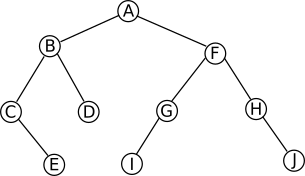
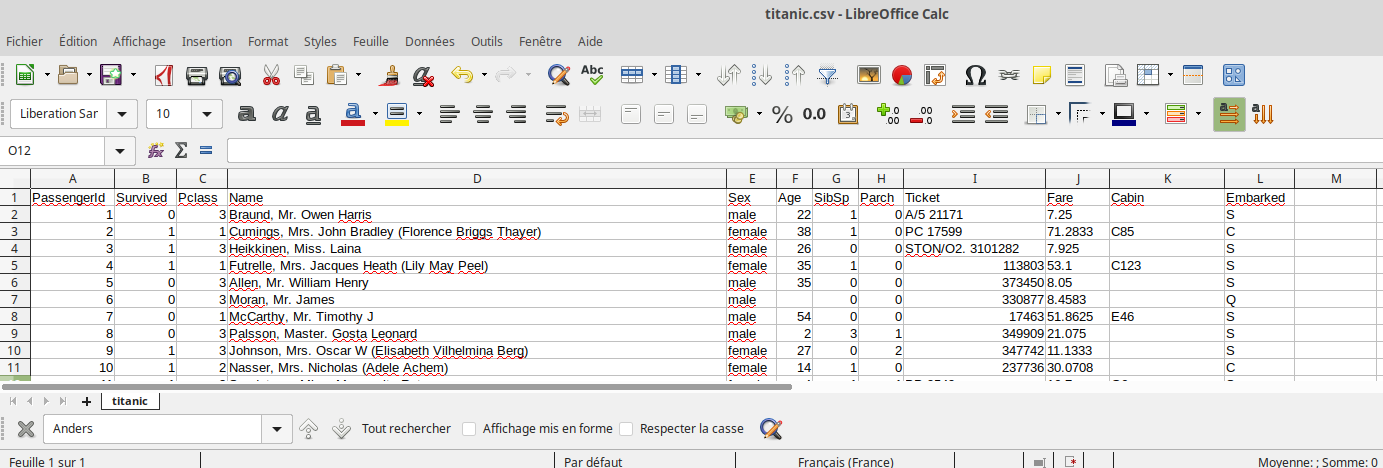
Ce jeu de données contient des informations sur une partie des passagers (plus exactement sur 891 passagers) du Titanic. Pour un petit rappel historique, vous pouvez consulter la page Wikipédia consacrée à ce paquebot : ici
Ouvrez le fichier « titanic.csv » à l’aide d’un tableur.
Vous devriez obtenir quelque chose qui ressemble à ceci :
Trouvez la signification des différents descripteurs : « PassengerId », « Survived », « Pclass »… Aide :
L’objectif de ce projet est d’utiliser l’algorithme des k plus proches voisins afin de déterminer si les passagers ci-dessous auraient survécus au naufrage du Titanic.
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Embarked
2
Mr. Bidochon Robert
male
37
1
4
244377
21.075
C
2
Mrs. Bidochon Raymonde
female
36
1
4
244379
20.2175
C
2
Mrs. Bidochon Gisèle
female
11
3
2
244382
15.045
C
2
Mr. Bidochon René.
male
8
3
2
244383
12.945
C
2
Mr. Bidochon Eugène.
male
4
3
2
137383
10.17
C
2
Mr. Bidochon Louis.
male
1
3
2
3738
11.13
C
PARTIE 1 : Analyse des données (Data scientist)
Un travail de préparation des données va être nécessaire , vous allez donc devoir passer par quelques étapes que voici :
– Pour ceux qui ne souhaitent pas poursuivre la spécialité N.S.I vous pouvez opérer les changements directement avec le tableur.
– Pour ceux qui souhaitent poursuivre la spécialité N.S.I vous devez opérer les changements directement avec python. Le fichier python ci-dessous, vous aidera faire les manipulations nécessaires).
Analyser ce fichier, combien y a t’il de fonctions,que font elles?
Pour la suite du projet vous pouvez travailler soit avec la liste de dictionnaire créé avec le programme, soit avec le fichier csv.
