Château',6,1962,8),
(14,'Le monde des Ā',9,1945,7),
(15,'La Fin de l’éternité',3,1955,8),
(16,'De la Terre à la Lune',10,1865,10);
Nous avons 2 tables, grâce aux jointures nous allons pouvoir associer ces 2 tables dans une même requête.
En général, les jointures consistent à associer des lignes de 2 tables. Elles permettent d’établir un lien entre 2 tables. Qui dit lien entre 2 tables dit souvent clef étrangère et clef primaire.
Dans notre exemple l’attribut « id_auteur » de la tables LIVRES est bien une clé étrangère puisque cet attribut correspond à l’attribut « id » de la table « AUTEURS« .
À noter qu’il est possible de préciser au moment de la création d’une table qu’un attribut jouera le rôle de clé étrangère. Dans notre exemple, à la place d’écrire :
CREATE TABLE LIVRES
(id INT, titre TEXT, id_auteur INT, ann_publi INT, note INT, PRIMARY KEY (id));
grâce à cette précision, sqlite sera capable de détecter les anomalies au niveau de clé étrangère : essayez par exemple d’ajouter un livre à la table LIVRES avec l’attribut « id_auteur » égal à 11 !
Passons maintenant aux jointures :
À faire vous-même 20
Saisissez et testez la requête SQL suivante :
SELECT *
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
Le « FROM LIVRES INNER JOIN AUTEURS » permet de créer une jointure entre les tables LIVRES et AUTEURS (« rassembler » les tables LIVRES et AUTEURS en une seule grande table). Le « ON LIVRES.id_auteur = AUTEURS.id » signifie qu’une ligne quelconque A de la table LIVRES devra être fusionnée avec la ligne B de la table AUTEURS à condition que l’attribut id de la ligne A soit égal à l’attribut id_auteur de la ligne B.
Par exemple, la ligne 1 (id=1) de la table LIVRES (que l’on nommera dans la suite ligne A) sera fusionnée avec la ligne 1 (id=1) de la table AUTEURS (que l’on nommera dans la suite B) car l’attribut id_auteur de la ligne A est égal à 1 et l’attribut id de la ligne B est aussi égal à 1.
Autre exemple, la ligne 1 (id=1) de la table LIVRES (que l’on nommera dans la suite ligne A) ne sera pas fusionnée avec la ligne 2 (id=2) de la table AUTEURS (que l’on nommera dans la suite B’) car l’attribut id_auteur de la ligne A est égal à 1 alors que l’attribut id de la ligne B’ est égal à 2.
Cette notion de jointure n’est pas évidente, prenez votre temps pour bien réfléchir et surtout n’hésitez pas à poser des questions.
À faire vous-même 21
Saisissez et testez la requête SQL suivante :
SELECT *
FROM AUTEURS
INNER JOIN LIVRES ON LIVRES.id_auteur = AUTEURS.id
Comme vous pouvez le constater, le résultat est différent, cette fois-ci ce sont les lignes de la table LIVRES qui viennent se greffer sur la table AUTEURS.
Dans le cas d’une jointure, il est tout à fait possible de sélectionner certains attributs et pas d’autres :
À faire vous-même 22
Saisissez et testez la requête SQL suivante :
SELECT nom, prenom, titre
FROM AUTEURS
INNER JOIN LIVRES ON LIVRES.id_auteur = AUTEURS.id
À faire vous-même 23
Saisissez et testez la requête SQL suivante :
SELECT titre,nom, prenom
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
Si un même nom d’attribut est présent dans les 2 tables (par exemple ici l’attribut id), il est nécessaire d’ajouter le nom de la table devant afin de pouvoir les distinguer (AUTEURS.id et LIVRES.id)
À faire vous-même 24
Saisissez et testez la requête SQL suivante :
SELECT titre,AUTEURS.id,nom, prenom
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
Il est possible d’utiliser la clause WHERE dans le cas d’une jointure :
À faire vous-même 25
Saisissez et testez la requête SQL suivante :
SELECT titre,nom, prenom
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
WHERE ann_publi>1950
Enfin, pour terminer avec les jointures, vous devez savoir que nous avons abordé la jointure la plus simple (INNER JOIN). Il existe des jointures plus complexes (CROSS JOIN, LEFT JOIN, RIGHT JOIN), ces autres jointures ne seront pas abordées ici.
Nous en avons terminé avec les requêtes d’interrogation, intéressons-nous maintenant aux requêtes de mise à jour (INSERT, UPDATE, DELETE).
Nous allons repartir avec une base de données qui contient une seule table :
À faire vous-même 26
Créez une nouvelle base de données que vous nommerez par exemple db_livres2.db
À faire vous-même 27
Créez une table LIVRES à l’aide de la requête SQL suivante :
CREATE TABLE LIVRES
(id INT, titre TEXT, auteur TEXT, ann_publi INT, note INT, PRIMARY KEY (id));
À faire vous-même 28
Ajoutez des données à la table LIVRES à l’aide de la requête SQL suivante :
INSERT INTO LIVRES
(id,titre,auteur,ann_publi,note)
VALUES
(1,'1984','Orwell',1949,10),
(2,'Dune','Herbert',1965,8),
(3,'Fondation','Asimov',1951,9),
(4,'Le meilleur des mondes','Huxley',1931,7),
(5,'Fahrenheit 451','Bradbury',1953,7),
(6,'Ubik','K.Dick',1969,9),
(7,'Chroniques martiennes','Bradbury',1950,8),
(8,'La nuit des temps','Barjavel',1968,7),
(9,'Blade Runner','K.Dick',1968,8),
(10,'Les Robots','Asimov',1950,9),
(11,'La Planète des singes','Boulle',1963,8),
(12,'Ravage','Barjavel',1943,8),
(13,'Le Maître du Haut Château','K.Dick',1962,8),
(14,'Le monde des Ā','Van Vogt',1945,7),
(15,'La Fin de l’éternité','Asimov',1955,8),
(16,'De la Terre à la Lune','Verne',1865,10);
Nous avons déjà eu l’occasion de voir la requête permettant d’ajouter une entrée (utilisation d’INSERT)
À faire vous-même 29
Que va faire cette requête ? Vérifiez votre réponse en l’exécutant et en faisant une requête « SELECT * FROM LIVRES« .
INSERT INTO LIVRES
(id,titre,auteur,ann_publi,note)
VALUES
(17,'Hypérion','Simmons',1989,8);
À faire vous-même 30
Écrivez et testez une requête permettant d’ajouter le livre de votre choix à la table LIVRES.
« UPDATE » va permettre de modifier une ou des entrées. Nous utiliserons « WHERE« , comme dans le cas d’un « SELECT« , pour spécifier les entrées à modifier.
Voici un exemple de modification :
À faire vous-même 31
Que va faire cette requête ? Vérifiez votre réponse en l’exécutant et en faisant une requête « SELECT * FROM LIVRES« .
UPDATE LIVRES
SET note=7
WHERE titre = 'Hypérion'
À faire vous-même 32
Écrivez une requête permettant d’attribuer la note de 10 à tous les livres écrits par Asimov publiés après 1950. Testez cette requête.
« DELETE » est utilisée pour effectuer la suppression d’une (ou de plusieurs) entrée(s). Ici aussi c’est le « WHERE » qui permettra de sélectionner les entrées à supprimer.
À faire vous-même 33
Que va faire cette requête ? Vérifiez votre réponse en l’exécutant et en faisant une requête « SELECT * FROM LIVRES« .
