def recherche_mot_boyer(texte, mot):
"""Recherche un mot dans un texte avec l'algo de boyer-moore
Arguments
---------
texte: str
le texte dans lequel on effectue la recherche
mot: str
le mot recherché
Returns
-------
bool
renvoie True si le mot est trouvé
"""
N = len(texte)
n = len(mot)
# création de notre dictionnaire de décalages
décalages = pre_traitement(mot)
# on commence à la fin du mot
i = n - 1
while i < N:
lettre = texte[i]
if lettre == mot[-1]:
# On vérifie que le mot est là avec un slice sur texte
# On pourrait faire un while
if texte[i-n+1:i+1] == mot:
return True
# on décale
if lettre in décalages.keys():
i += décalages[lettre]
else:
i += n
return False
# Quelques tests
assert recherche_mot_boyer('abracadabra', 'dab')
assert recherche_mot_boyer('abracadabra', 'abra')
assert recherche_mot_boyer('abracadabra', 'obra') == False
assert recherche_mot_boyer('abracadabra', 'bara') == False
assert recherche_mot_boyer('maman est là', 'maman')
assert recherche_mot_boyer('bonjour maman', 'maman')
assert recherche_mot_boyer('bonjour maman', 'papa') == FalseArchives de catégorie : NSI
Pré-traitement
def pre_traitement(mot):
"""Renvoie un dictionnaire avec pour clé la lettre et pour valeur le décalage
Arguments
---------
mot: str
Returns
-------
dict
"""
n = len(mot)
décalages = {}
# Il n'est pas nécéssaire d'inclure la dernière lettre
for i, letter in enumerate(mot[:-1]):
décalages[letter] = n - i -1
return décalages
# tests
assert pre_traitement("dab") == {'d': 2, 'a': 1}
assert pre_traitement("maman") == {'m': 2, 'a': 1}Recherche naive
def recherche_mot(texte, mot):
"""Recherche un mot dans un texte
Arguments
---------
texte: str
le texte dans lequel on effectue la recherche
mot: str
le mot recherché
Return
-------
renvoie True si le mot est trouvé et False si le mot n'est pas trouvé
Test:
recherche_mot("abcbcdcabbabc","abb") renvoie True
recherche_mot("abcbcdcabbabc","toto") renvoie False
recherche_mot("abcbcdcabbabc","ac") renvoie False
"""
N = len(texte)#taille du texte
n = len(mot)#taille du mot
i=0#indice pour le texte
k=0#indice pour le mot
if n>N:
print("erreur le mot est plus long que le texte")
#return
recherche=True#on mets à True la variable recherche
for i in range(N-n+1):# boucle pour i variant de 0 à taille de la chaine-taille du mot +1
while recherche and k+1 < n:#☺boucle tant que recherche est vraie (True) ET k+1 < taille du mot
if mot[k] != texte[i+k]:
recherche = False
k += 1
if recherche:
return True#on sort avec renvoie de True
return False#on sort avec renvoie de False
Recherche textuelle
Programme officiel
| Contenus | Capacités attendues | Commentaires |
|---|---|---|
| Recherche textuelle. | Étudier l’algorithme de Boyer- Moore pour la recherche d’un motif dans un texte. | L’intérêt du prétraitement du motif est mis en avant.L’étude du coût, difficile, ne peut être exigée |
La recherche d’une sous-chaine a des applications importantes en informatiques, par exemple dans les moteurs de recherche. Nous commencerons par une application naïve puis nous verrons qu’il est bien plus efficace de faire la recherche en sens inverse en partant du dernier caractère du mot pour ne pas tester toutes les positions.
Nous allons visualiser la vidéo ci-dessous et effectuer les implémentation sous python en mettent la vidéo en pause, les solutions des programme python sont données plus loin dans l’article.
Algorithme naïf
Nous allons appliquer une méthode itérative brute pour rechercher une sous-chaine dans une chaine de caractères.
