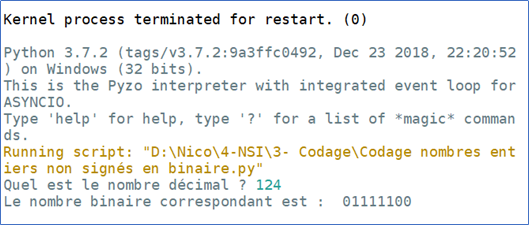
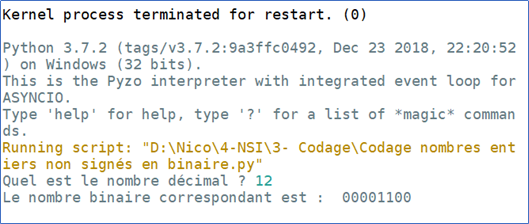
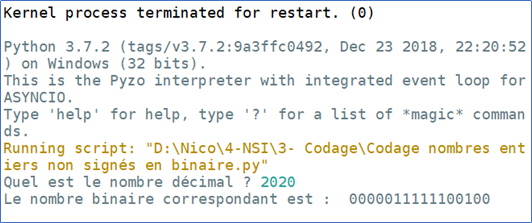
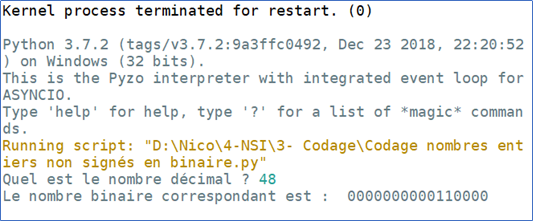
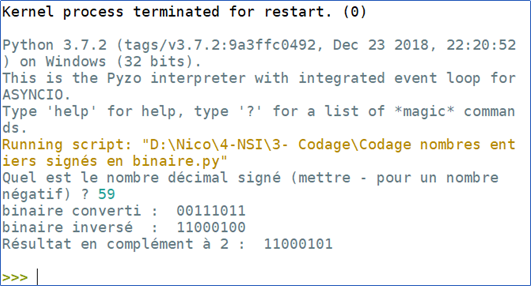
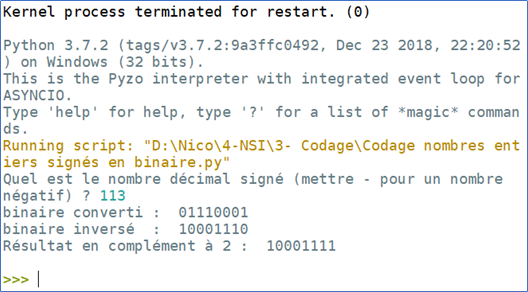
Ecrire une fonction decimal_vers_binaire() qui prend comme argument un nombre entier décimal saisi par l’utilisateur et qui renvoi le nombre binaire correspondant sur 1 octet (8bits).
La fonction devra coder le nombre décimal en binaire et rajoutera le nombre de 0 voulu pour faire un octet.
Exemples :
Exercice 2
Modifier la fonction précédente pour coder le nombre entier sur 16 bits.
Exemples :
Exercice 3
Ecrire une fonction plus_un() qui ajoute 1 à un nombre binaire de 8 bits saisi par l’utilisateur passé en argument.
Exemples :
Pour vous aiguiller : 1- Recopier l’octet saisi par l’utilisateur dans une liste. 2- Comparer chaque bit, rang par rang. Si le bit de rang 0 est égal à 1, le changer à 0 et marquer la retenue à Vraie. Si le bit de rang 0 est égal à 0, le changer à 1 et garder les autres intacts. 3- Si la retenue est Vraie tester les bit de rang suivant, les uns après les autres tant que la retenue est Vraie. 4- Recopie du résultat dans un string que l’on affichera en appelant la fonction plus_un()
Exercice 4
Ecrire un programme qui permet de convertir les nombres entiers en binaire signé en complément à 2 (en 8 bits) . 1- Adapter la fonction decimal_vers_binaire() de l’exercice 1 afin de convertir le nombre binaire en décimal (sur 7 bits). 2- Créer une fonction inversion() qui prend en argument le nombre binaire convertit précédemment et renvoi le résultat d’une inversion bit à bit. 3- Utiliser la fonction plus_un() de l’exercice 3 avec comme argument le nombre binaire renvoyé par la fonction inversion() et renvoi le résultat de l’addition de ce dernier avec 1. Enfin, imprimer à l’écran le résultat et vérifier la justesse de ce dernier.
À la « préhistoire » des systèmes d’exploitation, ces derniers étaient dépourvus d’interface graphique (système de fenêtres
« pilotables » à la souris),
toutes les interactions « système d’exploitation – utilisateur » se faisaient par l’intermédiaire de « lignes de commandes »
(suites de caractères, souvent ésotériques, saisies par l’utilisateur). Aujourd’hui,
même si les interfaces graphiques modernes permettent d’effectuer la plupart des opérations,
il est important de connaitre quelques-unes de ces lignes de commandes.
Nous allons utiliser une clé Freeduc-JBART, cette clé est basée sur Debian-Live , ce qui nous permettra de travailler sous Linux .
Pour saisir des lignes de commandes, nous allons utiliser une console (aussi appelé terminal même si ce n’est pas exactement la même chose).
À faire vous-même 1
Après avoir démarrer sur votre clé Freeduc-JBART
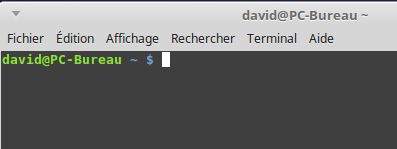
Ouvrez une console, vous devriez avoir quelque chose qui ressemble à cela :
console système GNU/Linux
Nous avons ci-dessus la console de l’utilisateur « david » qui utilise
un ordinateur qui se nomme « PC-Bureau » (« david@PC-Bureau »).
Principalement nous allons, grâce à la ligne de commande, travailler
sur les fichiers et les répertoires. Dans les systèmes de type « UNIX »
(par exemple GNU/Linux ou macOS),
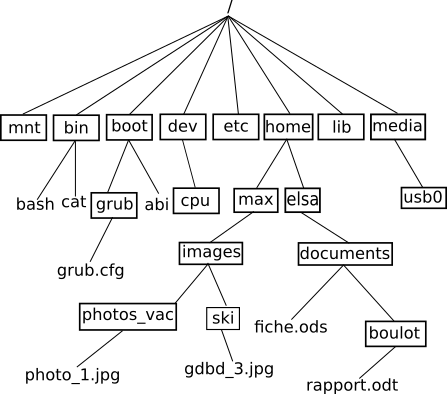
nous avons un système de fichier en arborescence :
système de fichiers
Dans le schéma ci-dessus on trouve des répertoires (noms entourés
d’un rectangle, exemple : « home ») et des fichiers (uniquement des noms
« grub.cfg »).
À noter : les extensions des noms de fichiers, par exemple le « cfg »
de « grub.cfg », ne sont pas obligatoires dans les systèmes de type
« UNIX », par exemple, « bash » est bien un nom de fichier et il n’a pas
d’extension.
On parle d’arborescence, car ce système de fichier ressemble à un arbre à l’envers.
Comme vous pouvez le constater, la base de l’arbre s’appelle la racine de l’arborescence et se représente par un « / »
Chemin absolu ou chemin relatif ?
Pour indiquer la position d’un fichier (ou d’un répertoire) dans l’arborescence, il existe 2 méthodes :
indiquer un chemin absolu ou indiquer un chemin relatif. Le chemin absolu doit indiquer « le chemin » depuis la racine.
Par exemple le chemin absolu du fichier fiche.ods sera : /home/elsa/documents/fiche.ods
Remarquez que nous démarrons bien de la racine / (attention les symboles de séparation sont aussi des /)
Il est possible d’indiquer le chemin non pas depuis la racine,
mais depuis un répertoire quelconque, nous parlerons alors de chemin
relatif :
Le chemin relatif permettant d’accéder au fichier « photo_1.jpg »
depuis le répertoire « max » est : « images/photo_vac/photo_1.jpg »
Remarquez l’absence du / au début du chemin (c’est cela qui nous permettra de distinguer un chemin relatif et un chemin absolu).