DELETE FROM LIVRES
WHERE titre='Hypérion'
À faire vous-même 34
Écrivez une requête permettant de supprimer les livres publiés avant 1945. Testez cette requête.
De nombreux algorithmes « classiques » manipulent des structures de données plus complexes que des simples nombres (nous aurons l’occasion d’en voir plusieurs cette année). Nous allons ici voir quelques-unes de ces structures de données. Nous allons commencer par des types de structures relativement simples : les listes, les piles et les files. Ces trois types de structures sont qualifiés de linéaires.
Les listes
Une liste est une structure de données permettant de regrouper des données. Une liste L est composée de 2 parties : sa tête (souvent noté car), qui correspond au dernier élément ajouté à la liste, et sa queue (souvent noté cdr) qui correspond au reste de la liste.
Le langage de programmation Lisp (inventé par John McCarthy en 1958) a été un des premiers langages de programmation à introduire cette notion de liste (Lisp signifie « list processing »). Voici les opérations qui peuvent être effectuées sur une liste :
créer une liste vide (L=vide() on a créé une liste L vide)
tester si une liste est vide (estVide(L) renvoie vrai si la liste L est vide)
ajouter un élément en tête de liste (ajouteEnTete (x,L) avec L une liste et x l’élément à ajouter)
supprimer la tête x d’une liste L et renvoyer cette tête x (supprEnTete(L))
Compter le nombre d’éléments présents dans une liste (compte(L) renvoie le nombre d’éléments présents dans la liste L)
La fonction cons permet d’obtenir une nouvelle liste à partir d’une liste et d’un élément (L1 = cons(x,L)). Il est possible « d’enchaîner » les cons et d’obtenir ce genre de structure : cons(x, cons(y, cons(z,L)))
Exemples :
Voici une série d’instructions (les instructions ci-dessous s’enchaînent):
L=vide() => on a créé une liste vide
estVide(L) => renvoie vrai
ajoutEnTete(3,L) => La liste L contient maintenant l’élément 3
estVide(L) => renvoie faux
ajoutEnTete(5,L) => la tête de la liste L correspond à 5, la queue contient l’élément 3
ajoutEnTete(8,L) => la tête de la liste L correspond à 8, la queue contient les éléments 3 et 5
t = supprEnTete(L) => la variable t vaut 8, la tête de L correspond à 5 et la queue contient l’élément 3
L1 = vide()
L2 = cons(8, cons(5, cons(3, L1))) => La tête de L2 correspond à 8 et la queue contient les éléments 3 et 5
À faire vous-même 1
Voici une série d’instructions (les instructions ci-dessous s’enchaînent), expliquez ce qui se passe à chacune des étapes :
On retrouve dans les piles une partie des propriétés vues sur les listes. Dans les piles, il est uniquement possible de manipuler le dernier élément introduit dans la pile. On prend souvent l’analogie avec une pile d’assiettes : dans une pile d’assiettes la seule assiette directement accessible et la dernière assiette qui a été déposée sur la pile.
Les piles sont basées sur le principe LIFO (Last In First Out : le dernier rentré sera le premier à sortir). On retrouve souvent ce principe LIFO en informatique.
Voici les opérations que l’on peut réaliser sur une pile :
on peut créer une pile
on peut savoir si une pile est vide (pile_vide?)
on peut empiler un nouvel élément sur la pile (push)
on peut récupérer l’élément au sommet de la pile tout en le supprimant. On dit que l’on dépile (pop)
on peut accéder à l’élément situé au sommet de la pile sans le supprimer de la pile (sommet)
on peut connaitre le nombre d’éléments présents dans la pile (taille)
Exemples :
Soit une pile P composée des éléments suivants : 12, 14, 8, 7, 19 et 22 (le sommet de la pile est 22) Pour chaque exemple ci-dessous on repart de la pile d’origine :
pop(P) renvoie 22 et la pile P est maintenant composée des éléments suivants : 12, 14, 8, 7 et 19 (le sommet de la pile est 19)
push(P,42) la pile P est maintenant composée des éléments suivants : 12, 14, 8, 7, 19, 22 et 42
sommet(P) renvoie 22, la pile P n’est pas modifiée
si on applique pop(P) 6 fois de suite, pile_vide?(P) renvoie vrai
Après avoir appliqué pop(P) une fois, taille(P) renvoie 5
À faire vous-même 2
Soit une pile P composée des éléments suivants : 15, 11, 32, 45 et 67 (le sommet de la pile est 67). Quel est l’effet de l’instruction pop(P)
Les files
Comme les piles, les files ont des points communs avec les listes. Différences majeures : dans une file on ajoute des éléments à une extrémité de la file et on supprime des éléments à l’autre extrémité. On prend souvent l’analogie de la file d’attente devant un magasin pour décrire une file de données.
Les files sont basées sur le principe FIFO (First In First Out : le premier qui est rentré sera le premier à sortir. Ici aussi, on retrouve souvent ce principe FIFO en informatique.
Voici les opérations que l’on peut réaliser sur une file :
on peut savoir si une file est vide (file_vide?)
on peut ajouter un nouvel élément à la file (ajout)
on peut récupérer l’élément situé en bout de file tout en le supprimant (retire)
on peut accéder à l’élément situé en bout de file sans le supprimer de la file (premier)
on peut connaitre le nombre d’éléments présents dans la file (taille)
Exemples :
Soit une file F composée des éléments suivants : 12, 14, 8, 7, 19 et 22 (le premier élément rentré dans la file est 22 ; le dernier élément rentré dans la file est 12). Pour chaque exemple ci-dessous on repart de la file d’origine :
ajout(F,42) la file F est maintenant composée des éléments suivants : 42, 12, 14, 8, 7, 19 et 22 (le premier élément rentré dans la file est 22 ; le dernier élément rentré dans la file est 42)
retire(F) la file F est maintenant composée des éléments suivants : 12, 14, 8, 7, et 19 (le premier élément rentré dans la file est 19 ; le dernier élément rentré dans la file est 12)
premier(F) renvoie 22, la file F n’est pas modifiée
si on applique retire(F) 6 fois de suite, file_vide?(F) renvoie vrai
Après avoir appliqué retire(F) une fois, taille(F) renvoie 5.
À faire vous-même 3
Soit une file F composée des éléments suivants : 1, 12, 24, 17, 21 et 72 (le premier élément rentré dans la file est 72 ; le dernier élément rentré dans la file est 1). Quel est l’effet de l’instruction ajout(F,25)
Types abstraits et représentation concrète des données
Nous avons évoqué ci-dessus la manipulation des types de données (liste, pile et file) par des algorithmes, mais, au-delà de la beauté intellectuelle de réfléchir sur ces algorithmes, le but de l’opération est souvent, à un moment ou un autre, de « traduire » ces algorithmes dans un langage compréhensible pour un ordinateur (Python, Java, C,…). On dit alors que l’on implémente un algorithme. Il est donc aussi nécessaire d’implémenter les types de données comme les listes, les piles ou les files afin qu’ils soient utilisables par les ordinateurs. Les listes, les piles ou les files sont des « vues de l’esprit » présent uniquement dans la tête des informaticiens, on dit que ce sont des types abstraits de données (ou plus simplement des types abstraits). L’implémentation de ces types abstrait, afin qu’ils soient utilisables par une machine, est loin d’être une chose triviale. L’implémentation d’un type de données dépend du langage de programmation. Il faut, quel que soit le langage utilisé, que le programmeur retrouve les fonctions qui ont été définies pour le type abstrait (pour les listes, les piles et les files cela correspond aux fonctions définies ci-dessus). Certains types abstraits ne sont pas forcément implémentés dans un langage donné, si le programmeur veut utiliser ce type abstrait, il faudra qu’il le programme par lui-même en utilisant les « outils » fournis par son langage de programmation.