Nous allons avancer dans le texte caractère par caractère, puis si le caractère considéré correspond au premier caractère du mot, nous comparerons les caractères suivants à ceux du mot. si la recherche s’avère fructueuse on renvoie True.
implémentation algorithme naïf python corrigé
L’exécution est relativement lente, la fonction doit tester N-n positions dans texte et pour chacune effectuer jusqu’à N-n comparaisons, soit jusqu’à (N−n)×n.
La complexité de cet algorithme est dans le pire des cas O ((N−n)×n), c’est une complexité quadratique O(N2) car souvent N>>n.
Nous allons voir qu’il est beaucoup plus efficace de faire la recherche à l’envers à partir de la fin du mot.
L’algorithme de Boyer-Moore : version simplifiée de Horspool
Nous allons étudier une version simplifiée du meilleur algorithme connu : l’algorithme de Boyer-Moore qui a été proposé par Nigel Horspool.
Cet algorithme repose sur deux idées :
- On compare le mot de droite à gauche à partir de sa dernière lettre.
- On n’avance pas dans le texte caractère par caractère, mais on utilise un décalage dépendant de la dernière comparaison effectuée.
Déroulement de l’algorithme
Nous considérons ici la recherche du motif mot = 'dab' dans le texte texte = 'abracadabra'.
On commence la recherche à l’index 2 :
abracadabra
dabIl n’y a pas de correspondance à la fin du mot : 'r' != 'b', donc on avance, mais de combien de caractères avance-t-on. Pour le décider, on utilise le fait que le caractère 'r' n’apparait pas dans le mot cherché, donc on peut avancer de n = len(mot) = 3 caractères sans crainte de rater le mot.
On recherche donc à l’indice 2 + 3 = 5 :
abracadabra
dabIl n’y a pas de correspondance à la fin du mot : 'a' != 'b', donc on avance, cependant, cette fois, comme le caractère 'a' apparait pas dans le mot cherché en avant-dernière position, on ne peut avancer que de une case pour faire une comparaison en alignant les 'a'.
On recherche donc à l’indice 5 + 1 = 6 :
abracadabra
dabIl n’y a pas de correspondance à la fin du mot : 'd' != 'b', donc on avance, cependant, cette fois, comme le caractère 'd' apparait dans le mot cherché en avant-avant-dernière position(première position, mais on doit lire à l’envers !), on avance de deux cases pour faire une comparaison en alignant les 'd'.
On recherche donc à l’indice 6 + 2 = 8 :
abracadabra
dabMaintenant lorsqu’on effectue les comparaisons à l’envers : les 'b', puis les 'a', puis les 'd' correspondent. On a trouvé le mot on renvoie VRAI.
Implémentation en Python
Pour implémenter efficacement cet algorithme, on va passer par un pré-traitement du nom pour facilement accéder au décalage à effectuer. On utilise un dictionnaire pour cela.
Implémentation du pré-traitement python corrigé.
Maintenant la fonction de recherche :
La récursivité
Cours :
NoteBook du cours avec les corrections
TD :
Simulation du problème des tours de Hanoï
TD renforcement :
NoteBook corrigé
Activité SUDOKU
NoteBook corrigé de l’activité SUDOKU (lien à venir…)
Exercice supplémentaire
Étant donné deux séquences, trouvez la longueur de la sous-séquence la plus longue présente dans les deux. Une sous-séquence est une séquence qui apparaît dans le même ordre relatif, mais pas nécessairement contiguë. Par exemple, « abc », « abg », « bdf », « aeg », « acefg », .. etc. sont des sous-séquences de « abcdefg ». Ecrire une fonction pour compter la plus longue sous-séquence.