Toutes les colonnes ne vont pas forcement être pertinentes, par exemple, d’après vous, lors du naufrage, le nom du passager a-t-il eu une quelconque importance sur le fait qu’il ait ou non survécu ? (nous ne tiendrons pas compte du fait que certaines personnes aient pu être privilégié au vu de leur nom de famille, sur les 891 passagers présents dans le fichier titanic.csv, ce phénomène est négligeable).
Solution 1 avec le tableur:
En analysant le contenu du fichier titanic.csv (par exemple à l’aide d’un tableur), choisissez les descripteurs ( c’est à dire les colonnes) qui vous paraissent les plus pertinents. Vous effacerez les colonnes qui vous semblent inutiles directement dans le tableur ou avec python pour obtenir soit une liste de dictionnaire (comme Data dans le fichier donné ci dessus), soit un nouveau fichier titanic_V2.csv
Solution 2, avec python :
Nettoyer la liste de dictionnaire, en ne gardant pour chaque dictionnaire que les clés que vous jugez nécessaire. Enregistrer votre fichier python.
Pour certains passagers, il manque des données. Par exemple, l’âge de certains passagers n’est pas renseigné. Une solution est de supprimer du fichier les passagers ayant des données incomplètes.
Supprimer du fichier les passagers ayant des données incomplètes pour obtenir un nouveau fichier titanic_V3.csv ou une nouvelle liste de dictionnaire avec les données incomplètes supprimées.
L’utilisation de l’algorithme des k plus proches voisins nous oblige à proscrire les données non numériques. Par exemple, la colonne « Sex » ne peut pas être utilisée telle quelle, l’algorithme n’est pas capable de traiter les « male » et « female ».
Proposer une alternative pour remplacer les chaines de caracteres « male » et « female ». Modifier certaines colonnes directement dans le tableur ou avec un script python pour obtenir un nouveau fichier titanic_V4.csv ou une nouvelle liste de dictionnaire.
Avec l’algorithme des k plus proches voisins nous sommes amenés à calculer des distances. Comparer l’amplitude des valeurs de la colonne Pclass avec l’amplitude des valeurs de la colonne Age.
Amplitude des valeurs de la colonne Pclass : Amplitude des valeurs de la colonne Age :
Code python pour obtenir cette amplitude à partir de titanic_V4.csv ou avec la liste de dictionnaire : Une des conséquence de l’observation précédente est que le calcul de la distance ne va pas traiter de facon égalitaire les colonnes. Pour rétablir l’équité nous allons procéder ainsi : Pour chaque colonne :
On repère la valeur minimale (v_min) et la valeur maximale ( v_max)
On va diviser chacune des valeurs de la colonne par la diffrence v_max-v_min Exemple : Si une colonne contient les valeurs [5,4,1,11,7] v_min=1 et v_max=11 Alors on divise toutes les valeurs par 8 ce qui donne [0.5,0.4,0.1,1.1,0.7]
Remarque : Toutes les valeurs de toutes les colonnes seront comprises entre 0 et 1. Cela nous garantie un traitement équitable entre les colonnes.
Faire les modifications nécessaires au fichier titanic_V4.csv pour garantir un équitable entre les colonnes. On nommera titanic_V5.csv le nouveau fichier obtenu. Vous devriez avoir un fichier comme celui-ci:
Partie 3: Utilisation de l’algorithme des K plus proche voisins
A l’aide du TP sur les k plus proches voisins, (avec k=5) prédire quel(s) membre(s) de la famille Bidochons aurait(ent) survécu(s) au naufrage du Titanic ?
En utilisant l’algorithme proposé par scikit-learn des k plus proches voisins établir votre programme python et donnez la liste des survivants en faisant varier k de 3 à 19 ( valeur impaire).
( c’est la ligne : from sklearn.neighbors import KNeighborsClassifier qui charge l’algorithme)
La recherche d’une sous-chaine a des applications importantes en informatiques, par exemple dans les moteurs de recherche. Nous commencerons par une application naïve puis nous verrons qu’il est bien plus efficace de faire la recherche en sens inverse en partant du dernier caractère du mot pour ne pas tester toutes les positions.