Pour implémenter les listes (ou les piles et les files), beaucoup de langages de programmation utilisent 2 structures : les tableaux et les listes chaînées.
Un tableau est une suite contiguë de cases mémoires (les adresses des cases mémoire se suivent) :
Le système réserve une plage d’adresse mémoire afin de stocker des éléments.
La taille d’un tableau est fixe : une fois que l’on a défini le nombre d’éléments que le tableau peut accueillir, il n’est pas possible modifier sa taille. Si l’on veut insérer une donnée, on doit créer un nouveau tableau plus grand et déplacer les éléments du premier tableau vers le second tout en ajoutant la donnée au bon endroit !
Dans certains langages de programmation, on trouve une version « évoluée » des tableaux : les tableaux dynamiques. Les tableaux dynamiques ont une taille qui peut varier. Il est donc relativement simple d’insérer des éléments dans le tableau. Ce type de tableaux permet d’implémenter facilement le type abstrait liste (de même pour les piles et les files)
À noter que les « listes Python » (listes Python) sont des tableaux dynamiques. Attention de ne pas confondre avec le type abstrait liste défini ci-dessus, ce sont de « faux amis ».tableau dynamique
Autre type de structure que l’on rencontre souvent et qui permet d’implémenter les listes, les piles et les files : les listes chaînées.
Dans une liste chaînée, à chaque élément de la liste on associe 2 cases mémoire : la première case contient l’élément et la deuxième contient l’adresse mémoire de l’élément suivant.
Il est relativement facile d’insérer un élément dans une liste chaînée :
Il est aussi possible d’implémenter les types abstraits en utilisant des structures plus complexes que les tableaux et les listes chaînées. Par exemple, en Python, il est possible d’utiliser les tuples pour implémenter le type abstrait liste :
Présentation des d’algorithmes gloutons avec exemples et TD. cet article est une copie d’un article du site www.math93.com/ , vous pouvez le voir ici .
Résoudre un problème d’optimisation : les algorithmes gloutons
Le problème du rendu de monnaie.
Le TD sur les algorithmes gloutons et le rendu de monnaie.
1. Présentation de la notion d’algorithme glouton
1.1. Les problèmes d’optimisation
L’optimisation est une branche des mathématiques cherchant à modéliser, à analyser et à résoudre les problèmes qui consistent à minimiser ou maximiser une fonction sur un ensemble.
Les problèmes d’optimisation classiques sont par exemple :
la répartition optimale de tâches suivant des critères précis (emploi du temps avec plusieurs contraintes) ;
le problème du rendu de monnaie ;
la recherche d’un plus court chemin dans un graphe ;
le problème du voyageur de commerce.
1.2. Résoudre un problème d’optimisation : les algorithmes gloutons
De nombreuses techniques informatiques sont susceptibles d’apporter une solution exacte ou approchée à ces problèmes.
Recherche de toutes les solutions La technique la plus basique pour résoudre ce type de problème d’optimisation consiste à énumérer de façon exhaustive toutes les solutions possibles, puis à choisir la meilleure. Cette approche par force brute, impose souvent un coût en temps trop important pour être utilisée.
Les algorithmes gloutons Un algorithme glouton (greedy algorithm) est un algorithme qui suit le principe de faire, étape par étape, un choix optimum local. Au cours de la construction de la solution, l’algorithme résout une partie du problème puis se focalise ensuite sur le sous-problème restant à résoudre. La méthode gloutonne consiste à choisir des solutions locales optimales d’un problème dans le but d’obtenir une solution optimale globale au problème.
Le principal avantage des algorithmes gloutons est leur facilité de mise en œuvre.
Le principal défaut est qu’il ne renvoie pas toujours la solution optimale nous le verrons.
Dans certaines situations dites canoniques, il arrive qu’ils renvoient non pas un optimum mais l’optimum d’un problème
2. Le problème du rendu de monnaie
Un achat dit en espèces se traduit par un échange de pièces et de billets. Dans la suite, les pièces désignent indifféremment les véritables pièces que les billets.
Supposons qu’un achat induise un rendu de 49 euros on considérant pour simplifier que les ‘pièces’ prennent les valeurs 1, 2, 5, 10, 20, 50, 100 euros. Quelles pièces peuvent être rendues ?
49=4×10+1×5+2×2
soit 7 pièces au total (Quatre pièces de 10 euros, 1 pièce de 5 euros et deux pièces de 2 euros.) ou 49=9×5+2×2 soit 11 pièces au total ou 49=9×5+4×1 soit 13 pièces au total ou 49=49×1
soit 49 pièces au total
Le problème du rendu de monnaie consiste à déterminer la solution avec le nombre minimal de pièces.
Rendre 49 euros avec un minimum de pièces est un problème d’optimisation. En pratique, tout individu met en œuvre un algorithme glouton.
Il choisit d’abord la plus grandeur valeur de monnaie, parmi 1, 2, 5, 10, contenue dans 49 euros. En l’occurrence, quatre fois une pièce de 10 euros.
La somme de 9 euros restant à rendre, il choisit une pièce de 5 euros,
Puis deux pièces de 2 euros.
Solution optimale et système canonique du rendu de monnaie
Cette stratégie gagnante pour la somme de 49 euros l’est-elle pour n’importe quelle somme à rendre ?
Un système canonique
On peut montrer que l’algorithme glouton du rendu de monnaie renvoie une solution optimale pour le système monétaire français {1,2,5,10,20,50,100}
Pour cette raison, un tel système de monnaie est qualifié de canonique.
Des systèmes non canoniques
D ’autres systèmes ne sont pas canoniques. L’algorithme glouton ne répond alors pas de manière optimale.
Par exemple, avec le système {1,3,6,12,24,30},l’algorithme glouton répond en proposant le rendu : 49=30+12+6+1 soit 4 pièces alors que la solution optimale est 49=2×24+1
soit 3 pièces.
3. Le TD sur les algorithmes gloutons et le rendu de monnaie
Prérequis au TD
Python : liste, parcours de listes.
On cherche à implémenter un algorithme glouton de rendu de monnaie en ne considérant que des valeurs entières des pièces du système. Par ailleurs, la plus petite pièce du système sera toujours 1, on est ainsi certain de pouvoir rendre la monnaie quelque soit la somme choisie.
Fonctionnement de l’algorithme glouton du rendu de monnaie
On choisit un système de monnaies, par exemple systeme=[1,2,5,10,20,50,100]
On choisit une valeur, par exemple valeur=49 euros .
On choisit la plus grande ‘pièce’ du système inférieure à la valeur et on l’ajoute à la liste des pièces à rendre.
On calcule le reste à rendre et on recommence jusqu’à obtenir un reste à rendre nul.
Exercice 1
Écrire une une fonction python qui reçoit deux arguments – la somme à rendre et le système de monnaie – et qui renvoie la liste des pièces choisies par l’algorithme glouton.
Tester votre fonction avec les valeurs et les systèmes proposés dans les exemples du cours ci-dessus.
Inventez un système non canonique différent de celui de l’exemple (mais toujours de valeur minimale 1) et trouver un exemple qui le prouve. Votre fonction devra donc donner une solution mais qui n’est pas optimale.