Imaginons maintenant que nous désirions indiquer le chemin relatif
pour accéder au fichier « gdbd_3.jpg » depuis le répertoire « photos_vac ».
Comment faire ?
Il faut « remonter » d’un « niveau » dans l’arborescence pour se retrouver dans le répertoire « images » et ainsi
pouvoir repartir vers la bonne « branche ». Pour ce faire il faut utiliser 2 points : ..
« ../ski/gdbd_3.jpg »
Il est tout à fait possible de remonter de plusieurs « crans » :
« ../../ » depuis le répertoire « photos_vac » permet de « remonter » dans le
répertoire « max »
À faire vous-même 2
En vous basant sur l’arborescence ci-dessus, déterminez le chemin absolu permettant d’accéder au fichier :
« cat »
« rapport.odt »
Toujours en vous basant sur l’arborescence ci-dessus, déterminez le chemin relatif permettant d’accéder au fichier :
« rapport.odt » depuis le répertoire « elsa »
« fiche.ods » depuis le répertoire « boulot »
Comme déjà évoqué plus haut, les systèmes de type « UNIX » sont des
systèmes « multi-utilisateurs » : chaque utilisateur possède son propre
compte.
Chaque utilisateur possède un répertoire à son nom, ces répertoires
personnels se situent traditionnellement dans le répertoire « home ». Dans
l’arborescence ci-dessus, nous avons 2 utilisateurs : « max » et « elsa ».
Par défaut, quand un utilisateur ouvre une console, il se trouve
dans son répertoire personnel. Dans l’image de la console ci-dessus,
nous avons un « david@PC-Bureau ~ $ » (au passage, on appelle cela
« l’invite de commande »), le « ~ » (caractère « tilde ») signifie
que l’on se trouve actuellement dans le répertoire personnel de
l’utilisateur courant, autrement dit dans le répertoire de chemin absolu
« /home/david » (puisque l’utilisateur courant est « david »). Le
répertoire « où l’on se trouve actuellement » est appelé « répertoire
courant ».
L’invite de commande vous indique à tout moment le répertoire
courant : « david@PC-Bureau ~/Documents $ » vous indique que vous êtes
dans le répertoire « Documents » qui se trouve dans le répertoire « david »
qui se trouve dans le répertoire « home » (chemin absolu :
« /home/david/Documents »)
Attention : les systèmes de type « UNIX » sont « sensibles à la casse »
(il faut différencier les caractères majuscules et les caractères
minuscules) : le répertoire « Documents » et le répertoire « documents »
sont 2 répertoires différents.
La commande cd
Signification : list
La commande « cd » permet de changer le répertoire courant. Il suffit d’indiquer le chemin (relatif ou absolu) qui permet d’atteindre le nouveau répertoire :
Par exemple (en utilisant l’arborescence ci-dessus) :
si le répertoire courant est le répertoire « elsa » et que vous
« voulez vous rendre » dans le répertoire « documents », il faudra saisir la
commande : « cd documents » (relatif) ou « cd /home/elsa/documents »
(absolu)
si le répertoire courant est le répertoire « photos_vac » et que vous
« voulez vous rendre » dans le répertoire « ski », il faudra saisir la
commande : « cd ../ski » (relatif) ou « cd /home/max/images/ski » (absolu)
si le répertoire courant est le répertoire « boulot » et que vous
« voulez vous rendre » dans le répertoire « documents », il faudra saisir la
commande : « cd .. » (relatif) ou « cd /home/elsa/documents » (absolu)
À faire vous-même 3
Toujours en utilisant l’arborescence ci-dessus, quelle est la
commande à saisir si le répertoire courant est le répertoire « home » et
que vous « voulez vous rendre » dans le répertoire « boulot » (vous
utiliserez d’abord un chemin absolu puis un chemin relatif)
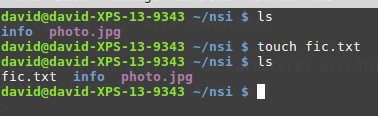
La commande ls
Signification : list
La commande « ls » permet de lister le contenu du répertoire courant.
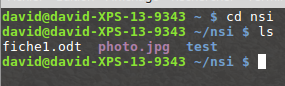
Dans l’exemple ci-dessus, depuis le répertoire personnel de
l’utilisateur « david », nous passons dans le répertoire « nsi » à l’aide
d’un « cd nsi », puis nous affichons le contenu de ce répertoire « nsi » à
l’aide de la commande « ls ». Nous trouvons dans le répertoire « nsi » :
2 fichiers (« fiche1.odt » et « photo.jpg ») et un répertoire (« test »).
À faire vous-même 4
Après avoir ouvert une console, utilisez la commande ls depuis votre répertoire personnel.
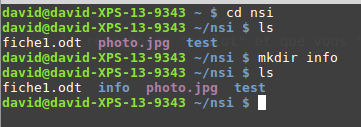
La commande « mkdir »
Signification : make directory
La commande « mkdir » permet de créer un répertoire dans le répertoire courant. La commande est de la forme « mkdir nom_du_répertoire »
Remarque : il est préférable de ne pas utiliser de caractères
accentués dans les noms de répertoire (ou de fichier). Il en est de même
pour les espaces
(à remplacer par des caractères tirets bas « _ »)
La commande man
Signification : manual
Affiche les pages du manuel système. Chaque argument donné à man est généralement le nom d’un programme, d’un utilitaire, d’une fonction ou d’un fichier spécial. Exemples d’utilisation :
man man affiche les informations pour l’utilisation de man
man mkdir affiche les informations pour l’utilisation de mkdir
‘q’ pour quitter.
À faire vous-même 5
Après avoir ouvert une console, utilisez la commande « mkdir » afin de
créer un répertoire « test_nsi » dans votre répertoire personnel.
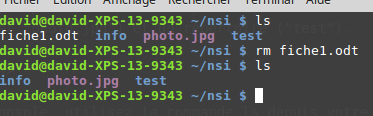
La commande « rm »
Signification : remove
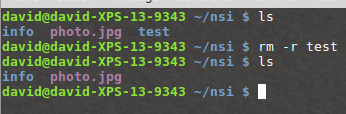
La commande « rm » permet de supprimer un fichier ou un répertoire. La commande est de la forme « rm nom_du_répertoire_ou_nom_du_fichier »
La plupart des commandes UNIX peuvent être utilisées avec une ou des options. Par exemple, pour supprimer un répertoire non vide, il est nécessaire d’utiliser la commande « rm » avec l’option « -r » : « rm -r nom_du_répertoire »
Attention si vous utilisez la commande « rm * » cela supprime tous les fichiers présent dans le répertoire courant.
A noter que pour afficher le répertoire courant il existe une fonction « pwd », même s’il est spécifié sur le terminal en bleu…
La commande « touch »
La commande « touch » permet de créer un fichier vide. La commande est de la forme « touch nom_du_fichier_à_créer »
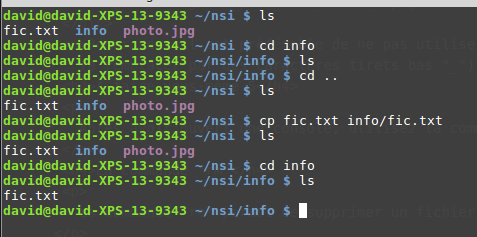
La commande « cp »
Signification : copy
La commande « cp » permet de copier un fichier. La commande est de la forme « cp /répertoire_source/nom_fichier_à_copier /répertoire_destination/nom_fichier »
À noter : le nom du fichier « destination » n’est pas obligatoirement
le même que le nom du fichier « source » (on peut avoir « cp fic.txt
info/fiche.txt »)
La commande « mv »
Signification : move
la commande « mv » permet de déplacer ou renommer des fichiers et des répertoires Options les plus fréquentes :
-f : Écrase les fichiers de destination sans confirmation
-i : Demande confirmation avant d’écraser
-u : N’écrase pas le fichier de destination si celui-ci est plus récent
Exemples d’utilisation :
mv monFichier unRep/ Déplace monFichier dans le répertoire unRep
mv unRep/monFichier . Déplace le fichier monFichier du répertoire unRep là où on se trouve
mv unRep monRep Renomme unRep en monRep
À faire vous-même 6
Placez-vous dans le répertoire « test_nsi » créé au « À faire vous-même 5 ». Créez un fichier « test.txt » avec du texte à l’intérieur.