Exemples
s1= »ABCDGH » , s2= »AEDFHR »
3 (ADH)
s1= »AGGTAB », s2= »GXTXAYB »
4 (GTAB)
DS La récursivité
Programmation orientée Objet (POO)
Cours POO :
NoteBook corrigé des exercices du cours
TD POO :
TD n°2 POO :
Notebook corrigé du TD n°2 POO
Exercices supplémentaires :
Notebook corrigé des exercices supplémentaires
Exercices type bac :
JEU PONG :
Devoir Surveillé :
Tri-fusion
Etudions d’abord l’algorithme de la fusion de 2 listes:
FUSIONNER (`liste_gauche`, `liste_droite`):
* On parcourt les deux listes `gauche` et `droite` en même temps,
Pour chaque paire d’éléments, on place le plus petit dans liste resultat.
* S’il reste des éléments dans `gauche` ou dans `droite` on les place à la fin de liste resultat
Développement graphique:
Soit 2 listes à fusionner:
Liste gauche : [3, 1, 4, 7, 8] et la liste droite : [2, 5, 6]



implémenter sous pyzo la fonction FUSIONNE donc voici le début:
def fusionne(lst1, lst2):
"""
list1 est une liste
list2 est une liste
la fonction retourne une liste resultat fusion des 2 listes list1 et list2
Example
-------
>>> fusionne([3, 1, 4, 7, 8], [2, 5, 6])
# listes non ordonnées
[2, 3, 1, 4, 5, 6, 7, 8]
>>> fusionne([1, 3, 4, 7, 8], [2, 5, 6])
# listes ordonnées
[1, 2, 3, 4, 5, 6, 7, 8]
"""Maintenant regardons l’algorithme de la fonction TRI FUSION
TRI FUSION (liste):
• Si liste est de taille <= 1 on ne fait rien.
• Sinon, On sépare liste en 2 parties gauche et droite,
• On appelle Tri fusion sur gauche et sur droite
• On fusionne gauche et droite dans liste
Développement graphique :
Soit la liste [2, 3, 1, 4, 5, 6, 7, 8] à trier par fusion
on sépare d’abord :

et on fusionne avec la fonction FUSIONNE décrite juste avant:

implémenter cette fonction
def fusionne(lst1, lst2):
"""
list1 est une liste
list2 est une liste
la fonction retourne une liste resultat fusion des 2 listes list1 et list2
Example
-------
>>> fusionne([3, 1, 4, 7, 8], [2, 5, 6])
# listes non ordonnées
[2, 3, 1, 4, 5, 6, 7, 8]
>>> fusionne([1, 3, 4, 7, 8], [2, 5, 6])
# listes ordonnées
[1, 2, 3, 4, 5, 6, 7, 8]
"""
def tri_fusion(lst):
'''lst est une liste non triées
Elle est coupé en 2 listes gauche et droite par le milieu (ou presque si taille impaire),
puis la fonction tri_fusion est rappelée pour chaque liste gauche et droite, jusqu'à n'obtenir des listes de taille 1.
en fin on applique la fonction fusionne les listes gauche et droite dans une liste que la fonction renvoie.
Exemple:
>>> tri_fusion([2, 3, 1, 4, 5, 6, 7, 8])
[1, 2, 3, 4, 5, 6, 7, 8]'''''
voici un programme pour créer des listes triées ou aléatoire pour faire des tests:
import random
def liste_triee(nb):#Création d'une liste trièe dans l'ordre croissant de nb valeur
nmax=nb
L=[]
for i in range(0,nmax):
L.append(i)
return L
def liste_aleatoire(nb):# fabrication d'une liste de nb valeurs aléatoires
nmax=nb
L=[]
for i in range(0,nmax):
L.append(random.randint(0,nmax))
return LMéthode diviser pour régner
Diviser pour régner
Le diviser pour régner est une méthode algorithmique basée sur le principe suivant :
On prend un problème (généralement complexe à résoudre), on divise ce problème en une multitude de petits problèmes, l’idée étant que les « petits problèmes » seront plus simples à résoudre que le problème original. Une fois les petits problèmes résolus, on recombine les « petits problèmes résolus » afin d’obtenir la solution du problème de départ.