Complément : créer un programme (ou une autre fonction) qui va afficher toutes les informations suivantes : 49=4×10+1×5+2×2 Soit 7 pièces au total C’est à dire : Quatre pièces de 10 euros, 1 pièce de 5 euros et deux pièces de 2 euros.
Aide pour l’exercice 1:
Etape 1
Définissons le système de pièces à l’aide d’un tableau nommé systeme constitué des valeurs des pièces classées par valeurs croissantes (de plus petite pièce 1).
On définit aussi une valeur à tester, les 49 euros de l’exemple ci-dessus, dans la variable valeur.
Ainsi que l’indice i de la plus grande des pièces de systeme.
# valeurs des pièces du système choisi
systeme = [1,2,5,10,20,50,100]
# valeur à tester (par exemple 49 euros)
valeur=49
# indice de la première pièce à comparer à la somme à rendre
i = len(systeme) - 1
Etape 2 : Fonctionnement de l’algorithme
On cherche à déterminer les pièces à rendre pour la variable valeur.
Initialisations
La somme à rendre à rendre est initialement stockée dans la variable somme_a_rendre. On l’initialise donc à valeur.
liste_pieces, la liste des pièces à rendre est initialisée à une liste vide
i = len(systeme) - 1 : indice de la première pièce à comparer à la somme à rendre
On boucle tant que somme_a_rendre > 0
La variable piece prend la valeur de la pièce de systeme d’indice i
Si somme_a_rendre < piece
Alors i pend la valeur i-1
Sinon
alors on ajoute la piece à la liste des pièces à rendre liste_pieces
on enlève la valeur de piece de somme_a_rendre
On renvoie la liste : liste_pieces
Exercice 2
On cherche maintenant à généraliser notre algorithme avec le système de pièces et de billets utilisées en Europe et des valeurs décimales.
On va donc considérer un système composé de pièces et de billets :
Les billets (en euros) : 5 – 10 – 20 – 50 – 100 – 200 – 500.
Modifier donc votre programme afin qu’il affiche le nombre les pièces à rendre et les billets.
Tester les avec plusieurs exemples.
Et si il n’y avait ni billet de 5, ni billet de 10 euros. Montrer avec un exemple bien choisi que la solution donnée par l’algorithme n’est pas optimale
Exercice 3 – Une pièce de 7 euros
On peut se demander pourquoi il n’y a pas de pièce de 7 euros par exemple.
En fait c’est parce que si tel était le cas, l’algorithme glouton de rendu de monnaie ne serait plus optimal.
Tester votre algorithme en ajoutant une pièce de 7 euros dans le système.
Trouver un exemple qui renvoie une solution qui n’est pas optimale.
Introduction L’algorithme des k plus proches voisins appartient à la famille des algorithmes d’apprentissage automatique (machine learning). L’idée d’apprentissage automatique ne date pas d’hier, puisque le terme de machine learning a été utilisé pour la première fois par l’informaticien américain Arthur Samuel en 1959. Les algorithmes d’apprentissage automatique ont connu un fort regain d’intérêt au début des années 2000 notamment grâce à la quantité de données disponibles sur internet. L’algorithme des k plus proches voisins est un algorithme d’apprentissage supervisé, il est nécessaire d’avoir des données labellisées. À partir d’un ensemble E de données labellisées, il sera possible de classer (déterminer le label) d’une nouvelle donnée (donnée n’appartenant pas à E). À noter qu’il est aussi possible d’utiliser l’algorithme des k plus proches voisins à des fins de régression (on cherche à déterminer une valeur à la place d’une classe), mais cet aspect des choses ne sera pas abordé ici. L’algorithme des k plus proches voisins est une bonne introduction aux principes des algorithmes d’apprentissage automatique, il est en effet relativement simple à appréhender (l’explication donnée aux élèves peut être très visuelle). Cette première approche des algorithmes d’apprentissage peut aussi amener les élèves à réfléchir sur l’utilisation de leurs données personnelles (même si ce sujet a déjà abordé auparavant) : de nombreuses sociétés (exemple les GAFAM) utilisent les données concernant leurs utilisateurs afin de ”nourrir” des algorithmes de machine learning qui permettront à ces sociétés d’en savoir toujours plus sur nous et ainsi de mieux cerné nos ”besoins” en termes de consommation.
Principe de l’algorithme L’algorithme de k plus proches voisins ne nécessite pas de phase d’apprentissage à proprement parler, il faut juste stocker le jeu de données d’apprentissage. Soit un ensemble E contenant n données labellisées : E = {(yi , x⃗i)} avec i compris entre 1 et n, où yi correspond à la classe (le label) de la donnée i et où le vecteur x⃗i de dimension p (x⃗i = (x1i , x2i, …, xpi)) représente les variables prédictrices de la donnée i. Soit une donnée u qui n’appartient pas à E et qui ne possède pas de label (u est uniquement caractérisée par un vecteur x⃗u de dimension p). Soit d une fonction qui renvoie la distance entre la donnée u et une donnée quelconque appartenant à E. Soit un entier k inférieur ou égal à n. Voici le principe de l’algorithme de k plus proches voisins : ▷ On calcule les distances entre la donnée u et chaque donnée appartenant à E à l’aide de la fonction d ▷ On retient les k données du jeu de données E les plus proches de u ▷ On attribue à u la classe qui est la plus fréquente parmi les k données les plus proches.
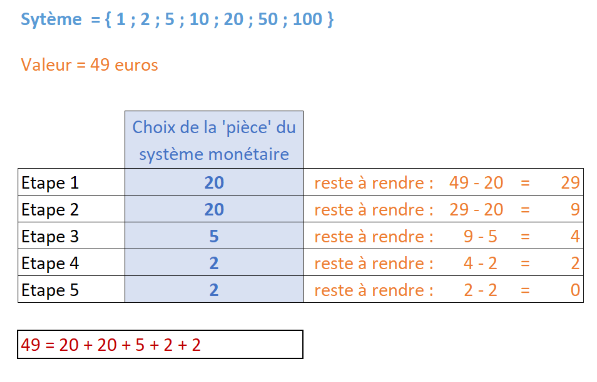