Nous allons visualiser la vidéo ci-dessous et effectuer les implémentation sous python en mettent la vidéo en pause, les solutions des programme python sont données plus loin dans l’article.
Algorithme naïf
Nous allons appliquer une méthode itérative brute pour rechercher une sous-chaine dans une chaine de caractères.
Nous allons avancer dans le texte caractère par caractère, puis si le caractère considéré correspond au premier caractère du mot, nous comparerons les caractères suivants à ceux du mot. si la recherche s’avère fructueuse on renvoie True.
L’exécution est relativement lente, la fonction doit tester N-n positions dans texte et pour chacune effectuer jusqu’à N-n comparaisons, soit jusqu’à (N−n)×n.
La complexité de cet algorithme est dans le pire des cas O ((N−n)×n), c’est une complexité quadratique O(N2) car souvent N>>n.
Nous allons voir qu’il est beaucoup plus efficace de faire la recherche à l’envers à partir de la fin du mot.
L’algorithme de Boyer-Moore : version simplifiée de Horspool
Nous allons étudier une version simplifiée du meilleur algorithme connu : l’algorithme de Boyer-Moore qui a été proposé par Nigel Horspool.
Cet algorithme repose sur deux idées :
On compare le mot de droite à gauche à partir de sa dernière lettre.
On n’avance pas dans le texte caractère par caractère, mais on utilise un décalage dépendant de la dernière comparaison effectuée.
Déroulement de l’algorithme
Nous considérons ici la recherche du motif mot = 'dab' dans le texte texte = 'abracadabra'.
On commence la recherche à l’index 2 :
abracadabra
dab
Il n’y a pas de correspondance à la fin du mot : 'r' != 'b', donc on avance, mais de combien de caractères avance-t-on. Pour le décider, on utilise le fait que le caractère 'r' n’apparait pas dans le mot cherché, donc on peut avancer de n = len(mot) = 3 caractères sans crainte de rater le mot.
On recherche donc à l’indice 2 + 3 = 5 :
abracadabra
dab
Il n’y a pas de correspondance à la fin du mot : 'a' != 'b', donc on avance, cependant, cette fois, comme le caractère 'a' apparait pas dans le mot cherché en avant-dernière position, on ne peut avancer que de une case pour faire une comparaison en alignant les 'a'.
On recherche donc à l’indice 5 + 1 = 6 :
abracadabra
dab
Il n’y a pas de correspondance à la fin du mot : 'd' != 'b', donc on avance, cependant, cette fois, comme le caractère 'd' apparait dans le mot cherché en avant-avant-dernière position(première position, mais on doit lire à l’envers !), on avance de deux cases pour faire une comparaison en alignant les 'd'.
On recherche donc à l’indice 6 + 2 = 8 :
abracadabra
dab
Maintenant lorsqu’on effectue les comparaisons à l’envers : les 'b', puis les 'a', puis les 'd' correspondent. On a trouvé le mot on renvoie VRAI.
Implémentation en Python
Pour implémenter efficacement cet algorithme, on va passer par un pré-traitement du nom pour facilement accéder au décalage à effectuer. On utilise un dictionnaire pour cela.
