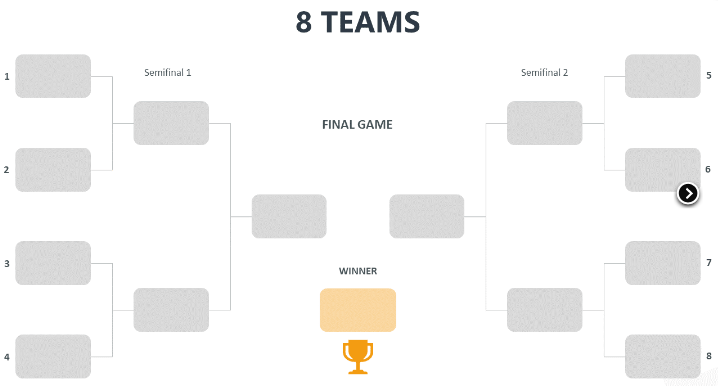
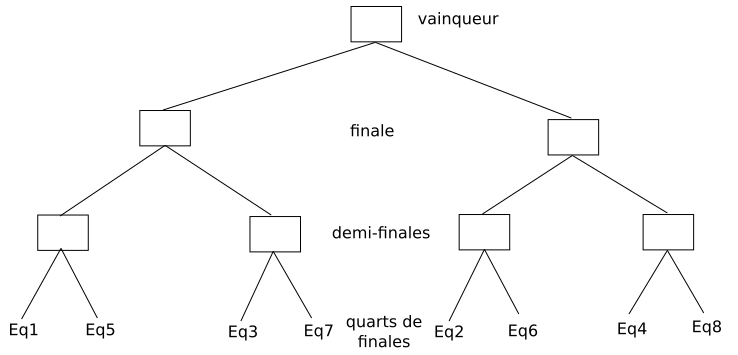
Beaucoup de tournoi sportif sont organisés avec une structure qui représente les matchs joués ou à jouer dans le tournoi. Le principe de base est que chaque branche rassemble deux joueurs (ou deux équipes). Le gagnant avance et le perdant est éliminé. C’est en tout cas le fonctionnement avec élimination Directe.
Ce graphique si on commence par le vainqueur ressemble à un arbre.
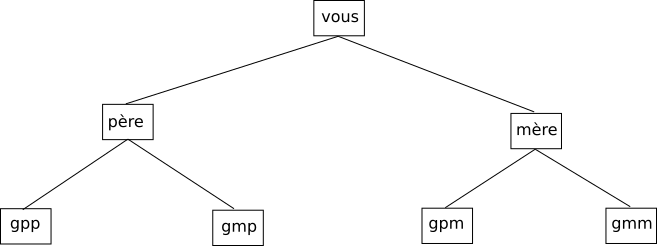
Nous avons ci-dessous ce que l’on appelle une structure en arbre. On peut aussi retrouver cette même structure dans un arbre généalogique :
Dernier exemple, les systèmes de fichiers dans les systèmes de type UNIX ont aussi une structure en arbre.système de fichiers de type UNIX
Les arbres sont des types abstraits très utilisés en informatique. On les utilise notamment quand on a besoin d’une structure hiérarchique des données : dans l’exemple ci-dessous le fichier grub.cfg ne se trouve pas au même niveau que le fichier rapport.odt (le fichier grub.cfg se trouve « plus proche » de la racine / que le fichier rapport.odt). On ne pourrait pas avec une simple liste qui contiendrait les noms des fichiers et des répertoires, rendre compte de cette hiérarchie (plus ou moins « proche » de la racine). On trouve souvent dans cette hiérarchie une notion de temps (les quarts de finale sont avant les demi-finales ou encore votre grand-mère paternelle est née avant votre père), mais ce n’est pas une obligation (voir l’arborescence du système de fichiers).
Les arbres binaires sont des cas particuliers d’arbre : l’arbre du tournoi de rugby et l’arbre « père, mère… » sont des arbres binaires, en revanche, l’arbre représentant la structure du système de fichier n’est pas un arbre binaire. Dans un arbre binaire, on a au maximum 2 branches qui partent d’un élément (pour le système de fichiers, on a 7 branches qui partent de la racine : ce n’est donc pas un arbre binaire). Dans la suite nous allons uniquement travailler sur les arbres binaires.