Étude d’un exemple 3.1. Les données Nous avons choisi ici de nous baser sur le jeu de données ”iris de Fisher” (il existe de nombreuses autres possibilités). Ce jeu de données est composé de 50 entrées, pour chaque entrée nous avons : ▷ la longueur des sépales (en cm) ▷ la largeur des sépales (en cm) ▷ la longueur des pétales (en cm) ▷ la largeur des pétales (en cm) ▷ l’espèce d’iris : Iris setosa, Iris virginica ou Iris versicolor (label) Il est possible de télécharger ces données au format csv, par exemple sur le site GitHub Gist ou en le téléchargeant ici Une fois ces données téléchargées, Il est nécessaire de les modifier à l’aide d’un tableur : ▷ dans un souci de simplification, nous avons choisi de travailler uniquement sur la taille des pétales, nous allons donc supprimer les colonnes ”sepal_length” et ”sepal_width” ▷ il est nécessaire d’encoder les espèces avec des chiffres : 0 pour Iris setosa, 1 pour Iris virginica et 2 pour Iris versicolor (ce processus d’encodage des données textuelles est relativement classique en apprentissage automatique). 3.2. Bibliothèques Python utilisées Nous allons utiliser 3 bibliothèques Python : ▷ Pandas [3] qui va nous permettre d’importer les données issues du fichier csv ▷ Matplotlib [4] qui va nous permettre de visualiser les données (tracer des graphiques) ▷ Scikit-learn [5] qui propose une implémentation de l’algorithme des k plus proches voisins. Ces bibliothèques sont facilement installables notamment en utilisant la distribution Anaconda (ou Miniconda). 3.3. Première visualisation des données Une fois le fichier csv modifié, il est possible d’écrire un programme permettant de visualiser les données sous forme de graphique (abscisse : ”petal_length”, ordonnée : ”petal_width”) :
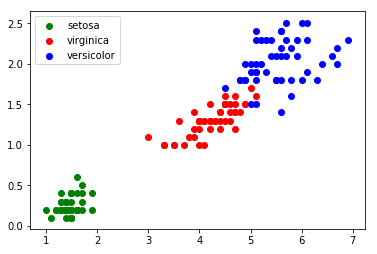
3.4. Utilisation de l’algorithme des k plus proches voisins Le graphique ci-dessus (figure 1) montre que les 3 classes (Iris setosa, Iris virginica et Iris versicolor) sont relativement bien séparées. On peut alors ajouter une donnée non labellisée n’appartenant pas à l’ensemble d’origine (voir figure 2) :
FIGURE 2 – Ajout d’une donnée non labellisée
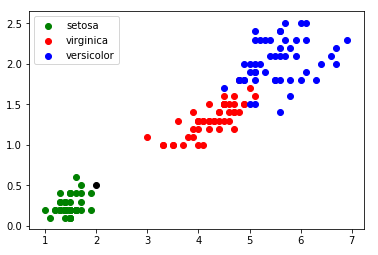
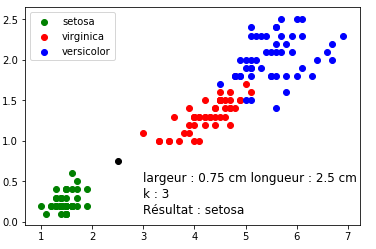
Dans l’exemple ci-dessus (figure 2) les élèves n’auront aucune difficulté à déterminer l’espèce de l’iris qui a été ajouté au jeu de données. Dans certains cas (exemple : largeur pétale = 0,75 cm ; longueur pétale = 2,5 cm) il est un peu plus difficile de se prononcer ”au premier coup d’oeil” (voir figure 3) :
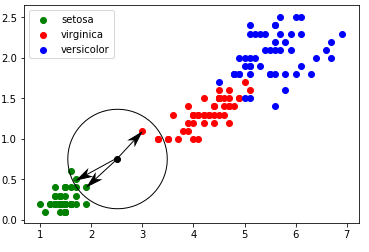
FIGURE 3 – Cas plus difficile…
À partir de l’exemple ci-dessus (voir figure 3), il est possible de demander aux élèves de proposer une méthode permettant de traiter ce genre de cas litigieux. L’enseignant peut, grâce à une série de ”questions-réponses”, amener doucement les élèves à la solution proposée par l’algorithme des k plus proches voisins : ▷ on calcule la distance entre notre point (largeur du pétale = 0,75 cm ; longueur du pétale = 2,5 cm) et chaque point issu du jeu de données ”iris” (à chaque fois c’est un calcul de distance entre 2 points tout ce qu’il y a de plus classique) ; ▷ on sélectionne uniquement les k distances les plus petites (les k plus proches voisins) ;
▷ parmi les k plus proches voisins, on détermine quelle est l’espèce majoritaire. On associe à notre ”iris mystère” cette ”espèce majoritaire parmi les k plus proches voisins”. Dans l’exemple évoqué ci-dessus (largeur pétale = 0,75 cm ; longueur pétale = 2,5 cm), pour k=3, nous obtenons graphiquement :
FIGURE 4 – 3 plus proches voisins dans le cas : largeur pétale = 0,75 cm ; longueur pétale = 2,5 cm
Un iris ayant une largeur de pétale égale à 0,75 cm et une longueur de pétale égale à 2,5 cm a une ”forte” probabilité (cette notion de probabilité d’obtenir un résultat correct grâce à cet algorithme, bien que très intéressante, pourra difficilement être abordée avec des élèves de première) d’appartenir à l’espèce setosa.
3.5. Utilisation de scikit-learn (à installer si absente de votre éditeur) La bibliothèque Python scikit-learn propose un grand nombre d’algorithmes lié à l’apprentissage automatique (c’est sans aucun doute la bibliothèque la plus utilisée en apprentissage automatique). Parmi tous ces algorithmes, scikit-learn propose l’algorithme des k plus proches voisins. Voici un programme Python permettant de résoudre le problème évoqué ci-dessus (largeur pétale = 0,75 cm ; longueur pétale = 2,5 cm) :
Nous obtenons le résultat suivant (voir figure 5) :
FIGURE 5 – 3 plus proches voisins à l’aide de scikit-learn dans le cas : largeur pétale = 0,75 cm ; longueur pétale = 2,5 cm
Il est ensuite possible de demander aux élèves de m le programme ci-dessus afin d’étudier les changements induits par la modification du paramètre k (notamment pour k=5) en gardant toujours les mêmes valeurs de largeur et de longueur (largeur pétale = 0,75 cm ; longueur pétale = 2,5 cm). Pour terminer, il est aussi possible de demander aux élèves de travailler avec d’autres valeurs de longueur et largeur.
Possibilité de projet Il est possible, dans le cadre d’un projet, de faire travailler les élèves sur un autre jeu de données, par exemple, ”Prédire les survivants du Titanic”. Le jeu de données peut être récupéré sur le site kaggle [6]. Le label est ”survivant” ou ”décédé”. Il sera nécessaire de retravailler les données comme nous l’avons fait pour le jeu de données ”Iris” (supprimer des colonnes, encodage…). Dans ce projet il sera possible de faire travailler les élèves sur des vecteurs d’entrée de dimension supérieure à 2 (le genre, l’âge, la classe occupée par le passager sur le bateau, …).
voici un lien vers le projet Titanic développé par Benoit Fourlegnie:
En utilisant les connaissances acquises jusqu’à présent, vous allez écrire un programme de gestion de répertoire téléphonique.
Cahier des charges
Ce programme devra proposer le menu suivant à l’utilisateur :
0-quitter 1-écrire dans le répertoire 2-rechercher dans le répertoire
3-mettre les numéros au format internationale Votre choix ?
Si le choix est 0 : Le programme sera stoppé.
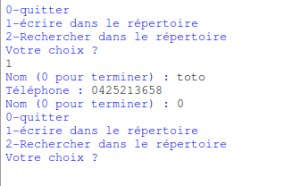
Si le choix est 1 :
L’utilisateur devra saisir un nom ou un prénom ou 0 s’il veut terminer la saisie ( » Nom (0 pour terminer) : « ….) :
L’utilisateur entre 0 => le programme devra le renvoyer vers le menu
L’utilisateur entre un nom ou prénom => le programme devra lui demander de saisir le numéro de téléphone correspondant au nom. Une fois le numéro saisi, le programme devra lui proposer d’entrer un nouveau nom (ou 0 pour terminer)…
exemple de saisie d’un utilisateur (toto)
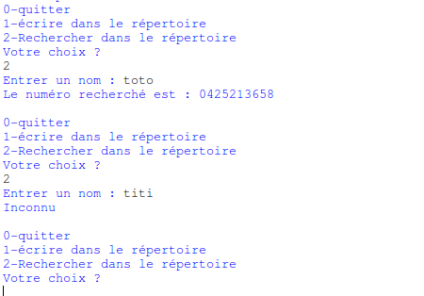
Si le choix est 2 :
L’utilisateur devra saisir le nom recherché ( » Entrer un nom : « ), ou le numéro de téléphone ( » Entrer un numéro : « ).