Le paradigme « diviser pour régner » repose donc sur 3 étapes :
- DIVISER : le problème d’origine est divisé en un certain nombre de sous-problèmes
- RÉGNER : on résout les sous-problèmes (les sous-problèmes sont plus faciles à résoudre que le problème d’origine)
- COMBINER : les solutions des sous-problèmes sont combinées afin d’obtenir la solution du problème d’origine.
Les algorithmes basés sur le paradigme « diviser pour régner » sont très souvent des algorithmes récursifs.
Nous allons maintenant étudier un de ces algorithmes basés sur le principe diviser pour régner : le tri-fusion
Tri-fusion
Nous avons déjà étudié des algorithmes de tri : le tri par insertion et le tri par sélection. Nous allons maintenant étudier une nouvelle méthode de tri, le tri-fusion. Comme pour les algorithmes déjà étudiés, cet algorithme de tri fusion prend en entrée un tableau non trié et donne en sortie, le même tableau, mais trié.
À faire vous-même 1
Étudiez cet algorithme :
TRI FUSION (tableau):
• Si tableau est de taille <= 1 on ne fait rien.
• Sinon, On sépare tableau en 2 parties gauche et droite,
• On appelle Tri fusion sur gauche et sur droite
• On fusionne gauche et droite dans tableau
FUSIONNER (`tableau`, `gauche`, `droite`):
* On parcourt les deux tableaux `gauche` et `droite` en même temps,
Pour chaque paire d'éléments, on place le plus petit dans tableau.
* S'il reste des éléments dans `gauche` ou dans `droite` on les place à la fin
de tableau Pour trier un tableau A, on fait l’appel initial TRI-FUSION(A, 1, A.longueur)
Rappel : Attention, en algorithmique, les indices des tableaux commencent à 1
Cet algorithme est un peu difficile à appréhender, on notera qu’il est composé de deux fonctions FUSIONNER et TRI-FUSION (fonction récursive). La fonction TRI-FUSION assure la phase « DIVISER » et la fonction FUSION assure les phases « RÉGNER » et « COMBINER ».
Voici un exemple d’application de cet algorithme sur le tableau A = [23, 12, 4, 56, 35, 32, 42, 57, 3] :
À faire vous-même 2
Étudiez attentivement le schéma ci-dessous afin de mieux comprendre le principe du tri-fusion (identifiez bien les phases « DIVISER » et « COMBINER »).
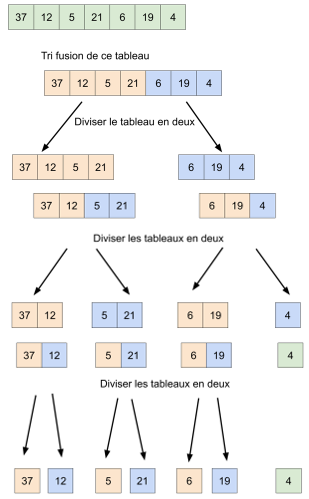
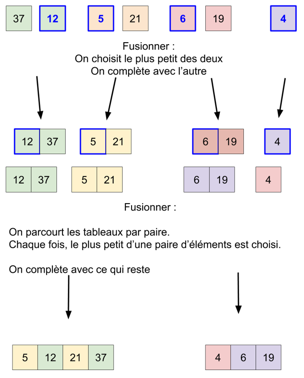
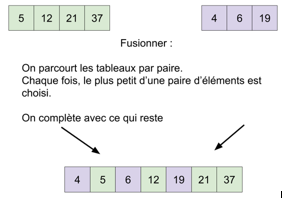
On remarque que dans le cas du tri-fusion, la phase « RÉGNER » se réduit à sa plus simple expression, en effet, à la fin de la phase « DIVISER », nous avons à trier des tableaux qui comportent un seul élément, ce qui est évidemment trivial.
À faire vous-même 3
Reprenez tout le raisonnement qui vient d’être fait sur le tableau T = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]. Vous n’hésiterez pas à faire un schéma et à expliquer la fusion de 2 tableaux triés.