Soit l’arbre binaire suivant :
Un peu de vocabulaire :
chaque élément de l’arbre est appelé noeud (par exemple : A, B, C, D,…,P et Q sont des noeuds)
le noeud initial (A) est appelé noeud racine ou plus simplement racine
On dira que le noeud E et le noeud D sont les fils du noeud B. On dira que le noeud B est le père des noeuds E et D
Dans un arbre binaire, un noeud possède au plus 2 fils
Un noeud n’ayant aucun fils est appelé feuille (exemples : D, H, N, O, J, K, L, P et Q sont des feuilles)
À partir d’un noeud (qui n’est pas une feuille), on peut définir un sous-arbre gauche et un sous-arbre droite (exemple : à partir de C on va trouver un sous-arbre gauche composé des noeuds F, J et K et un sous-arbre droit composé des noeuds G, L, M, P et Q)
On appelle arête le segment qui relie 2 noeuds.
On appelle profondeur d’un nœud ou d’une feuille dans un arbre binaire le nombre de nœuds du chemin qui va de la racine à ce nœud. La racine d’un arbre est à une profondeur 1, et la profondeur d’un nœud est égale à la profondeur de son prédécesseur plus 1. Si un noeud est à une profondeur p, tous ses successeurs sont à une profondeur p+1. Exemples : profondeur de B = 2 ; profondeur de I = 4 ; profondeur de P = 5 ATTENTION : on trouve aussi dans certains livres la profondeur de la racine égale à 0 (on trouve alors : profondeur de B = 1 ; profondeur de I = 3 ; profondeur de P = 4). Les 2 définitions sont valables, il faut juste préciser si vous considérez que la profondeur de la racine est de 1 ou de 0.
On appelle hauteur d’un arbre la profondeur maximale des nœuds de l’arbre. Exemple : la profondeur de P = 5, c’est un des noeuds les plus profond, donc la hauteur de l’arbre est de 5. ATTENTION : comme on trouve 2 définitions pour la profondeur, on peut trouver 2 résultats différents pour la hauteur : si on considère la profondeur de la racine égale à 1, on aura bien une hauteur de 5, mais si l’on considère que la profondeur de la racine est de 0, on aura alors une hauteur de 4.
Il est aussi important de bien noter que l’on peut aussi voir les arbres comme des structures récursives : les fils d’un noeud sont des arbres (sous-arbre gauche et un sous-arbre droite dans le cas d’un arbre binaire), ces arbres sont eux mêmes constitués d’arbres…
À faire vous-même 1
Trouvez un autre exemple de données qui peuvent être représentées par un arbre binaire (dans le domaine de votre choix). Dessinez au moins une partie de cet arbre binaire. Déterminez la hauteur de l’arbre que vous aurez dessiné.
Python ne propose pas de façon native l’implémentation des arbres binaires. Mais nous aurons, plus tard dans l’année, l’occasion d’implémenter des arbres binaires en Python en utilisant un peu de programmation orientée objet.
Nous aurons aussi très prochainement l’occasion d’étudier des algorithmes permettant de travailler sur les arbres binaires.
De nombreux algorithmes « classiques » manipulent des structures de données plus complexes que des simples nombres (nous aurons l’occasion d’en voir plusieurs cette année). Nous allons ici voir quelques-unes de ces structures de données. Nous allons commencer par des types de structures relativement simples : les listes, les piles et les files. Ces trois types de structures sont qualifiés de linéaires.
Les listes
Une liste est une structure de données permettant de regrouper des données. Une liste L est composée de 2 parties : sa tête (souvent noté car), qui correspond au dernier élément ajouté à la liste, et sa queue (souvent noté cdr) qui correspond au reste de la liste.