Saisir la commande « cat test.txt » que se passe t’il?
Créez un répertoire « doc ». Copiez le fichier « test.txt » dans le répertoire « doc ». Effacez le répertoire doc (et son contenu).
Gestion des utilisateurs et des groupes
Les systèmes de type « UNIX » sont des systèmes multi-utilisateurs,
plusieurs utilisateurs peuvent donc partager un même ordinateur, chaque
utilisateur possédant un environnement
de travail qui lui est propre.
Chaque utilisateur possède certains droits lui permettant
d’effectuer certaines opérations et pas d’autres. Le système
d’exploitation permet de gérer ces droits très finement.
Un utilisateur un peu particulier est autorisé à modifier tous les
droits : ce « super utilisateur » est appelé « administrateur » ou « root ».
L’administrateur pourra donc attribuer ou retirer
des droits aux autres utilisateurs.
Au lieu de gérer les utilisateurs un par un, il est possible de créer
des groupes d’utilisateurs. L’administrateur attribue des droits à un
groupe au lieu d’attribuer des droits
particuliers à chaque utilisateur.
Comme nous venons de le voir, chaque utilisateur possède des droits
qui lui ont été octroyés par le « super utilisateur ». Nous nous
intéresserons ici uniquement aux droits liés aux
fichiers, mais vous devez savoir qu’il existe d’autres droits liés
aux autres éléments du système d’exploitation ((imprimante, installation
de logiciels…).
Les fichiers et les répertoires possèdent 3 types de droits :
les droits en lecture (symbolisés par la lettre r) : est-il possible de lire le contenu de ce fichier
les droits en écriture (symbolisés par la lettre w) : est-il possible de modifier le contenu de ce fichier
les droits en exécution (symbolisés par la lettre x) : est-il
possible d’exécuter le contenu de ce fichier (quand le fichier du code
exécutable)
Il existe 3 types d’utilisateurs pour un fichier ou un répertoire :
le propriétaire du fichier (par défaut c’est la personne qui a créé le fichier), il est symbolisé par la lettre u
un fichier est associé à un groupe, tous les utilisateurs
appartenant à ce groupe possèdent des droits particuliers sur ce
fichier. Le groupe est symbolisé par la lettre g
tous les autres utilisateurs (ceux qui ne sont pas le propriétaire
du fichier et qui n’appartiennent pas au groupe associé au fichier).
Ces utilisateurs sont symbolisés
la lettre « o »
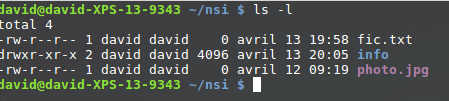
Il est possible d’utiliser la commande « ls » avec l’option « -l » afin d’avoir des informations supplémentaires.
Prenons la première ligne :
-rw-r--r-- 1 david david 0 avril 13 19:58 fic.txt
Lisons cette ligne de gauche à droite :
le premier symbole « – » signifie que l’on a affaire à un fichier,
dans le cas d’un répertoire, nous aurions un « d » (voir la 2e ligne)
les 3 symboles suivants « rw-« donnent les droits du propriétaire du
fichier : lecture autorisée (r), écriture autorisée (w), exécution
interdite (- à la place de x)
les 3 symboles suivants « r–« donnent les droits du groupe lié au
fichier : lecture autorisée (r), écriture interdite (- à la place de w),
exécution
interdite (- à la place de x)
les 3 symboles suivants « r–« donnent les droits des autres
utilisateurs : lecture autorisée (r), écriture interdite (- à la place
de w), exécution
interdite (- à la place de x)
le caractère suivant « 1 » donne le nombre de liens (nous n’étudierons pas cette notion ici)
le premier « david » représente le nom du propriétaire du fichier
le second « david » représente le nom du groupe lié au fichier
le « 0 » représente la taille du fichier en octet (ici notre fichier est vide)
« avril 13 19:58 » donne la date et l’heure de la dernière modification du fichier
« fic.txt » est le nom du fichier
Prenons la deuxième ligne :
drwxr-xr-x 2 david david 4096 avril 13 20:05 info
Lisons cette ligne de gauche à droite :
le premier symbole « d » signifie que l’on a un répertoire
les 3 symboles suivants « rwx »donnent les droits du propriétaire
du répertoire : lecture du contenu du répertoire autorisée (r),
modification du contenu du répertoire autorisée (w),
il est possible de parcourir le répertoire (voir le contenu du
répertoire) (x)
les 3 symboles suivants « r-x »donnent les droits du groupe lié au
répertoire : modification du contenu du répertoire interdite (- à la
place de w)
les 3 symboles suivants « r-x »donnent les droits des autres
utilisateurs : modification du contenu du répertoire interdite (- à la
place de w)
le caractère suivant « 2 » donne le nombre de liens (nous n’étudierons pas cette notion ici)
le premier « david » représente le nom du propriétaire du répertoire
le second « david » représente le nom du groupe lié au répertoire
le « 4096 » représente la taille du répertoire en octets
« avril 13 20:05 » donne la date et l’heure de la dernière modification du contenu du répertoire
« info » est le nom du répertoire
À faire vous-même 7
Analysez la 3e ligne du résultat de la commande « ls -l » ci-dessus
Il est important de ne pas perdre de vu que l’utilisateur « root » a
la possibilité de modifier les droits de tous les utilisateurs.
Le propriétaire d’un fichier peut modifier les permissions d’un
fichier ou d’un répertoire à l’aide de la commande « chmod ». Pour
utiliser cette commande, il est nécessaire de connaitre certains
symboles :
les symboles liés aux utilisateurs : « u » correspond au
propriétaire, « g » correspond au groupe lié au fichier (ou au
répertoire), « o » correspond aux autres utilisateurs et « a » correspond à
« tout le monde » (permet de modifier « u », « g » et « o » en même temps)
les symboles liés à l’ajout ou la suppression des permissions : « + »
on ajoute une permission, « – » on supprime une permission, « = » les
permissions sont réinitialisées (permissions par défaut)
les symboles liés aux permissions : « r » : lecture, « w » : écriture, « x » : exécution.
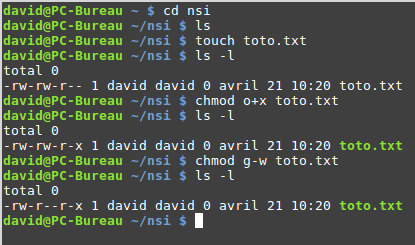
La commande « chmod » à cette forme :
chmod [u g o a] [+ - =] [r w x] nom_du_fichier
par exemple
chmod o+w toto.txt
attribuera la permission « écriture » pour le fichier « toto.txt » « aux autres utilisateurs »
Il est possible de combiner les symboles :
chmod g-wx toto.txt
La commande « chmod » ci-dessus permet de supprimer la permission
« écriture » et la permission « exécution » pour le fichier « toto.txt » « au
groupe lié au fichier »
Une fois de plus, « root » a tous les droits sur l’ensemble des fichiers
et des répertoires, il peut donc utiliser la commande « chmod » sur tous
les répertoires et tous les fichiers.
À faire vous-même 8
Analysez attentivement l’enchainement de commandes suivantes :
À faire vous-même 9
Créez un répertoire « test_nsi2 » dans votre répertoire personnel.
Placez-vous dans le répertoire « test_nsi2 ». Créez un fichier « titi.txt »,
vérifiez les permissions associées à ce fichier. Modifiez les
permissions associées au fichier « titi.txt » afin que les « autres
utilisateurs » aient la permission « écriture »
On se propose dans cette activité de traiter des données issues d’un fichier csv récupéré sur le site Strava afin de les filtrer dans un nouveau fichier. Le fichier de données de départ se nomme « liste_origine.csv ».
Il faudra écrire 5 fonctions : • « import_lignes » avec en argument le fichier de données de départ et qui renvoie une liste des lignes contenues dans le fichier. • « Separe_lignes » avec en argument la liste précédente et qui renvoie la liste avec les lignes séparées. • « creation_liste » qui créera la liste voulue en enlevant les champs inutiles. • « classement_annee » permettra de ne garder que les lignes de l’année courante. • « nouveau_fichier » qui écrira les lignes de l’année dans un nouveau fichier créé pour l’occasion.