Si le nom recherché est présent dans le répertoire, le programme devra afficher » Le numéro recherché est : » suivi du numéro de téléphone correspondant au nom saisi.
Si le nom recherché est absent du répertoire, le programme devra afficher » Inconnu « .
…….
L’utilisateur est ensuite redirigé vers le menu principal.
recherche des utilisateurs (toto et titi)
Les noms, prénoms et numéros de téléphone devront être stockés dans un dictionnaire, le nom ou le prénom seront la clé et le numéro de téléphone sera la valeur associée à la clé.
Votre programme devra être composé au minimum de 3 fonctions : une fonction « menu », une fonction « lecture », et une fonction « ecriture »…….
Pensez à commenter votre programme, bien expliquer ce que doit faire vos fonctions et les différents tests que vous prévoyez.
Nous allons maintenant étudier un autre type abstrait de données : les dictionnaires aussi appelés tableau associatif.
On retrouve une structure qui ressemble, à première vue, beaucoup à un tableau (à chaque élément on associe un indice de position). Mais au lieu d’associer chaque élément à un indice de position, dans un dictionnaire, on associe chaque élément (on parle de valeur dans un dictionnaire) à une clef, on dit qu’un dictionnaire contient des couples clef:valeur (chaque clé est associée à une valeur). Exemples de couples clé:valeur => prenom:Kevin, nom:Durand, date-naissance:17-05-2005. prenom, nom et date sont des clés ; Kevin, Durand et 17-05-2005 sont des valeurs.
Voici les opérations que l’on peut effectuer sur le type abstrait dictionnaire :
ajout : on associe une nouvelle valeur à une nouvelle clé
modif : on modifie un couple clé:valeur en remplaçant la valeur courante par une autre valeur (la clé restant identique)
suppr : on supprime une clé (et donc la valeur qui lui est associée)
rech : on recherche une valeur à l’aide de la clé associée à cette valeur.
Exemples : Soit le dictionnaire D composé des couples clé:valeur suivants => prenom:Kevin, nom:Durand, date-naissance:17-05-2005. Pour chaque exemple ci-dessous on repart du dictionnaire d’origine :
ajout(D,tel:06060606) ; le dictionnaire D est maintenant composé des couples suivants : prenom:Kevin, nom:Durand, date-naissance:17-05-2005, tel:06060606
modif(D,nom:Dupont) ; le dictionnaire D est maintenant composé des couples suivants : prenom:Kevin, nom:Dupont, date-naissance:17-05-2005
suppr(D,date-naissance) ; le dictionnaire D est maintenant composé des couples suivants : prenom:Kevin, nom:Durand
rech(D,prenom) ; la fonction retourne Kevin
L’implémentation des dictionnaires dans les langages de programmation peut se faire à l’aide des tables de hachage. Les tables de hachages ainsi que les fonctions de hachages qui sont utilisées pour construire les tables de hachages, ne sont pas au programme de NSI. Cependant, l’utilisation des fonctions de hachages est omniprésente en informatique, il serait donc bon, pour votre « culture générale informatique », de connaitre le principe des fonctions de hachages. Voici un texte qui vous permettra de comprendre le principe des fonctions de hachages : c’est quoi le hachage . Pour avoir quelques idées sur le principe des tables de hachages, je vous recommande le visionnage de cette vidéo : wandida : les tables de hachage
Si vous avez visionné la vidéo de wandida, vous avez déjà compris que l’algorithme de recherche dans une table de hachage a une complexité O(1) (le temps de recherche ne dépend pas du nombre d’éléments présents dans la table de hachage), alors que la complexité de l’algorithme de recherche dans un tableau non trié est O(n). Comme l’implémentation des dictionnaires s’appuie sur les tables de hachage, on peut dire que l’algorithme de recherche d’un élément dans un dictionnaire a une complexité O(1) alors que l’algorithme de recherche d’un élément dans un tableau non trié a une complexité O(n).
Python propose une implémentation des dictionnaires, nous avons déjà étudié cette implémentation l’année dernière, n’hésitez pas à vous référer à la ressource proposée l’an passé : les dictionnaires en Python
Un administrateur de réseau pédagogique a créé des comptes utilisateurs à partir de données issues des bases du rectorat.
Le format du fichier qu’il a ainsi récupéré est au format csv. Les utilisateurs sont classés par ordre alphabétique.
L’administrateur, par soucis de simplification, souhaite disposer d’un fichier csv par classe, avec les utilisateurs de cette classe par ordre alphabétique.
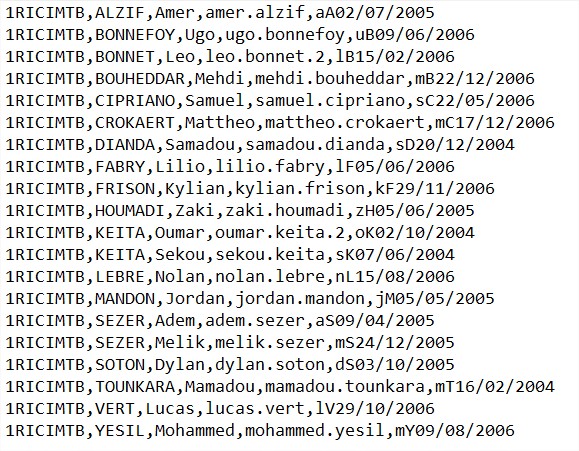
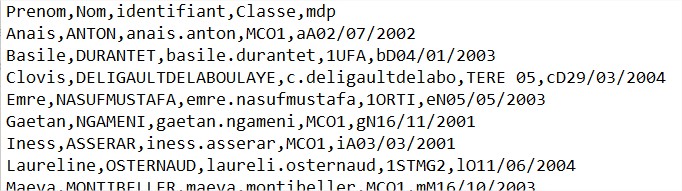
On vous demande de créer un programme python qui permettra ce traitement. Dans les fichiers de classe, on retrouvera les mêmes champs que dans le fichier original. Chaque fichier créé contiendra les noms des utilisateurs triés par ordre alphabétique.
Exemple à partir du fichier « utilisateurs_simple.csv » :
Le programme devra créer 3 fichiers : « 1RICIMTB.csv » – « 1TMA .csv » – « 1UFA.csv » contenant chacun les utilisateurs de la classe correspondante, classés dans l’ordre alphabétique.