Etudions d’abord l’algorithme de la fusion de 2 listes:
FUSIONNER (`liste_gauche`, `liste_droite`): * On parcourt les deux listes `gauche` et `droite` en même temps, Pour chaque paire d’éléments, on place le plus petit dans liste resultat. * S’il reste des éléments dans `gauche` ou dans `droite` on les place à la fin de liste resultat
Développement graphique:
Soit 2 listes à fusionner:
Liste gauche : [3, 1, 4, 7, 8] et la liste droite : [2, 5, 6]
implémenter sous pyzo la fonction FUSIONNE donc voici le début:
def fusionne(lst1, lst2):
"""
list1 est une liste
list2 est une liste
la fonction retourne une liste resultat fusion des 2 listes list1 et list2
Example
-------
>>> fusionne([3, 1, 4, 7, 8], [2, 5, 6])
# listes non ordonnées
[2, 3, 1, 4, 5, 6, 7, 8]
>>> fusionne([1, 3, 4, 7, 8], [2, 5, 6])
# listes ordonnées
[1, 2, 3, 4, 5, 6, 7, 8]
"""
Maintenant regardons l’algorithme de la fonction TRI FUSION
TRI FUSION (liste): • Si liste est de taille <= 1 on ne fait rien. • Sinon, On sépare liste en 2 parties gauche et droite, • On appelle Tri fusion sur gauche et sur droite • On fusionne gauche et droite dans liste
Développement graphique :
Soit la liste [2, 3, 1, 4, 5, 6, 7, 8] à trier par fusion
on sépare d’abord :
et on fusionne avec la fonction FUSIONNE décrite juste avant:
implémenter cette fonction
def fusionne(lst1, lst2):
"""
list1 est une liste
list2 est une liste
la fonction retourne une liste resultat fusion des 2 listes list1 et list2
Example
-------
>>> fusionne([3, 1, 4, 7, 8], [2, 5, 6])
# listes non ordonnées
[2, 3, 1, 4, 5, 6, 7, 8]
>>> fusionne([1, 3, 4, 7, 8], [2, 5, 6])
# listes ordonnées
[1, 2, 3, 4, 5, 6, 7, 8]
"""
def tri_fusion(lst):
'''lst est une liste non triées
Elle est coupé en 2 listes gauche et droite par le milieu (ou presque si taille impaire),
puis la fonction tri_fusion est rappelée pour chaque liste gauche et droite, jusqu'à n'obtenir des listes de taille 1.
en fin on applique la fonction fusionne les listes gauche et droite dans une liste que la fonction renvoie.
Exemple:
>>> tri_fusion([2, 3, 1, 4, 5, 6, 7, 8])
[1, 2, 3, 4, 5, 6, 7, 8]'''''
voici un programme pour créer des listes triées ou aléatoire pour faire des tests:
import random
def liste_triee(nb):#Création d'une liste trièe dans l'ordre croissant de nb valeur
nmax=nb
L=[]
for i in range(0,nmax):
L.append(i)
return L
def liste_aleatoire(nb):# fabrication d'une liste de nb valeurs aléatoires
nmax=nb
L=[]
for i in range(0,nmax):
L.append(random.randint(0,nmax))
return L
On considère deux jeux de 54 cartes à jouer. Pour les mélanger, on créer un troisième paquet en empilant les cartes aléatoirement piochées dans un des deux jeux. Quand l’un des deux jeux est vide, on empile le jeu restant sur le troisième paquet. On modélisera les deux jeux de 54 cartes par deux listes contenant respectivement les entiers de 101 à 154 et de 201 à 254. Écrire une fonction python qui réalise le mélange.
Exercice 2 (Bataille, pile)
On considère un jeu de 52 cartes à jouer (pas de joker) que l’on modélise par une liste contenant quatre fois les entiers de 1 à 13. La valeur d’une carte est égale à son numéro. On distribue ensuite aléatoirement 13 cartes à quatre joueurs qui les empilent consciencieusement devant eux. A chaque tour de jeu, les quatre joueurs posent la carte au sommet de leur pile au milieu. Celui qui a la carte la plus forte remporte le pli, c’est à dire les quatre cartes du tour. S’il y a égalité, on tire au sort le joueur qui gagne rafle le pli. Le joueur qui a la fin a le plus de points gagne la partie. Écrire un programme Python qui simule ce jeu.
Exercice 3 (La bonne syntaxe,pile)
L’analyse syntaxique est une phase indispensable de la compilation des programmes. Les piles sont particulièrement bien adaptées à ce genre de traitements. On va se limiter à la reconnaissance des expressions bien parenthésés. Nous devons écrire un programme qui :—accepte les expressions comme (a), (a b)((c d e)) ou (((a)(b c d))(e)) où a, b, etc. sont des expressions quelconques sans parenthèses—rejette les expressions comme a )(, (a b)((c) ou (((a b)(c d e f))))On remarque d’abord que les expressions a, b, c .. qui apparaissent n’ont aucune importance pour savoir si l’expression est bien parenthésée. On va lire l’expression sous la forme d’une chaine de caractères et utiliser une pile. Lors de la lecture dela chaine, on empile les ”(”. Pour les ”)”, on vérifie d’abord si le sommet de la pile est ”(”, dans ce cas, on dépile. Sinon, on empile le ”(”. A la fin de l’algorithme, si l’expression est bien parenthésée, la pile est vide.Écrire un algorithme utilisant une pile et ses primitives.