Nous avons vu que le tri par insertion et tri par sélection ont tous les deux une complexité O(n2)
. Qu’en est-il pour le tri-fusion ?
Le calcul rigoureux de la complexité de cet algorithme sort du cadre de ce cours. Mais, en remarquant que la première phase (DIVISER) consiste à « couper » les tableaux en deux plusieurs fois de suite, intuitivement, on peut dire qu’un logarithme base 2 doit intervenir. La deuxième phase consiste à faire des comparaisons entre les premiers éléments de chaque tableau à fusionner, on peut donc supposer que pour un tableau de n éléments, on aura n comparaisons. En combinant ces 2 constations on peut donc dire que la complexité du tri-fusion est en O(n.log(n))
(encore une fois la « démonstration » proposée ici n’a rien de rigoureux).
La comparaison des courbes de la fonction n2 (en rouge) et n.log(n)
(en bleu) :
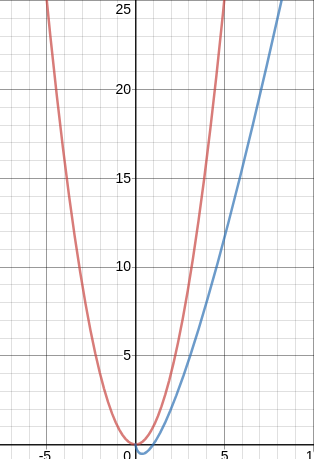
nous montre que l’algorithme de tri-fusion est plus « efficace » que l’algorithme de tri par insertion ou que l’algorithme de tri par sélection.
Présentation vidéo détaillée du tri fusion
Utilisation du tri fusion:
Contrairement au tri par sélection ou par insertion, le tri fusion est réellement utilisé en pratique.
Il a de nombreux avantages :
• complexité optimale (cela ne signifie pas qu’il est le plus rapide)
• stable (voir plus bas)
• facile à mettre en œuvre
Cependant, il est possible d’améliorer la méthode :
timsort, le tri natif en Python et Javascript utilise une combinaison du tri fusion et du tri par insertion.

Auteur : David Roche
Projet : implémentation en Python des algorithmes sur les arbres binaires
Le but de ce projet est d’implémenter en Python les algorithmes sur les arbres binaires précédemment étudiés. Il sera donc sans doute nécessaire de reprendre ce qui a été vu sur la structure de données « arbre » et sur « les algorithmes sur les arbres binaires ».
Comme nous l’avons déjà dit, Python ne propose pas de structure de données permettant d’implémenter directement les arbres binaires. Il va donc être nécessaire de créer cette structure. Pour programmer ce type de structure, nous allons utiliser le paradigme objet (à voir si pas encore étudier paradigme objet)
Vous trouverez ci-dessous la classe « ArbreBinaire » qui va nous permettre d’implémenter des arbres binaires.
class ArbreBinaire:
def __init__(self, valeur):
self.valeur = valeur
self.enfant_gauche = None
self.enfant_droit = None
def insert_gauche(self, valeur):
if self.enfant_gauche == None:
self.enfant_gauche = ArbreBinaire(valeur)
else:
new_node = ArbreBinaire(valeur)
new_node.enfant_gauche = self.enfant_gauche
self.enfant_gauche = new_node
def insert_droit(self, valeur):
if self.enfant_droit == None:
self.enfant_droit = ArbreBinaire(valeur)
else:
new_node = ArbreBinaire(valeur)
new_node.enfant_droit = self.enfant_droit
self.enfant_droit = new_node
def get_valeur(self):
return self.valeur
def get_gauche(self):
return self.enfant_gauche
def get_droit(self):
return self.enfant_droit
À faire vous-même 1
Étudiez attentivement la classe « ArbreBinaire » (méthodes et attributs). Vous pouvez, par exemple, vous interroger sur l’utilité de toutes les méthodes de cette classe.