Activité 1 : Présentation et découverte du format csv
Strava est un site qui est utilisé pour enregistrer des activités sportives. Les membres du site peuvent partager leurs activités préalablement enregistrées via GPS. En cyclisme et en course à pied, il existe des segments de route chronométrés où les athlètes peuvent se concurrencer. Nous travaillerons sur un fichier contenant les performances d’une montée du Mont-Ventoux, réalisée en cyclisme. Les données sont alors disponibles et téléchargeables dans un fichier au format csv. Un fichier csv est un fichier texte, représentant des données tabulaires sous forme de valeurs séparées par des virgules, tabulations ou points-virgules. Les lignes sont séparées par un retour à la ligne matérialisé par un « \n ».
Dans notre cas, ouvrir le fichier « liste_origine.csv » avec un éditeur de texte, et indiquer quel est le séparateur utilisé : Séparateur : ? Quels champs (étiquettes des colonnes) contient-il ? ? Nous souhaitons traiter ce fichier, en ne gardant uniquement que les performances de l’année en cours et en séparant le nom du prénom car dans le champ « nom » il y a les 2, mais également en supprimant les champs qui ne nous intéressent pas (« Vitesse », « HR », « Puissance », « Vit. Ascens. » et « Temps ») Pour cela, il faudra dans un premier temps récupérer les lignes contenues dans le fichier de départ et les placer dans une liste exploitable.
Activité 2 : Récupération des lignes du fichier de départ
Écrire une fonction « import_lignes » qui prend en argument un nom de fichier (on testera avec le nôtre « liste_origine.csv ») et qui renvoie la liste des lignes du fichier, c’est-à-dire une liste de chaînes de caractères, où chaque élément de la liste correspond à une ligne du fichier. Il faudra bien penser à fermer le fichier avant de faire le return ! Tester votre fonction en affichant le résultat de la liste créée.
Écrire une fonction « separe_lignes » qui prend en argument une chaine de caractère et qui renvoie une liste contenant les chaînes de caractères correspondants aux champs de notre fichier.
(par exemple: separe_lignes(’28;David POLVERONI;21/09/2012;17,7km/h;166bpm;300W;1368,0;01:05:56;3956\n’) renvoie une liste =[’28’, ‘David POLVERONI’, ’21/09/2012′, ‘17,7km/h’, ‘166bpm’, ‘300W’, ‘1368,0’, ’01:05:56′, ‘3956’] Elle sera obtenue en séparant la ligne le long des points-virgules. Pour cela, aidez-vous de la propriété « chaine_caractere.strip » qui permet d’enlever un éventuel \n (retour à la ligne) et/ou des espaces à la fin de la chaine de caractère, ainsi que de la propriété » chaine_caractere .split(« ; ») » qui sépare la ligne à chaque fois qu’un point-virgule est rencontré…
aide sur les méthodes s’appliquant au string w3schools
Activité 4 : Création d’un dictionnaire dico_coureur
Écrire une fonction « creation_dico » qui prend en argument une ligne (chaîne de caractères) et qui renvoie un dictionnaire correspondant au cycliste de la ligne, en omettant les champs non retenus (« Vitesse », « HR », « Puissance », « Vit. Ascens. » et « Temps »)… Exemple de résultat : creation_dico(‘2;Romain Bardet;17/06/2019;19,9km/h;-;-;1\xa0539,7;00:58:35;3515\n’) doit renvoyer : {‘classement’: ‘2’, ‘nomcomplet’: ‘Romain Bardet’, ‘date’: ’17/06/2019′, ‘temps_s’: ‘3515’} , si vous voulez séparer la clé nomcomplet en deux clé prenom et nom.
Activité 5 : Création d’une liste de dictionnaire
Écrire une fonction « liste_perf » qui prend en argument un nom de fichier et qui renvoie une liste de dictionnaire des performances correspondant aux lignes du fichier ( en omettant la première ligne).
Exemple de résultat: liste_perf (‘liste_origine.csv’) doit renvoyer : une liste de dictionnaire:
Écrire une fonction « classement_annee » qui prend en argument la liste de dictionnaire précédemment créée et qui renvoie une nouvelle liste contenant uniquement les performances de l’année 2019. Pour cela, vous devrez vous aider de la liste créer lors de l’activité précédente , pour rechercher l’année dans la date vous devrez utiliser la propriété .split(‘/’), vue précédemment ! Exemple de résultat : classement_annee([{‘classement’: ‘1’, ‘prenom’: ‘Laurens’, ‘nom’: ‘ten’, ‘date’: ’14/07/2013′, ‘temps_s’: 3497}, {‘classement’: ‘2’, ‘prenom’: ‘Romain’, ‘nom’: ‘Bardet’, ‘date’: ’17/06/2019′, ‘temps_s’: 3515}])
Si vous voulez vous pouvez ajouter l’année de tri en argument, et trié ainsi en fonction de l’année donnée en argument.
Pour aller plus loin : Écriture dans un nouveau fichier
On souhaite enfin réécrire tous ces résultats dans un nouveau fichier « classement_2019.csv ». Pour cela, écrire une fonction « nouveau_fichier » qui prend en argument la liste précédente et qui va l’écrire ligne à ligne dans le fichier « classement_2019.csv » en insérant des points-virgules entre les champs. La première ligne du fichier devra être : » ‘classement;prenom;nom;date;temps_s;’+’\n’ «
Dans cet exercice, nous allons gérer un stock de fruits qui sera
représenté par un dictionnaire, dont les clés seront les noms de
fruits (au singulier), et les valeurs seront le nombre de fruits
correspondant dans le stock. Par exemple, si le stock contient 2
pommes et 6 bananes, il sera représenté par le dictionnaire
suivant: {‘pomme’ : 2,
‘banane’ : 6}. Pour simplifier l’écriture des exemples, on
supposera que ce dictionnaire sera stocké dans une variable
appelée stock.
Dans tout l’exercice, le(s) dictionnaire(s) passé(s) en argument
ne doi(ven)t pas être modifié(s).
Vous n’êtes pas obligés de traiter les questions dans l’ordre.
Ecrire une fonction ajoute1 qui prend en argument un stock (dictionnaire) et un nom de fruit, et qui renvoie le nouveau stock, dans lequel un fruit du type donné a été ajouté. Test:
Ecrire une fonction enleve1 qui prend en argument un stock (dictionnaire) et un nom de fruit, et qui renvoie le nouveau stock, où un fruit du type donné a été enlevé (s’il y avait un stock suffisant). Si le stock de ce fruit tombe à zéro, il faut enlever la clé du dictionnaire. Si le stock n’était pas suffisant, le programme affichera « Erreur: quantité insuffisante de (*nom du fruit*) » et renverra le stock initial non modifié. Test:
enleve1(stock , 'poire') affiche « Erreur: Quantité insuffisante de poire » et renvoie {‘pomme’ : 2, ‘banane’ : 6}
Ecrire une fonction ajoute qui prend en argument un stock (dictionnaire), un nom de fruit et une quantité q, et qui renvoie le nouveau stock, dans lequel on a ajouté une quantité q du type de fruit précisé. Test:
Ecrire une fonction enleve qui prend en argument un stock (dictionnaire), un nom de fruit et une quantité q, et qui renvoie le nouveau stock où l’on a enlevé la quantité q du type de fruit précisé. De même que pour la fonction enleve1, si le stock de ce fruit tombe à zéro, il faut enlever la clé du dictionnaire. Si le stock n’était pas suffisant, le programme affichera « Erreur: quantité insuffisante de (*nom du fruit*) » et renverra le stock initial non modifié. Test:
enleve(stock , 'pomme', 2) renvoie {'banane' : 6}
enleve(stock , 'banane', 10) affiche « Erreur: Quantité insuffisante de banane » et renvoie {‘pomme’ : 2, ‘banane’ : 6}
Ecrire une fonction apres_livraison qui prend en argument un stock (dictionnaire) ainsi que le contenu de la livraison (représenté aussi par un dictionnaire) et qui renvoie le nouveau stock après la livraison. Test:
Ecrire une fonction commande qui prend en argument le stock actuel (dictionnaire) ainsi que le stock minimum voulu (dictionnaire aussi) et qui renvoie le dictionnaire correspondant à la commande qu’il faut faire pour obtenir le stock voulu. Si le fruit apparaît déjà en quantité suffisante dans le stock actuel (supérieure ou égal au stock voulu), il ne doit pas apparaître dans la commande. Test:
En supposant que stock_voulu={'pomme': 15, 'orange': 20}, alors commande(stock , stock_voulu) renvoie {‘pomme’ : 13, ‘orange’ : 20}.