Le langage de programmation Lisp (inventé par John McCarthy en 1958) a été un des premiers langages de programmation à introduire cette notion de liste (Lisp signifie « list processing »). Voici les opérations qui peuvent être effectuées sur une liste :
créer une liste vide (L=vide() on a créé une liste L vide)
tester si une liste est vide (estVide(L) renvoie vrai si la liste L est vide)
ajouter un élément en tête de liste (ajouteEnTete (x,L) avec L une liste et x l’élément à ajouter)
supprimer la tête x d’une liste L et renvoyer cette tête x (supprEnTete(L))
Compter le nombre d’éléments présents dans une liste (compte(L) renvoie le nombre d’éléments présents dans la liste L)
La fonction cons permet d’obtenir une nouvelle liste à partir d’une liste et d’un élément (L1 = cons(x,L)). Il est possible « d’enchaîner » les cons et d’obtenir ce genre de structure : cons(x, cons(y, cons(z,L)))
Exemples :
Voici une série d’instructions (les instructions ci-dessous s’enchaînent):
L=vide() => on a créé une liste vide
estVide(L) => renvoie vrai
ajoutEnTete(3,L) => La liste L contient maintenant l’élément 3
estVide(L) => renvoie faux
ajoutEnTete(5,L) => la tête de la liste L correspond à 5, la queue contient l’élément 3
ajoutEnTete(8,L) => la tête de la liste L correspond à 8, la queue contient les éléments 3 et 5
t = supprEnTete(L) => la variable t vaut 8, la tête de L correspond à 5 et la queue contient l’élément 3
L1 = vide()
L2 = cons(8, cons(5, cons(3, L1))) => La tête de L2 correspond à 8 et la queue contient les éléments 3 et 5
À faire vous-même 1
Voici une série d’instructions (les instructions ci-dessous s’enchaînent), expliquez ce qui se passe à chacune des étapes :
On retrouve dans les piles une partie des propriétés vues sur les listes. Dans les piles, il est uniquement possible de manipuler le dernier élément introduit dans la pile. On prend souvent l’analogie avec une pile d’assiettes : dans une pile d’assiettes la seule assiette directement accessible et la dernière assiette qui a été déposée sur la pile.
Les piles sont basées sur le principe LIFO (Last In First Out : le dernier rentré sera le premier à sortir). On retrouve souvent ce principe LIFO en informatique.
Voici les opérations que l’on peut réaliser sur une pile :
on peut créer une pile
on peut savoir si une pile est vide (pile_vide?)
on peut empiler un nouvel élément sur la pile (push)
on peut récupérer l’élément au sommet de la pile tout en le supprimant. On dit que l’on dépile (pop)
on peut accéder à l’élément situé au sommet de la pile sans le supprimer de la pile (sommet)
on peut connaitre le nombre d’éléments présents dans la pile (taille)
Exemples :
Soit une pile P composée des éléments suivants : 12, 14, 8, 7, 19 et 22 (le sommet de la pile est 22) Pour chaque exemple ci-dessous on repart de la pile d’origine :
pop(P) renvoie 22 et la pile P est maintenant composée des éléments suivants : 12, 14, 8, 7 et 19 (le sommet de la pile est 19)
push(P,42) la pile P est maintenant composée des éléments suivants : 12, 14, 8, 7, 19, 22 et 42
sommet(P) renvoie 22, la pile P n’est pas modifiée
si on applique pop(P) 6 fois de suite, pile_vide?(P) renvoie vrai
Après avoir appliqué pop(P) une fois, taille(P) renvoie 5
À faire vous-même 2
Soit une pile P composée des éléments suivants : 15, 11, 32, 45 et 67 (le sommet de la pile est 67). Quel est l’effet de l’instruction pop(P)
Les files
Comme les piles, les files ont des points communs avec les listes. Différences majeures : dans une file on ajoute des éléments à une extrémité de la file et on supprime des éléments à l’autre extrémité. On prend souvent l’analogie de la file d’attente devant un magasin pour décrire une file de données.
Les files sont basées sur le principe FIFO (First In First Out : le premier qui est rentré sera le premier à sortir. Ici aussi, on retrouve souvent ce principe FIFO en informatique.
Voici les opérations que l’on peut réaliser sur une file :
on peut savoir si une file est vide (file_vide?)
on peut ajouter un nouvel élément à la file (ajout)
on peut récupérer l’élément situé en bout de file tout en le supprimant (retire)
on peut accéder à l’élément situé en bout de file sans le supprimer de la file (premier)
on peut connaitre le nombre d’éléments présents dans la file (taille)
Exemples :
Soit une file F composée des éléments suivants : 12, 14, 8, 7, 19 et 22 (le premier élément rentré dans la file est 22 ; le dernier élément rentré dans la file est 12). Pour chaque exemple ci-dessous on repart de la file d’origine :
ajout(F,42) la file F est maintenant composée des éléments suivants : 42, 12, 14, 8, 7, 19 et 22 (le premier élément rentré dans la file est 22 ; le dernier élément rentré dans la file est 42)
retire(F) la file F est maintenant composée des éléments suivants : 12, 14, 8, 7, et 19 (le premier élément rentré dans la file est 19 ; le dernier élément rentré dans la file est 12)
premier(F) renvoie 22, la file F n’est pas modifiée
si on applique retire(F) 6 fois de suite, file_vide?(F) renvoie vrai
Après avoir appliqué retire(F) une fois, taille(F) renvoie 5.