Exercice 4 (Évaluation d’une expression arithmétique, pile)
Nous allons voir ici une utilisation des piles pour évaluer des expressions arithmétiques.Par exemple, on souhaite évaluer(3×(5+2×3)+4)×2On se contentera d’évaluer des expressions correctement écrites avec seulement des nombres à un seul chiffre et uniquement des sommes et des produits.
1. On commence par écrire l’expression en notation ”postfixé” ou inverse polonaise Dans cette notation, on écrit les opérations après les nombres plutôt qu’avant.Par exemple,2+3s’écrira2,3,+
Ecrire l’expression(3×(5+2×3)+4)×2 en postfixé.
2. En lisant de gauche à droite l’expression postfixé, on construit une Pile suivant les règles suivantes :—Si on lit un nombre, on l’empile—Si on lit une opération, on dépile deux nombres et on effectue l’opération entre ces deux nombres
3. Ecrire en pseudo code, une séquence qui permet d’évaluer l’expression.
4. Implémenter l’algorithme en python.
Exercice 5 (file)
Dans un supermarché il y a 5 caisses et une file d’attente commune. Dès qu’une caisse est libre, le client en tête de file y est envoyé. Le temps de passage en caisse est aléatoirement compris entre 3 et 10 minutes. Il y a dix clients dans la file d’attente.
1. Réaliser une simulation de leurs passages en caisses et afficher en combien de minutes tous les clients sont passés.
2. Refaire quelques essais avec plus de clients.
Pour la file d’attente , vous utiliserez une file avec l’objet deque sous python, voir description objet deque ici.
Par exemple voici la liste d’attente:
from collections import deque #import container deque
file_attente=['1','2','3','4','5','6','7','8','9','10'] #la liste d'attente commune avec 10 clients
d = deque(file_attente) #création file client
Retire et renvoie un élément de l’extrémité droite de la deque. S’il n’y a aucun élément, lève une exception IndexError.
popleft()
Retire et renvoie un élément de l’extrémité gauche de la deque. S’il n’y a aucun élément, lève une exception IndexError.
Pour la liste des caisses, vous utiliserez une liste [0,0,0,0,0], premier élément temps caisse 1, ici à 0, puis temps caisse 2 ou un dictionnaire {1: 0, 2: 0, 3: 0, 4: 0, 5: 0}, clé 1 = caisse 1 avec sa valeur = temps ici à 0.
Exercice 6
Un poste de contrôle est alimenté en pièces toutes les 7 minutes. Ces pièces sont de quatre types qui nécessitent respectivement
4, 6, 8 et 9 minutes pour être contrôlés. Les fréquences des quatre types sont identiques.
1. A l’aide d’une file, simuler le fonctionnement du poste de contrôle pendant 1 heure, puis 80 heures.
2. Calculer le nombre de pièces en attente de contrôle
3. Déterminer la durée de séjour des pièces dans le poste de contrôle. Afficher celle de la dernière
4. Le contrôleur fait une pause de 15 minutes toutes les 4 heures. Déterminer le nombre d’heures effectives de travail.
Exercice 7
Un restaurant de 50 tables à 2 couverts ouvre ses portes pendant 4 heures chaque soir. L’intervalle de temps entre l’arrivée de deux groupes de clients est d’environ 2 minutes. Les groupes sont constitués aléatoirement de 2 à 6 convives avec des fréquences identiques.
Les tables peuvent être rassemblées pour les groupes de plus de 2 personnes. Lorsqu’un groupe arrive, il attend que des tables en nombre suffisant soient libres.
Une fois assis, le groupe reste pendant une durée aléatoirement comprise entre 60 et 120 minutes.
Simuler le fonctionnement du restaurant pendant une soirée.
Afficher le nombre de clients servis lors d’un service et nombre moyen de clients par table.
Exercice 2 du sujet 10 de l’épreuve pratique de 2021
Faire l’exercice 2 du Sujet n°10 de l’épreuve pratique de 2021