Voici un exemple d’utilisation de cette classe pour construire un arbre binaire :
Soit l’arbre binaire suivant : 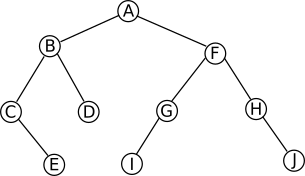 Arbre 1
Arbre 1
Voici le programme qui va permettre de construire cet arbre à l’aide de la classe « ArbreBinaire » :
class ArbreBinaire:
def __init__(self, valeur):
self.valeur = valeur
self.enfant_gauche = None
self.enfant_droit = None
def insert_gauche(self, valeur):
if self.enfant_gauche == None:
self.enfant_gauche = ArbreBinaire(valeur)
else:
new_node = ArbreBinaire(valeur)
new_node.enfant_gauche = self.enfant_gauche
self.enfant_gauche = new_node
def insert_droit(self, valeur):
if self.enfant_droit == None:
self.enfant_droit = ArbreBinaire(valeur)
else:
new_node = ArbreBinaire(valeur)
new_node.enfant_droit = self.enfant_droit
self.enfant_droit = new_node
def get_valeur(self):
return self.valeur
def get_gauche(self):
return self.enfant_gauche
def get_droit(self):
return self.enfant_droit
#######fin de la classe########
######début de la construction de l'arbre binaire###########
racine = ArbreBinaire('A')
racine.insert_gauche('B')
racine.insert_droit('F')
b_node = racine.get_gauche()
b_node.insert_gauche('C')
b_node.insert_droit('D')
f_node = racine.get_droit()
f_node.insert_gauche('G')
f_node.insert_droit('H')
c_node = b_node.get_gauche()
c_node.insert_droit('E')
g_node = f_node.get_gauche()
g_node.insert_gauche('I')
h_node = f_node.get_droit()
h_node.insert_droit('J')
######fin de la construction de l'arbre binaire###########
À faire vous-même 2
Étudiez attentivement le programme ci-dessus afin de comprendre le principe de « construction d’un arbre binaire »
Il est possible d’afficher un arbre binaire dans la console Python, pour cela, nous allons écrire une fonction « affiche ». Cette fonction renvoie une série de tuples de la forme (valeur,arbre_gauche, arbre_droite), comme « arbre_gauche » et « arbre_droite » seront eux-mêmes affichés sous forme de tuples, on aura donc un affichage qui ressemblera à : (valeur,(valeur_gauche,arbre_gauche_gauche,arbre_gauche_droite),(valeur_droite,arbre_droite_gauche,arbre_droite_droite)), mais comme « arbre_gauche_gauche » sera lui-même représenté par un tuple… Nous allons donc avoir des tuples qui contiendront des tuples qui eux-mêmes contiendront des tuples…
Pour l’arbre binaire défini ci-dessus, on aura :
('A', ('B', ('C', None, ('E', None, None)), ('D', None, None)), ('F', ('G', ('I', None, None), None), ('H', None, ('J', None, None))))
Voici le programme augmenté de la fonction « affiche » :
class ArbreBinaire:
def __init__(self, valeur):
self.valeur = valeur
self.enfant_gauche = None
self.enfant_droit = None
def insert_gauche(self, valeur):
if self.enfant_gauche == None:
self.enfant_gauche = ArbreBinaire(valeur)
else:
new_node = ArbreBinaire(valeur)
new_node.enfant_gauche = self.enfant_gauche
self.enfant_gauche = new_node
def insert_droit(self, valeur):
if self.enfant_droit == None:
self.enfant_droit = ArbreBinaire(valeur)
else:
new_node = ArbreBinaire(valeur)
new_node.enfant_droit = self.enfant_droit
self.enfant_droit = new_node
def get_valeur(self):
return self.valeur
def get_gauche(self):
return self.enfant_gauche
def get_droit(self):
return self.enfant_droit
#######fin de la classe########
######début de la construction de l'arbre binaire###########
racine = ArbreBinaire('A')
racine.insert_gauche('B')
racine.insert_droit('F')
b_node = racine.get_gauche()
b_node.insert_gauche('C')
b_node.insert_droit('D')
f_node = racine.get_droit()
f_node.insert_gauche('G')
f_node.insert_droit('H')
c_node = b_node.get_gauche()
c_node.insert_droit('E')
g_node = f_node.get_gauche()
g_node.insert_gauche('I')
h_node = f_node.get_droit()
h_node.insert_droit('J')
######fin de la construction de l'arbre binaire###########
def affiche(T):
if T != None:
return (T.get_valeur(),affiche(T.get_gauche()),affiche(T.get_droit()))
À faire vous-même 3
Vérifiez que « affiche(racine) » renvoie bien :
('A', ('B', ('C', None, ('E', None, None)), ('D', None, None)), ('F', ('G', ('I', None, None), None), ('H', None, ('J', None, None))))
N.B : la fonction « affiche » n’a pas une importance fondamentale, elle sert uniquement à vérifier que les arbres programmés sont bien corrects.