À faire vous-même 3
Soit une file F composée des éléments suivants : 1, 12, 24, 17, 21 et 72 (le premier élément rentré dans la file est 72 ; le dernier élément rentré dans la file est 1). Quel est l’effet de l’instruction ajout(F,25)
Types abstraits et représentation concrète des données
Nous avons évoqué ci-dessus la manipulation des types de données (liste, pile et file) par des algorithmes, mais, au-delà de la beauté intellectuelle de réfléchir sur ces algorithmes, le but de l’opération est souvent, à un moment ou un autre, de « traduire » ces algorithmes dans un langage compréhensible pour un ordinateur (Python, Java, C,…). On dit alors que l’on implémente un algorithme. Il est donc aussi nécessaire d’implémenter les types de données comme les listes, les piles ou les files afin qu’ils soient utilisables par les ordinateurs. Les listes, les piles ou les files sont des « vues de l’esprit » présent uniquement dans la tête des informaticiens, on dit que ce sont des types abstraits de données (ou plus simplement des types abstraits). L’implémentation de ces types abstrait, afin qu’ils soient utilisables par une machine, est loin d’être une chose triviale. L’implémentation d’un type de données dépend du langage de programmation. Il faut, quel que soit le langage utilisé, que le programmeur retrouve les fonctions qui ont été définies pour le type abstrait (pour les listes, les piles et les files cela correspond aux fonctions définies ci-dessus). Certains types abstraits ne sont pas forcément implémentés dans un langage donné, si le programmeur veut utiliser ce type abstrait, il faudra qu’il le programme par lui-même en utilisant les « outils » fournis par son langage de programmation.
Pour implémenter les listes (ou les piles et les files), beaucoup de langages de programmation utilisent 2 structures : les tableaux et les listes chaînées.
Un tableau est une suite contiguë de cases mémoires (les adresses des cases mémoire se suivent) :
Le système réserve une plage d’adresse mémoire afin de stocker des éléments.
La taille d’un tableau est fixe : une fois que l’on a défini le nombre d’éléments que le tableau peut accueillir, il n’est pas possible modifier sa taille. Si l’on veut insérer une donnée, on doit créer un nouveau tableau plus grand et déplacer les éléments du premier tableau vers le second tout en ajoutant la donnée au bon endroit !
Dans certains langages de programmation, on trouve une version « évoluée » des tableaux : les tableaux dynamiques. Les tableaux dynamiques ont une taille qui peut varier. Il est donc relativement simple d’insérer des éléments dans le tableau. Ce type de tableaux permet d’implémenter facilement le type abstrait liste (de même pour les piles et les files)
À noter que les « listes Python » (listes Python) sont des tableaux dynamiques. Attention de ne pas confondre avec le type abstrait liste défini ci-dessus, ce sont de « faux amis ».tableau dynamique
Autre type de structure que l’on rencontre souvent et qui permet d’implémenter les listes, les piles et les files : les listes chaînées.
Dans une liste chaînée, à chaque élément de la liste on associe 2 cases mémoire : la première case contient l’élément et la deuxième contient l’adresse mémoire de l’élément suivant.
Il est relativement facile d’insérer un élément dans une liste chaînée :
Il est aussi possible d’implémenter les types abstraits en utilisant des structures plus complexes que les tableaux et les listes chaînées. Par exemple, en Python, il est possible d’utiliser les tuples pour implémenter le type abstrait liste :
En utilisant les connaissances acquises jusqu’à présent, vous allez écrire un programme de gestion de répertoire téléphonique.
Cahier des charges
Ce programme devra proposer le menu suivant à l’utilisateur :
0-quitter 1-écrire dans le répertoire 2-rechercher dans le répertoire
3-mettre les numéros au format internationale Votre choix ?
Si le choix est 0 : Le programme sera stoppé.
Si le choix est 1 :
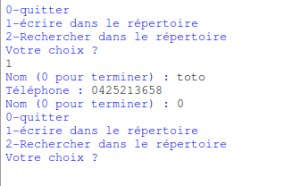
L’utilisateur devra saisir un nom ou un prénom ou 0 s’il veut terminer la saisie ( » Nom (0 pour terminer) : « ….) :
L’utilisateur entre 0 => le programme devra le renvoyer vers le menu
L’utilisateur entre un nom ou prénom => le programme devra lui demander de saisir le numéro de téléphone correspondant au nom. Une fois le numéro saisi, le programme devra lui proposer d’entrer un nouveau nom (ou 0 pour terminer)…
exemple de saisie d’un utilisateur (toto)
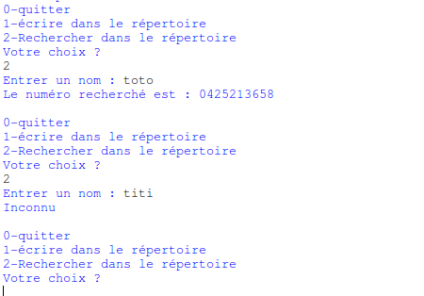
Si le choix est 2 :
L’utilisateur devra saisir le nom recherché ( » Entrer un nom : « ), ou le numéro de téléphone ( » Entrer un numéro : « ).