En supposant que stock_voulu={'pomme': 10, 'banane': 4}, alors commande(stock , stock_voulu) renvoie {‘pomme’ : 8}.
Ecrire une fonction total qui prend en argument le stock et qui renvoie le nombre total de fruits présents dans le stock (tous types confondus) Test:
total(stock) renvoie 8.
Ecrire une fonction quantite qui prend en argument le stock ainsi qu’une liste de noms de fruits fruits_a_compter, et qui renvoie la quantité de fruits présents dans le stock dont le nom est dans la liste fruits_a_compter. Test:
En supposant que stock_bis={'pomme': 15, 'peche': 4, 'citron': 3, 'orange': 20}, alors quantite(stock_bis , ['pomme', 'citron', 'poire']) renvoie 18.
Ecrire une fonction quantite_agrumes qui prend en argument le stock et qui renvoie la quantité d’agrumes présents dans le stock. Seront considérés comme noms d’agrumes: orange, citron, mandarine, clémentine (sans accent dans le code) et pamplemousse. Test:
En supposant que stock_bis={'pomme': 15, 'peche': 4, 'citron': 3, 'orange': 20}, alors quantite_agrumes(stock_bis) renvoie 23.
vous avez bien sûr le droit de définir des fonctions intermédiaires qui ne sont pas demandées, lorsque vous jugez cela pertinent. Lisez l’énoncé en entier avant de commencer pour repérer les éventuelles opérations qui se répètent souvent.
dans cet exercice, vous avez souvent besoin de convertir un mot en liste de lettres. Pour cela, il faut utiliser list(…) comme dans l’exemple suivant: list(‘oui’) vaut [‘o’, ‘u’, ‘i’].
on suppose que tous les mots considérés dans cet exercice ne contiennent que des lettres, sans accents et en minuscule (pas de caractères spéciaux, tirets, espaces, etc…)
1) Ecrire une fonction commence_par prenant en
argument une lettre et un mot et qui renvoie True
si le mot commence par la lettre donnée en argument, False
sinon.
Test:
commence_par('h', 'hello') vaut True
mais commence_par('e', 'roue') vaut False.
2) Ecrire une fonction contient_voyelle qui prend
en argument un mot et qui renvoie True
si le mot contient une voyelle, False
sinon.
3) Ecrire une fonction derniere_consonne qui
prend en argument un mot et qui renvoie deux valeurs de retour:
l’indice de sa dernière consonne ainsi que la dernière consonne
(comme pour les listes, on considérera que l’indice de la première
lettre est zéro). On ne traitera pas le cas problématique où le
mot ne contient pas de consonne.
Test::
derniere_consonne('arrivee') renvoie 4, ‘v’
4) Ecrire une fonction double_consonne qui prend
en argument un mot et qui a deux valeurs de retour: un booléen
valant True si le
mot contient une double consonne (deux fois la même consonne à la
suite), et dans ce cas la deuxième valeur de retour est la consonne
qui est doublée ; s’il n’y a pas de consonne doublée, la
fonction doit renvoyer False
et None. Pour
information: pour simplifier l’exercice, on ne testera pas votre
fonction sur un mot contenant plusieurs double consonnes (par
exemple, ‘successeur’).
Test:
double_consonne('arrivee') vaut True, ‘r’.
double_consonne('bonbon') vaut False, None
double_consonne('reussite') vaut True, ‘s’
5) Ecrire une fonction envers qui prend en
argument une liste li
(attention, pas un mot, contrairement aux autres fonctions de cet
exercice) et qui renvoie une liste obtenue à partir de li
en inversant l’ordre des éléments.
6) Ecrire une fonction palindrome qui prend en
argument un mot et qui renvoie un booléen indiquant si le mot est un
palindrome. Un palindrome est un mot qui reste identique lorsqu’il
est lu de droite à gauche au lieu de l’ordre habituel de gauche à
droite.
Test:
palindrome('ici') vaut True
mais palindrome('aller') vaut False.
7) Ecrire une fonction mot_autorise prenant en
argument un mot et une liste de mots interdits, et qui renvoie True
si le mot est autorisé, et False
si le mot est interdit.
Comme les listes, les dictionnaires permettent de « stocker » des
données. Chaque élément d’un dictionnaire est composé de 2 parties, on
parle de pairs « clé/valeur ». Voici un exemple de dictionnaire :
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
Comme vous pouvez le constater, nous utilisons des accolades {}
pour définir le début et la fin du dictionnaire (alors que nous
utilisons des crochets [] pour les listes et les parenthèses pour les
tuples).
Dans le dictionnaire ci-dessus, « nom », « prenom » et « date de
naissance » sont des clés et « Durand », « Christophe » et « 29/02/1981 » sont
des valeurs.
La clé « nom » est associée à la valeur « Durand », la clé « prenom » est
associée à la valeur « Christophe » et la clé « date de naissance » est
associée à la valeur « 29/02/1981 ».
Les clés sont des chaînes de caractères ou des nombres. Les valeurs
peuvent être des chaînes de caractères, des nombres, des booléens…
Pour créer un dictionnaire, il est aussi possible de procéder comme suit :
La variable « mon_dico » référence un dictionnaire. Il est
possible d’afficher le contenu du dictionnaire référencé par la variable
« mon_dico » en saisissant « mon_dico » dans la console. Faites le test
après avoir exécuté le programme ci-dessous.
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
Il est possible d’afficher la valeur associée à une clé :
À faire vous-même 2
Soit le programme suivant :
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
print(f'Bonjour je suis {mon_dico["prenom"]} {mon_dico["nom"]}, je suis né le {mon_dico["date de naissance"]}')
Quel est le résultat attendu après l’exécution de ce programme ? Vérifiez votre réponse.
Il est facile d’ajouter un élément à un dictionnaire (les dictionnaires sont mutables)
À faire vous-même 3
Soit le programme suivant :
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
print(f'Bonjour je suis {mon_dico["prenom"]} {mon_dico["nom"]}, je suis né le {mon_dico["date de naissance"]}')
mon_dico['lieu naissance'] = "Bonneville"
print (f'à {mon_dico["lieu naissance"]}')
Quel est le résultat attendu après l’exécution de ce programme ? Vérifiez votre réponse.
L’instruction « del » permet du supprimer une paire « clé/valeur »
À faire vous-même 4
Quel est le contenu du dictionnaire référencé par la variable
« mes_fruits » après l’exécution du programme ci-dessous ? Vérifiez votre
réponse à l’aide de la console.
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
del mes_fruits["pomme"]
Quel est le contenu du dictionnaire référencé par la variable
« mes_fruits » après l’exécution du programme ci-dessus ? Vérifiez votre
réponse à l’aide de la console.
Il est possible de parcourir un dictionnaire à l’aide d’une boucle for. Ce parcours peut se faire selon les clés ou les valeurs.
Commençons par parcourir les clés à l’aide de la méthode « keys »
À faire vous-même 6
Tester le programme suivant :
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
print("liste des fruits :")
for fruit in mes_fruits.keys():
print(fruit)
La méthode values() permet de parcourir le dictionnaire selon les valeurs
À faire vous-même 7
Tester le programme suivant :
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
for qte in mes_fruits.values():
print(qte)
Enfin, il est possible de parcourir un dictionnaire à la fois sur les clés et les valeurs en utilisant la méthode items().
À faire vous-même 8
Tester le programme suivant :
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
print ("Stock de fruits :")
for fruit, qte in mes_fruits.items():
print (f"{fruit} : {qte}")
Vous avez sans doute remarqué l’utilisation de deux variables (« fruit » et « qte ») au niveau du « for…in »
Voici ci dessous des slides sur les dictionnaires réalisés par:–Amir Charif–Lydie Du Bousquet–Aurélie Lagoutte–Julie Peyre–Florence Thiard
Il est possible de « stocker » plusieurs grandeurs dans une même
structure, ce type de structure est appelé une séquence. De façon plus
précise, nous définirons une séquence comme un ensemble fini et ordonné
d’éléments indicés de 0 à n-1 (si cette séquence comporte n éléments).