Le fichier original est sous la forme suivante (image ci-dessous). Les champs sont différemment organisés et les noms d’utilisateurs ne sont pas classés dans l’ordre alphabétique. Il s’agira donc de les classer par ordre alphabétique dans les fichiers de classe…z
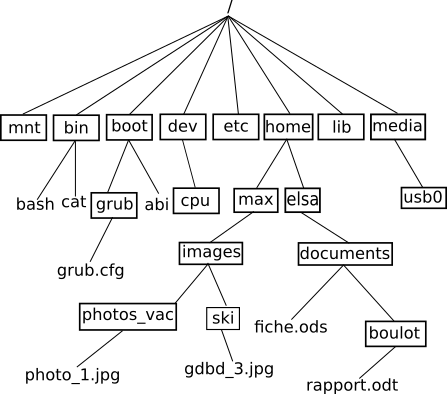 système de fichiers de type UNIX
système de fichiers de type UNIX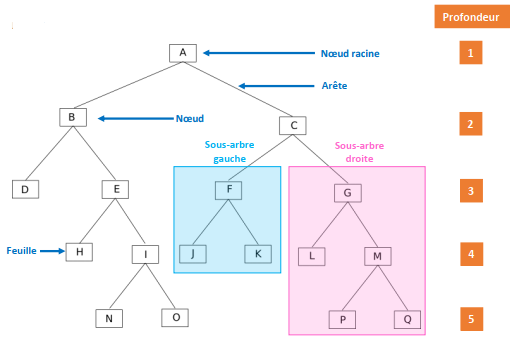

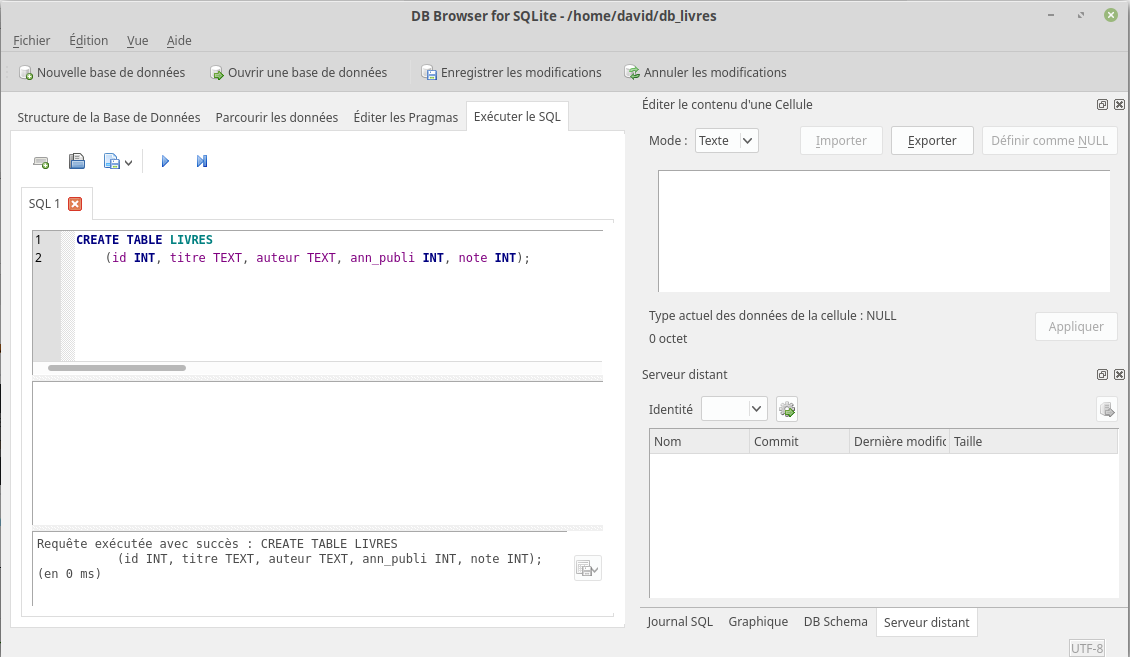