Si le nom recherché est présent dans le répertoire, le programme devra afficher » Le numéro recherché est : » suivi du numéro de téléphone correspondant au nom saisi.
Si le nom recherché est absent du répertoire, le programme devra afficher » Inconnu « .
…….
L’utilisateur est ensuite redirigé vers le menu principal.
recherche des utilisateurs (toto et titi)
Les noms, prénoms et numéros de téléphone devront être stockés dans un dictionnaire, le nom ou le prénom seront la clé et le numéro de téléphone sera la valeur associée à la clé.
Votre programme devra être composé au minimum de 3 fonctions : une fonction « menu », une fonction « lecture », et une fonction « ecriture »…….
Pensez à commenter votre programme, bien expliquer ce que doit faire vos fonctions et les différents tests que vous prévoyez.
Nous allons maintenant étudier un autre type abstrait de données : les dictionnaires aussi appelés tableau associatif.
On retrouve une structure qui ressemble, à première vue, beaucoup à un tableau (à chaque élément on associe un indice de position). Mais au lieu d’associer chaque élément à un indice de position, dans un dictionnaire, on associe chaque élément (on parle de valeur dans un dictionnaire) à une clef, on dit qu’un dictionnaire contient des couples clef:valeur (chaque clé est associée à une valeur). Exemples de couples clé:valeur => prenom:Kevin, nom:Durand, date-naissance:17-05-2005. prenom, nom et date sont des clés ; Kevin, Durand et 17-05-2005 sont des valeurs.
Voici les opérations que l’on peut effectuer sur le type abstrait dictionnaire :
ajout : on associe une nouvelle valeur à une nouvelle clé
modif : on modifie un couple clé:valeur en remplaçant la valeur courante par une autre valeur (la clé restant identique)
suppr : on supprime une clé (et donc la valeur qui lui est associée)
rech : on recherche une valeur à l’aide de la clé associée à cette valeur.
Exemples : Soit le dictionnaire D composé des couples clé:valeur suivants => prenom:Kevin, nom:Durand, date-naissance:17-05-2005. Pour chaque exemple ci-dessous on repart du dictionnaire d’origine :
ajout(D,tel:06060606) ; le dictionnaire D est maintenant composé des couples suivants : prenom:Kevin, nom:Durand, date-naissance:17-05-2005, tel:06060606
modif(D,nom:Dupont) ; le dictionnaire D est maintenant composé des couples suivants : prenom:Kevin, nom:Dupont, date-naissance:17-05-2005
suppr(D,date-naissance) ; le dictionnaire D est maintenant composé des couples suivants : prenom:Kevin, nom:Durand
rech(D,prenom) ; la fonction retourne Kevin
L’implémentation des dictionnaires dans les langages de programmation peut se faire à l’aide des tables de hachage. Les tables de hachages ainsi que les fonctions de hachages qui sont utilisées pour construire les tables de hachages, ne sont pas au programme de NSI. Cependant, l’utilisation des fonctions de hachages est omniprésente en informatique, il serait donc bon, pour votre « culture générale informatique », de connaitre le principe des fonctions de hachages. Voici un texte qui vous permettra de comprendre le principe des fonctions de hachages : c’est quoi le hachage . Pour avoir quelques idées sur le principe des tables de hachages, je vous recommande le visionnage de cette vidéo : wandida : les tables de hachage
Si vous avez visionné la vidéo de wandida, vous avez déjà compris que l’algorithme de recherche dans une table de hachage a une complexité O(1) (le temps de recherche ne dépend pas du nombre d’éléments présents dans la table de hachage), alors que la complexité de l’algorithme de recherche dans un tableau non trié est O(n). Comme l’implémentation des dictionnaires s’appuie sur les tables de hachage, on peut dire que l’algorithme de recherche d’un élément dans un dictionnaire a une complexité O(1) alors que l’algorithme de recherche d’un élément dans un tableau non trié a une complexité O(n).