À faire vous-même 4
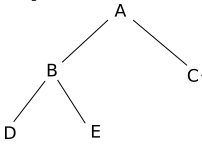
Programmez à l’aide de la classe « ArbreBinaire », l’arbre binaire suivant :
Arbre 2
Vérifiez votre programme à l’aide de la fonction « affiche »
Vous allez maintenant pouvoir commencer à travailler sur l’implémentation des algorithmes sur les arbres binaires :
À faire vous-même 5
Programmez la fonction « hauteur » qui prend un arbre binaire T en paramètre et renvoie la hauteur de T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 1 »).
À faire vous-même 6
Programmez la fonction « taille » qui prend un arbre binaire T en paramètre et renvoie la taille de T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 1 »).
À faire vous-même 7
Programmez la fonction « parcours_infixe » qui prend un arbre binaire T en paramètre et qui permet d’obtenir le parcours infixe de l’arbre T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 1 »).
À faire vous-même 8
Programmez la fonction « parcours_prefixe » qui prend un arbre binaire T en paramètre et qui permet d’obtenir le parcours préfixe de l’arbre T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 1 »).
À faire vous-même 9
Programmez la fonction « parcours_suffixe » qui prend un arbre binaire T en paramètre et qui permet d’obtenir le parcours suffixe de l’arbre T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 1 »).
À faire vous-même 10
Programmez la fonction « parcours_largeur » qui prend un arbre binaire T en paramètre et qui permet d’obtenir le parcours en largeur de l’arbre T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 1 »).
Nous allons maintenant travailler sur les arbres binaires de recherche.
À faire vous-même 11
Programmez, à l’aide de la classe « ArbreBinaire », l’arbre binaire de recherche ci-dessous : 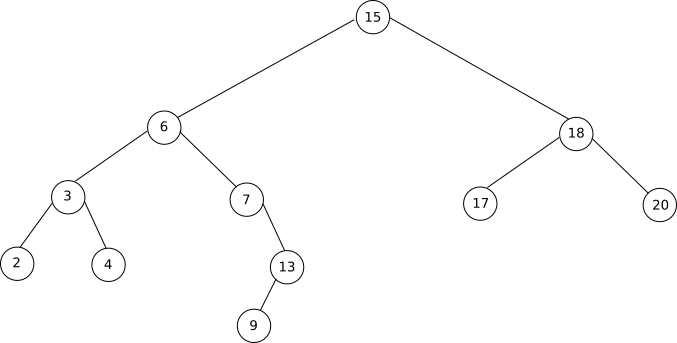 Arbre 3
Arbre 3
Vérifiez votre réponse à l’aide de la fonction « affichage »
À faire vous-même 12
Afin de vérifier que l’arbre binaire « Arbre 3 » est bien un arbre binaire de recherche, utilisez la fonction « parcours_infixe » programmée dans le « À faire vous-même 7 ».