Rassurez-vous,
nous reviendrons ci-dessous sur cette définition. Nous allons étudier
plus particulièrement 2 types de séquences : les tuples et les tableaux
(il en existe d’autres que nous n’évoquerons pas ici).
Les tuples en Python
Comme déjà dit ci-dessus, un tuple est une séquence. Voici un exemple très simple :
mon_tuple = (5, 8, 6, 9)
Dans le code ci-dessus, la variable « mon_tuple » référence un tuple,
ce tuple est constitué des entiers 5, 8, 6 et 9. Comme indiqué dans la
définition, chaque élément du tuple est indicé (il possède un indice):
le premier élément du tuple (l’entier 5) possède l’indice 0
le deuxième élément du tuple (l’entier 8) possède l’indice 1
le troisième élément du tuple (l’entier 6) possède l’indice 2
le quatrième élément du tuple (l’entier 9) possède l’indice 3
Comment accéder à l’élément d’indice i dans un tuple ?
Simplement en utilisant la « notation entre crochets » :
À faire vous-même 1
Testez le code suivant :
mon_tuple = (5, 8, 6, 9)
a = mon_tuple[2]
Quelle est la valeur référencée par la variable a (utilisez la console pour répondre à cette question)?
La variable mon_tuple référence le tuple (5, 8, 6, 9), la variable a
référence l’entier 6 car cet entier 6 est bien le troisième élément du
tuple, il possède donc l’indice 2
ATTENTION : dans les séquences les indices commencent toujours à 0
(le premier élément de la séquence a pour indice 0), oublier cette
particularité est une source d’erreur « classique ».
À faire vous-même 2
Complétez le code ci-dessous (en remplaçant les ..) afin qu’après
l’exécution de ce programme la variable a référence l’entier 8.
mon_tuple = (5, 8, 6, 9)
a = mon_tuple[..]
Un tuple ne contient pas forcément des nombres entiers, il peut aussi
contenir des nombres décimaux, des chaînes de caractères, des
booléens…
À faire vous-même 3
Quel est le résultat attendu après l’exécution de ce programme ?
Grâce au tuple, une fonction peut renvoyer plusieurs valeurs :
À faire vous-même 4
Analysez puis testez le code suivant :
def add(a, b):
c = a + b
return (a, b, c)
mon_tuple = add(5, 8)
print(f"{mon_tuple[0]} + {mon_tuple[1]} = {mon_tuple[2]}")
Il faut bien comprendre dans l’exemple ci-dessus que la variable
mon_tuple référence un tuple (puisque la fonction « add » renvoie un
tuple), d’où la « notation entre crochets » utilisée avec mon_tuple
(mon_tuple[1]…)
La console permet d’afficher les éléments présents dans un tuple simplement en :
À faire vous-même 5
Après avoir exécuté le programme ci-dessous, saisissez mon_tuple dans la console.
mon_tuple = (5, 8, 6, 9)
Il est possible d’assigner à des variables les valeurs contenues dans un tuple :
À faire vous-même 6
a, b, c, d = (5, 8, 6, 9)
Quelle est la valeur référencée par la variable a ? La variable b ?
La variable c ? La variable d ? Vérifiez votre réponse à l’aide de la
console Python.
Les tableaux ou liste en Python
ATTENTION : Dans la suite nous allons employer le terme « tableau ».
Pour parler de ces « tableaux » les concepteurs de Python ont choisi
d’utiliser le terme de « list » (« liste » en français). Pour éviter toute
confusion,
notamment par rapport à des notions qui seront abordées en terminale,
le choix a été fait d’employer « tableau » à la place de « liste » (dans la
documentation vous rencontrerez le terme « list », cela ne devra pas vous
pertuber)
Il n’est pas possible de modifier un tuple après sa création (on parle
d’objet « immutable »), si vous essayez de modifier un tuple existant,
l’interpréteur Python vous renverra une erreur.
Les tableaux sont,comme les tuples, des séquences, mais à la
différence des tuples, ils sont modifiables (on parle d’objets
« mutables »).
Pour créer un tableau, il existe différentes méthodes : une de ces méthodes ressemble beaucoup à la création d’un tuple :
mon_tab = [5, 8, 6, 9]
Notez la présence des crochets à la place des parenthèses.
Un tableau est une séquence, il est donc possible de « récupérer » un
élément d’un tableau à l’aide de son indice (de la même manière que pour
un tuple)
À faire vous-même 7
Quelle est la valeur référencée par la variable ma_variable après
l’exécution du programme ci-dessous ? (utilisez la console pour vérifier
votre réponse)
mon_tab = [5, 8, 6, 9]
ma_variable = mon_tab[2]
N.B. Il est possible de saisir directement mon_tab[2] dans la console
sans passer par l’intermédiaire de la variable ma_variable
Il est possible de modifier un tableau à l’aide de la « notation entre crochets » :
À faire vous-même 8
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
mon_tab[2] = 15
Comme vous pouvez le constater avec l’exemple ci-dessus, l’élément
d’indice 2 (le nombre entier 6) a bien été remplacé par le nombre entier
15
Il est aussi possible d’ajouter un élément en fin de tableau à l’aide de la méthode « append » :
À faire vous-même 9
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
mon_tab.append(15)
L’instruction « del » permet de supprimer un élément d’un tableau en utilisant son index :
À faire vous-même 10
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
del mon_tab[1]
La fonction « len » permet de connaitre le nombre d’éléments présents dans une séquence (tableau et tuple)
À faire vous-même 11
Quelle est la valeur référencée par la variable nb_ele après l’exécution du programme ci-dessous ? (utilisez la console pour vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
nb_ele = len(mon_tab)
Une petite parenthèse : on pourrait s’interroger sur l’intérêt
d’utiliser un tuple puisque le tableau permet plus de choses ! La
réponse est simple : les opérations
sur les tuples sont plus « rapides ». Quand vous savez que votre
tableau ne sera pas modifié, il est préférable d’utiliser un tuple à la
place d’un tableau.
la boucle « for » : parcourir les éléments d’un tableau
La boucle for… in permet de parcourir chacun des éléments d’une séquence (tableau ou tuple) :
À faire vous-même 12
Analysez puis testez le code suivant :
mon_tab = [5, 8, 6, 9]
for element in mon_tab:
print(element)
Quelques explications : comme son nom l’indique, la boucle « for » est
une boucle ! Nous « sortirons » de la boucle une fois que tous les
éléments du tableau mon_tab auront
été parcourus. element est une variable qui va :
au premier tour de boucle, référencer le premier élément du tableau (l’entier 5)
au deuxième tour de boucle, référencer le deuxième élément du tableau (l’entier 8)
au troisième tour de boucle, référencer le troisième élément du tableau (l’entier 6)
au quatrième tour de boucle, référencer le quatrième élément de le tableau (l’entier 9)
Une chose importante à bien comprendre : le choix du nom de la
variable qui va référencer les éléments du tableau les uns après les
autres (element) est totalement arbitraire,
il est possible de choisir un autre nom sans aucun problème, le code
suivant aurait donné exactement le même résultat :
mon_tab = [5, 8, 6, 9]
for toto in mon_tab:
print (toto)
Dans la boucle for… in il est possible d’utiliser la fonction prédéfinie range à la place d’un tableau d’entiers :
À faire vous-même 13
Analysez puis testez le code suivant :
for element in range(0, 5):
print (element)
Comme vous pouvez le constater, « range(0,5) » est, au niveau de la
boucle « for..in », équivalent au tableau [0,1,2,3,4], le code ci-dessous
donnerait le même résultat que le programme vu dans le « À faire
vous-même 12 » :
mon_tab = [0, 1, 2, 3, 4]
for element in mon_tab:
print (element)
ATTENTION : si vous avez dans un programme « range(a,b) », a est la
borne inférieure et b a borne supérieure. Vous ne devez surtout pas
perdre de vu que la borne inférieure est incluse, mais
que la borne supérieure est exclue.