Python propose une implémentation des dictionnaires, nous avons déjà étudié cette implémentation l’année dernière, n’hésitez pas à vous référer à la ressource proposée l’an passé : les dictionnaires en Python
À la « préhistoire » des systèmes d’exploitation, ces derniers étaient dépourvus d’interface graphique (système de fenêtres
« pilotables » à la souris),
toutes les interactions « système d’exploitation – utilisateur » se faisaient par l’intermédiaire de « lignes de commandes »
(suites de caractères, souvent ésotériques, saisies par l’utilisateur). Aujourd’hui,
même si les interfaces graphiques modernes permettent d’effectuer la plupart des opérations,
il est important de connaitre quelques-unes de ces lignes de commandes.
Nous allons utiliser une clé Freeduc-JBART, cette clé est basée sur Debian-Live , ce qui nous permettra de travailler sous Linux .
Pour saisir des lignes de commandes, nous allons utiliser une console (aussi appelé terminal même si ce n’est pas exactement la même chose).
À faire vous-même 1
Après avoir démarrer sur votre clé Freeduc-JBART
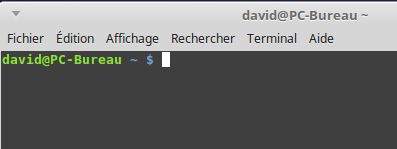
Ouvrez une console, vous devriez avoir quelque chose qui ressemble à cela :
console système GNU/Linux
Nous avons ci-dessus la console de l’utilisateur « david » qui utilise
un ordinateur qui se nomme « PC-Bureau » (« david@PC-Bureau »).
Principalement nous allons, grâce à la ligne de commande, travailler
sur les fichiers et les répertoires. Dans les systèmes de type « UNIX »
(par exemple GNU/Linux ou macOS),
nous avons un système de fichier en arborescence :
système de fichiers
Dans le schéma ci-dessus on trouve des répertoires (noms entourés
d’un rectangle, exemple : « home ») et des fichiers (uniquement des noms
« grub.cfg »).
À noter : les extensions des noms de fichiers, par exemple le « cfg »
de « grub.cfg », ne sont pas obligatoires dans les systèmes de type
« UNIX », par exemple, « bash » est bien un nom de fichier et il n’a pas
d’extension.
On parle d’arborescence, car ce système de fichier ressemble à un arbre à l’envers.
Comme vous pouvez le constater, la base de l’arbre s’appelle la racine de l’arborescence et se représente par un « / »
Chemin absolu ou chemin relatif ?
Pour indiquer la position d’un fichier (ou d’un répertoire) dans l’arborescence, il existe 2 méthodes :
indiquer un chemin absolu ou indiquer un chemin relatif. Le chemin absolu doit indiquer « le chemin » depuis la racine.
Par exemple le chemin absolu du fichier fiche.ods sera : /home/elsa/documents/fiche.ods
Remarquez que nous démarrons bien de la racine / (attention les symboles de séparation sont aussi des /)
Il est possible d’indiquer le chemin non pas depuis la racine,
mais depuis un répertoire quelconque, nous parlerons alors de chemin
relatif :
Le chemin relatif permettant d’accéder au fichier « photo_1.jpg »
depuis le répertoire « max » est : « images/photo_vac/photo_1.jpg »
Remarquez l’absence du / au début du chemin (c’est cela qui nous permettra de distinguer un chemin relatif et un chemin absolu).
Imaginons maintenant que nous désirions indiquer le chemin relatif
pour accéder au fichier « gdbd_3.jpg » depuis le répertoire « photos_vac ».
Comment faire ?
Il faut « remonter » d’un « niveau » dans l’arborescence pour se retrouver dans le répertoire « images » et ainsi
pouvoir repartir vers la bonne « branche ». Pour ce faire il faut utiliser 2 points : ..
« ../ski/gdbd_3.jpg »
Il est tout à fait possible de remonter de plusieurs « crans » :
« ../../ » depuis le répertoire « photos_vac » permet de « remonter » dans le
répertoire « max »
À faire vous-même 2
En vous basant sur l’arborescence ci-dessus, déterminez le chemin absolu permettant d’accéder au fichier :
« cat »
« rapport.odt »
Toujours en vous basant sur l’arborescence ci-dessus, déterminez le chemin relatif permettant d’accéder au fichier :
« rapport.odt » depuis le répertoire « elsa »
« fiche.ods » depuis le répertoire « boulot »
Comme déjà évoqué plus haut, les systèmes de type « UNIX » sont des
systèmes « multi-utilisateurs » : chaque utilisateur possède son propre
compte.