À faire vous-même 13
Programmez la fonction « arbre_recherche » qui prend un arbre binaire T et un entier k en paramètres et qui renvoie True si k appartient à T et False dans le cas contraire (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 3 ») avec k = 13 et k = 16.
À faire vous-même 14
Programmez la fonction « arbre_recherche_ite » (version itérative de la fonction « arbre_recherche ») qui prend un arbre binaire T et un entier k en paramètres et qui renvoie True si k appartient à T et False dans le cas contraire (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 3 ») avec k = 13 et k = 16.
À faire vous-même 15
Programmez la fonction « arbre_insertion » qui prend T (un arbre binaire) et y (un objet de type « ArbreBinaire ») en paramètres et qui insert y dans T (algorithme correspondant, voir ici)
Testez votre fonction en utilisant l’arbre vu plus haut (schéma « Arbre 3 ») avec y.valeur = 16.
Auteur : David Roche
Exercices de programmation complémentaires
Ces exercices vous permettront de vous entrainer en vue de l’évaluation sur la programmation.
Exercice 1
On dispose de la formule suivante pour convertir les degrés Fahrenheit en degrés Celsius :
C = 0,55556 × (F – 32)
où F est une température en degrés Fahrenheit et C la température correspondante en degrés Celsius.
1. Ecrire un programme qui convertit en degrés Celsius une température rentrée au clavier en degrés Fahrenheit.
2. Même question pour la conversion inverse.
Exercice 2
Écrire un programme qui affiche un triangle rempli d’étoiles (*) sur un nombre de lignes donné passé en paramètre, exemple :

• 1ère version : à l’aide de deux boucles for, en imprimant les * une par une.
On remarquera que, par défaut dans l’instruction print() , figure end = ‘\n’, qui fait passer à la ligne.
print(…, end =’’) ne fera donc pas passer à la ligne.
• 2ème version : avec une seul boucle for, et une chaîne de caractères où vous accumulerez
des étoiles (pour ceux qui vont un peu plus vite, print(« machin » end= ‘’) évite de passer
à la ligne.
Exercice 3
Programmation d’un petit jeu de devinette. L’ordinateur choisit au hasard un nombre compris entre 1 et 100.
Le but du jeu est de le deviner en un nombre d’essai minimal. À chaque tentative, l’ordinateur, indique « gagné », « trop petit » ou « trop grand ». L’utilisateur dispose d’un nombre d’essais limités.
Écrire l’algorithme en « langage naturel ». Programmer le jeu, et le tester.
Remarque : on utilisera la bibliothèque random.
Pour cela, on écrit « import random » en début de programme.
nombre = random.randint(a, b) renverra un nombre aléatoire tel que
a ≤ Nombre ≤ b
Exercice 4
Convertir une note scolaire N quelconque, entrée par l’utilisateur sous forme de points (par exemple 27 sur 85), en une note standardisée suivant le code ci-dessous :
| Note N | Appréciation |
| N >= 80 % | A |
| 80 % > N >= 60 % | B |
| 60 % > N >= 50 % | C |
| 50 % > N >= 40 % | D |
| N < 40 % | E |
Exercice 5
Ecrire un programme qui affiche les carrés des entiers de 1 à 7 .
Exercice 6
Ecrire un programme qui affiche n fois la suite de symboles suivante :
A #Si n=1
AA #si n=2
AAA
etc…sans utiliser le * comme par exemple print(3* »A »).
n est donné par l’utilisateur.
Exercice 7
Ecrire un programme qui demande un prénom. Si ce prénom est Paul, le programme affiche « enfin c’est toi », sinon le programme redemande un nouveau prénom car ce n’est pas la personne qu’il attend (un genre de mot de passe non ?).
Exercice 8
Ecrire un programme qui additionne tous les nombres que vous entrez (tour à tour) et qui s’arrête lorsque la somme dépasse 100.