Il est possible d’utiliser la méthode « range » pour « remplir » un tableau :
À faire vous-même 14
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = []
for element in range(0, 5):
mon_tab.append(element)
Créer un tableau par compréhension
Nous avons vu qu’il était possible de « remplir » un tableau en renseignant les éléments du tableau les uns après les autres :
mon_tab = [5, 8, 6, 9]
ou encore à l’aide de la méthode « append » (voir « À faire vous-même 13 »).
Il est aussi possible d’obtenir exactement le même résultat qu’au « À
faire vous-même 13 » en une seule ligne grâce à la compréhension de
tableau :
À faire vous-même 15
Quel est le contenu du tableau référencée par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [p for p in range(0, 5)]
Les compréhensions de tableau permettent de rajouter une condition (if) :
À faire vous-même 16
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
l = [1, 7, 9, 15, 5, 20, 10, 8]
mon_tab = [p for p in l if p > 10]
Autre possibilité, utiliser des composants « arithmétiques » :
À faire vous-même 17
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
l = [1, 7, 9, 15, 5, 20, 10, 8]
mon_tab = [p**2 for p in l if p < 10]
Rappel : p**2 permet d’obtenir la valeur de p élevée au carrée
Comme vous pouvez le remarquer, nous obtenons un tableau (mon_tab)
qui contient tous les éléments du tableau l élevés au carré à condition
que ces éléments de l soient inférieurs à 10.
Comme vous pouvez le constater, la compréhension de tableau permet
d’obtenir des combinaisons relativement complexes.
Travailler sur des « tableaux de tableaux »
Chaque élément d’un tableau peut être un tableau, on parle de tableau de tableau.
Voici un exemple de tableau de tableau :
m = [[1, 3, 4], [5 ,6 ,8], [2, 1, 3], [7, 8, 15]]
Le premier élément du tableau ci-dessus est bien un tableau ([1, 3,
4]), le deuxième élément est aussi un tableau ([5, 6, 8])…
Il est souvent plus pratique de présenter ces « tableaux de tableaux » comme suit :
m = [[1, 3, 4],
[5, 6, 8],
[2, 1, 3],
[7, 8, 15]]
Nous obtenons ainsi quelque chose qui ressemble beaucoup à un « objet mathématique » très utilisé : une matrice
Il est évidemment possible d’utiliser les indices de position avec
ces « tableaux de tableaux ». Pour cela nous allons considérer notre
tableau de tableaux comme une matrice, c’est à dire
en utilisant les notions de « ligne » et de « colonne ». Dans la matrice
ci-dessus :
En ce qui concerne les lignes :
1, 3, 4 constituent la première ligne
5, 6, 8 constituent la deuxième ligne
2, 1, 3 constituent la troisième ligne
7, 8, 15 constituent la quatrième ligne
En ce qui concerne les colonnes :
1, 5, 2, 7 constituent la première colonne
3, 6, 1, 8 constituent la deuxième colonne
4, 8, 3, 15 constituent la troisième colonne
Pour cibler un élément particulier de la matrice, on utilise la
notation avec « doubles crochets » : m[ligne][colonne] (sans perdre de vu
que la première ligne et la première colonne ont pour indice 0)
À faire vous-même 18
Quelle est la valeur référencée par la variable a après
l’exécution du programme ci-dessous ? (utilisez la console pour vérifier
votre réponse)
m = [[1, 3, 4],
[5, 6, 8],
[2, 1, 3],
[7, 8, 15]]
a = m[1][2]
Comme vous pouvez le constater, la variable a référence bien l’entier
situé à la 2e ligne (indice 1) et à la 3e colonne (indice 2),
c’est-à-dire 8.
À faire vous-même 19
Quel est le contenu du tableau référencé par la variable mm
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
m = [1, 2, 3]
mm = [m, m, m]
m[0] = 100
Comme vous pouvez le constater, la modification du tableau référencé
par la variable m entraine la modification du tableau référencé par la
variable mm (alors que
nous n’avons pas directement modifié le tableau référencé par mm).
Il faut donc être très prudent lors de ce genre de manipulation afin
d’éviter des modifications non désirées.
Il est possible de parcourir l’ensemble des éléments d’une matrice à l’aide d’une « double boucle for » :
À faire vous-même 20
Analysez puis testez le code suivant :
m = [[1, 3, 4],
[5, 6, 8],
[2, 1, 3],
[7, 8, 15]]
nb_colonne = 3
nb_ligne = 4
for i in range(0, nb_ligne):
for j in range(0, nb_colonne):
a = m[i][j]
print(a)
Voici ci dessous des slides sur les listes réalisés par:–Amir Charif–Lydie Du Bousquet–Aurélie Lagoutte–Julie Peyre–Florence Thiard
Vous savez documenter les fonctions à l’aide d’une «chaîne de documentation» (ou «docstring»), c’est-à-dire une chaîne de caractères placée immédiatement après l’en-tête de la fonction. Voici un tel exemple de documentation
def fact(n):
"""
paramètre n : (int) un entier
valeur renvoyée : (int) la factorielle de n.
CU : n >= 0
Exemples :
>>> fact(3)
6
>>> fact(5)
120
"""
res = 1
for i in range(2, n + 1):
res = res * i
return res
Cette documentation peut être exploitée avec la fonction help :
>>> help(fact)
Help on function fact in module __main__:
fact(n)
paramètre n : (int) un entier
valeur renvoyée : (int) la factorielle de n.
CU : n >= 0
Exemples :
>>> fact(3)
6
>>> fact(5)
120
À faire
Utilisez Pyzo pour
recopier la fonction fact avec sa docstring dans un fichier que vous nommerez exples_doctest.py,
et utiliser la fonction help au niveau de l’interpréteur.
Réaliser une telle chaîne de documentation permet
à l’utilisateur de la fonction de savoir
à quoi peut servir la fonction ;
comment il peut l’utiliser ;
et quelles conditions il doit respecter pour l’utiliser (CU).
et au programmeur de la fonction de préciser
le nombre et la nature de ses paramètres ;
la relation entre la valeur renvoyée et celle du ou des paramètres ;
ses idées avec quelques exemples.
(Tout cela bien entendu à condition que cette documentation soit rédigée
avant la réalisation du programme et non le contraire.)
Mais vous allez découvrir que cela permet davantage encore !
Utiliser le module doctest
Les exemples donnés dans une chaîne de documentation peuvent être testés à l’aide d’un module de Python nommé doctest.
À faire
Depuis l’interpréteur (shell), dans lequel la fonction fact ci-dessus est supposée chargée, tapez les deux lignes
La fonction testmod du module doctest est allée chercher dans les docstring des fonctions du module actuellement chargé, c’est-à-dire exples_doctest, tous les exemples (reconnaissables à la présence des triples chevrons >>>), et a vérifié que la fonction documentée satisfait bien ces exemples. Dans le cas présent, une seule fonction dont la documentation contient deux exemples (attempted=2) a été testée, et il n’y a eu aucun échec (failed=0).
Et si un exemple et la fonction ne sont pas d’accord ?
À faire
Modifiez le deuxième exemple, en mettant 121 à la place de 120 dans le second exemple. Chargez le fichier dans l’interpréteur (touche F5) et retapez les deux lignes
>>> import doctest
>>> doctest.testmod()
Vous devez obtenir
>>> doctest.testmod()
**********************************************************************
File "/home/eric/AP1/exples_doctest.py", line 24, in __main__.fact
Failed example:
fact(5)
Expected:
121
Got:
120
**********************************************************************
1 items had failures:
1 of 2 in __main__.fact
***Test Failed*** 1 failures.
Qu’est ce que tout cela révèle ?
Tout d’abord que les tests ont échoué et qu’il y a eu 1 échec (cf dernière ligne) et que cet échec est dû à la fonction fact (cf avant dernière ligne).
Ensuite que le test incriminé est celui concernant fact(5) pour lequel le test a obtenu (Got) 120 en exécutant la fonction fact, alors qu’il attendait (Expected) 121 selon l’exemple donné par la documentation.
Lorsqu’il y a de tels échecs, cela invite le programmeur à vérifier
son programme, … ou bien les exemples de sa documentation, comme c’est
le cas ici.
Rendre automatique les tests
Il est très facile de rendre automatique les tests et ainsi de ne plus avoir à faire appel explicitement (et manuellement) à la fonction testmod.