Chaque utilisateur possède un répertoire à son nom, ces répertoires
personnels se situent traditionnellement dans le répertoire « home ». Dans
l’arborescence ci-dessus, nous avons 2 utilisateurs : « max » et « elsa ».
Par défaut, quand un utilisateur ouvre une console, il se trouve
dans son répertoire personnel. Dans l’image de la console ci-dessus,
nous avons un « david@PC-Bureau ~ $ » (au passage, on appelle cela
« l’invite de commande »), le « ~ » (caractère « tilde ») signifie
que l’on se trouve actuellement dans le répertoire personnel de
l’utilisateur courant, autrement dit dans le répertoire de chemin absolu
« /home/david » (puisque l’utilisateur courant est « david »). Le
répertoire « où l’on se trouve actuellement » est appelé « répertoire
courant ».
L’invite de commande vous indique à tout moment le répertoire
courant : « david@PC-Bureau ~/Documents $ » vous indique que vous êtes
dans le répertoire « Documents » qui se trouve dans le répertoire « david »
qui se trouve dans le répertoire « home » (chemin absolu :
« /home/david/Documents »)
Attention : les systèmes de type « UNIX » sont « sensibles à la casse »
(il faut différencier les caractères majuscules et les caractères
minuscules) : le répertoire « Documents » et le répertoire « documents »
sont 2 répertoires différents.
La commande cd
Signification : list
La commande « cd » permet de changer le répertoire courant. Il suffit d’indiquer le chemin (relatif ou absolu) qui permet d’atteindre le nouveau répertoire :
Par exemple (en utilisant l’arborescence ci-dessus) :
si le répertoire courant est le répertoire « elsa » et que vous
« voulez vous rendre » dans le répertoire « documents », il faudra saisir la
commande : « cd documents » (relatif) ou « cd /home/elsa/documents »
(absolu)
si le répertoire courant est le répertoire « photos_vac » et que vous
« voulez vous rendre » dans le répertoire « ski », il faudra saisir la
commande : « cd ../ski » (relatif) ou « cd /home/max/images/ski » (absolu)
si le répertoire courant est le répertoire « boulot » et que vous
« voulez vous rendre » dans le répertoire « documents », il faudra saisir la
commande : « cd .. » (relatif) ou « cd /home/elsa/documents » (absolu)
À faire vous-même 3
Toujours en utilisant l’arborescence ci-dessus, quelle est la
commande à saisir si le répertoire courant est le répertoire « home » et
que vous « voulez vous rendre » dans le répertoire « boulot » (vous
utiliserez d’abord un chemin absolu puis un chemin relatif)
La commande ls
Signification : list
La commande « ls » permet de lister le contenu du répertoire courant.
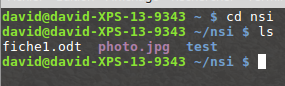
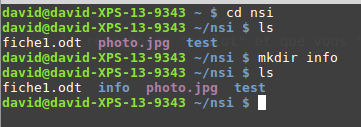
Dans l’exemple ci-dessus, depuis le répertoire personnel de
l’utilisateur « david », nous passons dans le répertoire « nsi » à l’aide
d’un « cd nsi », puis nous affichons le contenu de ce répertoire « nsi » à
l’aide de la commande « ls ». Nous trouvons dans le répertoire « nsi » :
2 fichiers (« fiche1.odt » et « photo.jpg ») et un répertoire (« test »).
À faire vous-même 4
Après avoir ouvert une console, utilisez la commande ls depuis votre répertoire personnel.
La commande « mkdir »
Signification : make directory
La commande « mkdir » permet de créer un répertoire dans le répertoire courant. La commande est de la forme « mkdir nom_du_répertoire »
Remarque : il est préférable de ne pas utiliser de caractères
accentués dans les noms de répertoire (ou de fichier). Il en est de même
pour les espaces
(à remplacer par des caractères tirets bas « _ »)
La commande man
Signification : manual
Affiche les pages du manuel système. Chaque argument donné à man est généralement le nom d’un programme, d’un utilitaire, d’une fonction ou d’un fichier spécial. Exemples d’utilisation :
man man affiche les informations pour l’utilisation de man
man mkdir affiche les informations pour l’utilisation de mkdir
‘q’ pour quitter.