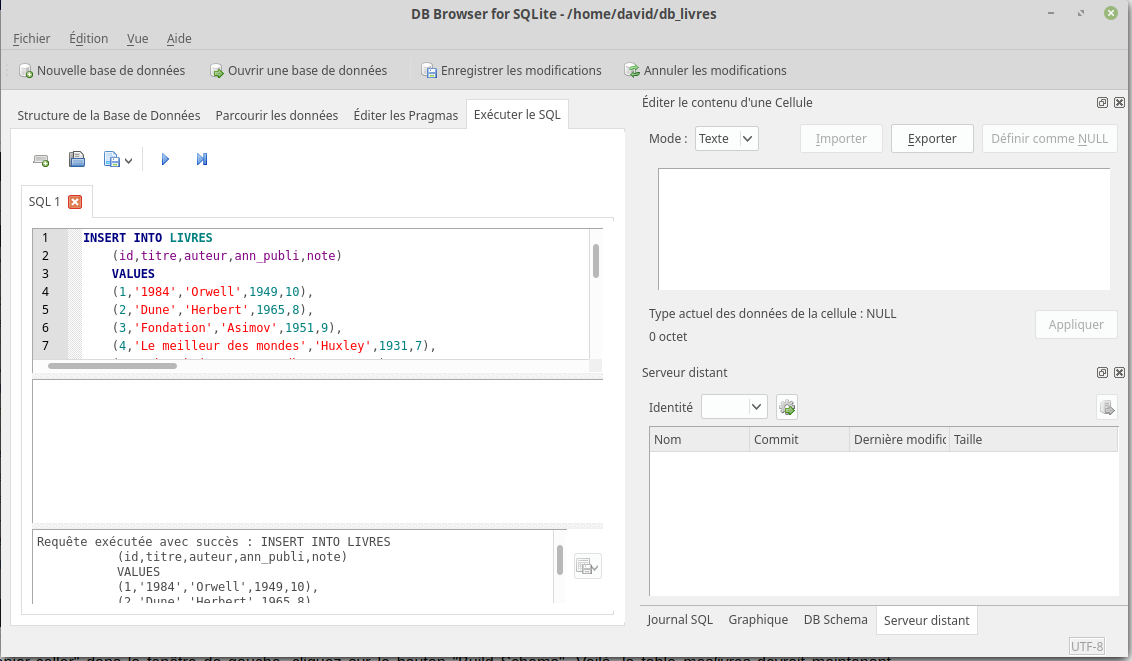
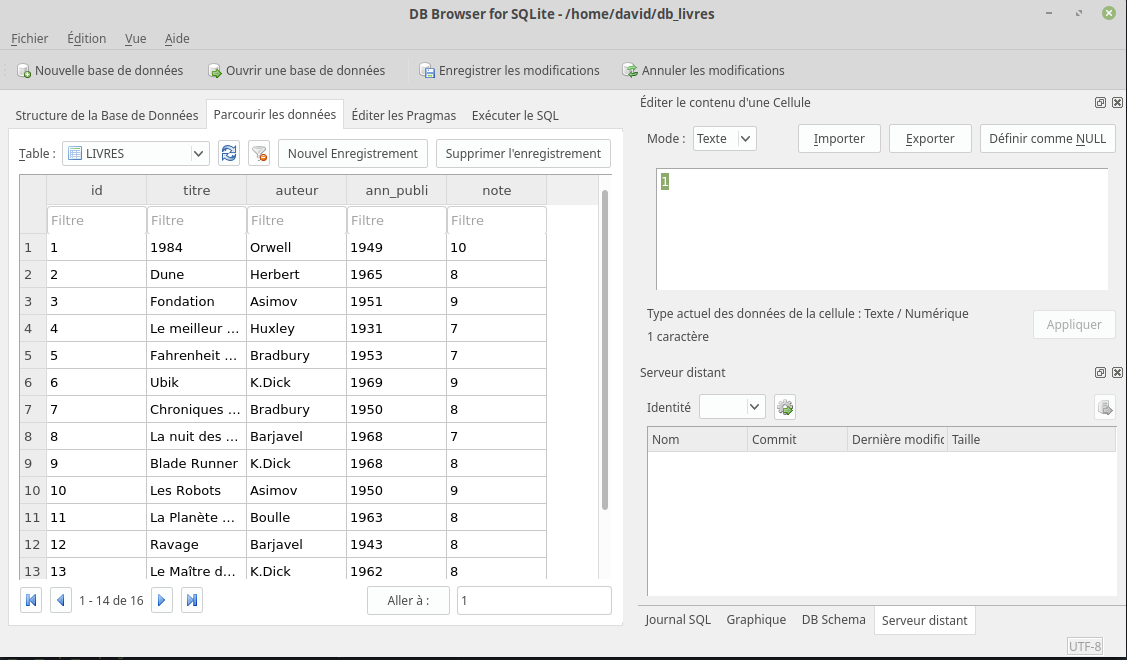
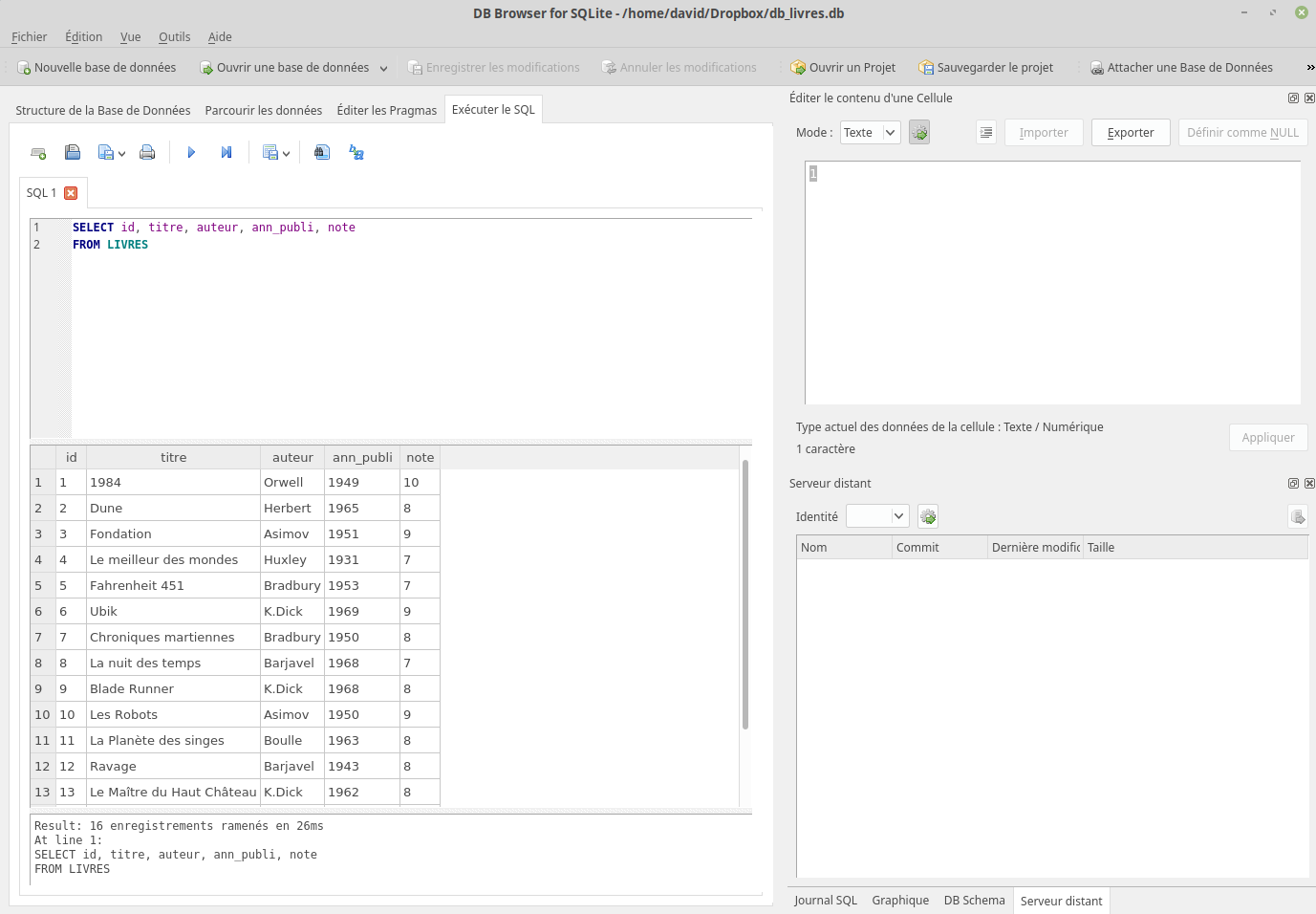

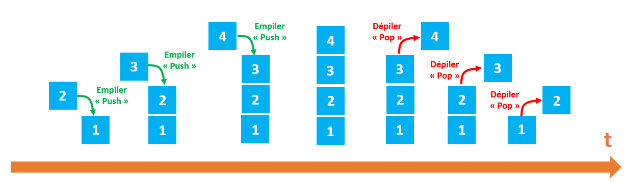
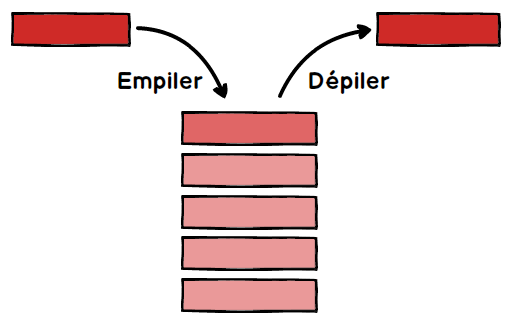
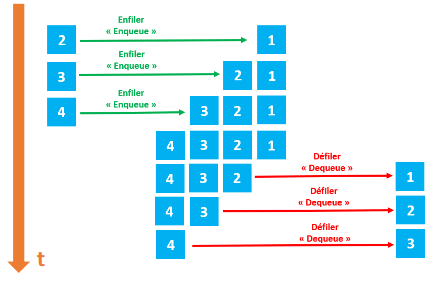
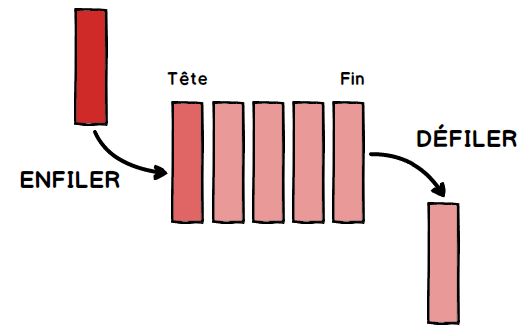
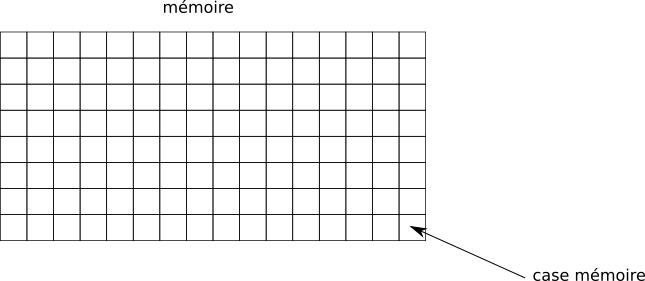
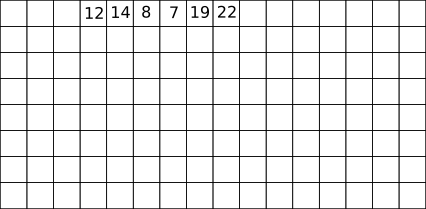
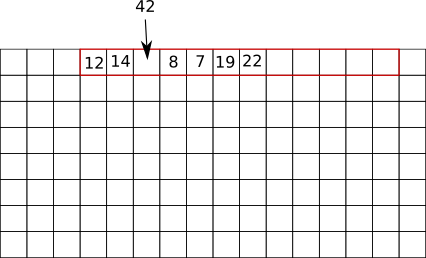 tableau dynamique
tableau dynamique





{kind=link}