Il suffit pour cela d’inclure en fin de fichier les trois lignes :
if __name__ == '__main__':
import doctest
doctest.testmod()
À faire
Ajoutez ces trois lignes à la fin du fichier exple_doctest.py
et exécutez-le ! (F5)
Faites le dans le cas d’un test erroné, et dans le cas sans erreur.
Que remarquez-vous dans le cas sans erreur ?
Rendre les doctests bavards même en cas de succès
Un paramètre optionnel de la fonction testmod permet d’obtenir plus d’informations sur les tests effectués mêmes en cas de succès.
Il suffit pour cela de rajouter le paramètre ̀`verbose=True« :
doctest.testmod(verbose = True)
À faire
Faites-le !
Et observez ce que vous obtenez
avec des exemples erronés
sans exemple erroné.
Les sorties complexes
Tester les exemples des docstring avec le module doctest peut être source de déboires et de pièges. Vous allez découvrir certains d’entre eux et les remèdes qu’on peut y apporter.
Avec les listes
Supposez que vous vouliez donner un exemple qui produit la liste
des factorielles des entiers de 0 à 5.
Vous avez donc complété votre documentation en ajoutant
"""
paramètre n : (int) un entier
valeur renvoyée : (int) la factorielle de n.
CU : n >= 0
Exemples :
>>> fact(3)
6
>>> fact(5)
120
La liste des factorielles des entiers de
0 à 5
>>> [fact(n) for n in range(6)]
[1,1,2,6,24,120]
"""
Avertissement
La ligne blanche entre le deuxième exemple et la phrase qui
suit est absolument nécessaire. En son absence, la phrase sera comprise
comme faisant partie de la sortie produite par le deuxième exemple, et
le test échouera donc.
Il est clair que ce nouvel exemple est tout à fait correct.
Pourtant, si vous procédez au test vous constaterez que sur les trois exemples testés, l’un a abouti à un échec : le troisième.
À faire
Faites-le !
Quel est le problème ? Cela vient du fait que la fonction testmode effectue une comparaison litérale entre la réponse fournie par la documentation (Expected ) et celle fournie par l’interpréteur (Got).
À faire
Examinez attentivement ces deux points (Expected et Got) dans la réponse du test que vous venez d’effectuer.
Avez-vous compris ? Le problème, ce sont les espaces que l’interpréteur
place après chaque virgule dans l’énumération des éléments de la liste.
Dans la documentation, ils n’y sont pas.
Comment corriger ce point ?
C’est simple, il faut mettre des espaces entre les éléments d’une liste.
Mais ce n’est pas si simple. On peut facilement mettre plusieurs espaces,
comme ci-dessous :
"""
paramètre n : (int) un entier
valeur renvoyée : (int) la factorielle de n.
CU : n >= 0
Exemples :
>>> fact(3)
6
>>> fact(5)
120
La liste des factorielles des entiers de
0 à 5
>>> [fact(n) for n in range(6)]
[1, 1, 2, 6, 24, 120]
"""
À faire
Faites-le ! Testez !
L’excès d’espaces provoque des erreurs. Si on ajoute, sous forme d’un commentaire la directive #doctest :
+ NORMALIZE WHITESPACE , alors le test réussit, à condition néanmoins d’avoir mis au moins une espace après chaque virgule.
"""
paramètre n : (int) un entier
valeur renvoyée : (int) la factorielle de n.
CU : n >= 0
Exemples :
>>> fact (3)
6
>>> fact (5)
120
La liste des factorielles des entiers de
0 à 5
>>> [fact (n) for n in range (6)]
... # doctest: +NORMALIZE_WHITESPACE
[1, 1, 2, 6, 24, 120]
"""
À faire
Vérifiez-le !
Avertissement
les trois petits points sous les trois chevrons sont indispensables.
Avec la directice supplémentaire +ELLIPSIS , on peut même se dispenser d’énumérer explicitement tous les éléments de la liste :
"""
paramètre n : (int) un entier
valeur renvoyée : (int) la factorielle de n.
CU : n >= 0
Exemples :
>>> fact(3)
6
>>> fact(5)
120
La liste des factorielles des entiers de
0 à 5
>>> [fact(n) for n in range(6)]
... # doctest: +NORMALIZE_WHITESPACE, +ELLIPSIS
[1, ..., 24, 120]
"""
À faire
Vérifiez-le !
Attention aux ensembles et dictionnaires
Contrairement aux listes ou tuples, les ensembles et les dictionnaires ne sont pas des
structures de données séquentielles. Il est impossible de prévoir dans quel
ordre un interpréteur Python écrira les éléments de ces structures.
Par exemple, on peut très bien avoir
>>> {'a', 'b'}
{'a', 'b'}
comme on peut avoir
>>> {'a', 'b'}
{'b', 'a'}
Il est donc difficile d’illustrer une valeur d’un de ces deux types dans un
exemple d’une docstring. Il est préférable de tester l’égalité de deux
valeurs [1] :
>>> {'a', 'b'} == {'b', 'a'}
Voici donc un exemple de ce qu’il est envisageable de placer dans une
docstring
Un dictionnaire de certaines valeurs de fact :
>>> set (n for n in range(5)) == {0, 1, 2, 3, 4}
True
À faire
Vérifiez ce point !
Avec des sorties aléatoires
Comment tester des fonctions qui produisent des valeurs aléatoires ?
Dans l’absolu, il est impossible de placer un exemple dans la docstring
donnant le résultat d’un appel à de telles fonctions puisque les valeurs
qu’elles renvoient sont imprévisibles.
Par exemple si on veut tester qu’une fonction simulant un dé à six faces
ne produit que des nombres compris entre 1 et 6, comment faire ?
On peut si on le souhaite vérifier que cette fonction ne renvoie que des nombres
compris entre 1 et 6.
from random import randrange
def de():
"""
paramètre : aucun
valeur renvoyée : (int) un nombre choisi au hasard compris entre
1 et 6.
CU : aucune
Exemple :
>>> 1 <= de() <= 6
True
"""
return randrange(1,7)
À faire
Concevez un test qui vérifie 100 fois qu’aucun nombre produit par la fonction de n’est en dehors de l’intervalle [1,6]
.
Mais un tel test ne prouve pas que jamais la fonction ne produira un nombre en dehors de
cet intervalle.
Méthodologie
Note
Pour chacun des fichiers de programmes Python que vous écrirez durant
les séances de TP, ainsi que dans la réalisation du projet de fin de
semestre, vous devrez
documenter toutes les fonctions avec une docstring donnant des exemples pertinents d’utilisation de ces fonctions
ajouter les trois lignes de code suivantes en fin de fichier :
if __name__ == « __main__ »:
import doctest
doctest.testmod()
Que fait cette fonction ? Vous ne l’avez pas écrite ou il y a longtemps…Il manque de la documentation.
Voici la même fonction documentée:
def is_even(nbr):
"""
Cette fonction teste si un nombre est pair.
L’argument nbr peut être un entier ou un nombre à virgule, si nbr est pair la fonction renvoie True, si nbr est impaire la fonction renvoie False.
"""
return nbr % 2 == 0
à faire vous même:
copier cette fonction sous Pyzo, tester la .
Puis dans la console entrer la commande
help (is_even)
vous aurez la documentation de vote fonction .
Il est important de bien commenter son programme et de documenter les fonctions, cela permet de reprendre un code que l’on a écrit il y a longtemps et cela facilite la compréhension de votre code par un autre programmeur ( par exemple en projet à plusieurs codeurs).
Aline envisage d’ouvrir un compte à la banque Argento,
mais elle veut d’abord savoir si cela sera rentable. Sur un tel compte, les
intérêts sont de 5% par an, et la banque prélève un coût fixe annuel de 11 euros.
Le capital de l’année n + 1 est donc obtenu par la formule un+1 =
un × 1.05 − 11, où un désigne le capital à l’année n.
Écrire une fonction capital(nb_annees, capital_debut) qui renvoie le capital en euros qu’Aline aurait sur un tel compte au bout de nb_annees en plaçant initialement un capital égal à capital_debut (en euros).
Écrire une fonction gagne_argent(nb_annees, capital_debut) qui renvoie True si le capital au bout de nb_annees sur un tel compte est supérieur ou égal au capital de début.
Exercice tiré de caséine université de Grenoble – proposé par Aurélie Lagoutte