À faire vous-même 5
Après avoir ouvert une console, utilisez la commande « mkdir » afin de
créer un répertoire « test_nsi » dans votre répertoire personnel.
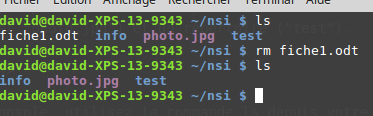
La commande « rm »
Signification : remove
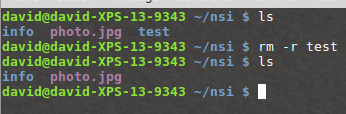
La commande « rm » permet de supprimer un fichier ou un répertoire. La commande est de la forme « rm nom_du_répertoire_ou_nom_du_fichier »
La plupart des commandes UNIX peuvent être utilisées avec une ou des options. Par exemple, pour supprimer un répertoire non vide, il est nécessaire d’utiliser la commande « rm » avec l’option « -r » : « rm -r nom_du_répertoire »
Attention si vous utilisez la commande « rm * » cela supprime tous les fichiers présent dans le répertoire courant.
A noter que pour afficher le répertoire courant il existe une fonction « pwd », même s’il est spécifié sur le terminal en bleu…
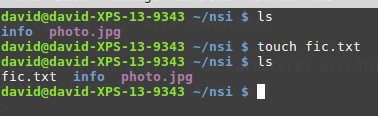
La commande « touch »
La commande « touch » permet de créer un fichier vide. La commande est de la forme « touch nom_du_fichier_à_créer »
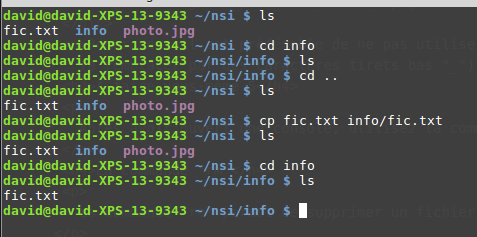
La commande « cp »
Signification : copy
La commande « cp » permet de copier un fichier. La commande est de la forme « cp /répertoire_source/nom_fichier_à_copier /répertoire_destination/nom_fichier »
À noter : le nom du fichier « destination » n’est pas obligatoirement
le même que le nom du fichier « source » (on peut avoir « cp fic.txt
info/fiche.txt »)
La commande « mv »
Signification : move
la commande « mv » permet de déplacer ou renommer des fichiers et des répertoires Options les plus fréquentes :
-f : Écrase les fichiers de destination sans confirmation
-i : Demande confirmation avant d’écraser
-u : N’écrase pas le fichier de destination si celui-ci est plus récent
Exemples d’utilisation :
mv monFichier unRep/ Déplace monFichier dans le répertoire unRep
mv unRep/monFichier . Déplace le fichier monFichier du répertoire unRep là où on se trouve
mv unRep monRep Renomme unRep en monRep
À faire vous-même 6
Placez-vous dans le répertoire « test_nsi » créé au « À faire vous-même 5 ». Créez un fichier « test.txt » avec du texte à l’intérieur.
Saisir la commande « cat test.txt » que se passe t’il?
Créez un répertoire « doc ». Copiez le fichier « test.txt » dans le répertoire « doc ». Effacez le répertoire doc (et son contenu).
Gestion des utilisateurs et des groupes
Les systèmes de type « UNIX » sont des systèmes multi-utilisateurs,
plusieurs utilisateurs peuvent donc partager un même ordinateur, chaque
utilisateur possédant un environnement
de travail qui lui est propre.
Chaque utilisateur possède certains droits lui permettant
d’effectuer certaines opérations et pas d’autres. Le système
d’exploitation permet de gérer ces droits très finement.
Un utilisateur un peu particulier est autorisé à modifier tous les
droits : ce « super utilisateur » est appelé « administrateur » ou « root ».
L’administrateur pourra donc attribuer ou retirer
des droits aux autres utilisateurs.
Au lieu de gérer les utilisateurs un par un, il est possible de créer
des groupes d’utilisateurs. L’administrateur attribue des droits à un
groupe au lieu d’attribuer des droits
particuliers à chaque utilisateur.
Comme nous venons de le voir, chaque utilisateur possède des droits
qui lui ont été octroyés par le « super utilisateur ». Nous nous
intéresserons ici uniquement aux droits liés aux
fichiers, mais vous devez savoir qu’il existe d’autres droits liés
aux autres éléments du système d’exploitation ((imprimante, installation
de logiciels…).
Les fichiers et les répertoires possèdent 3 types de droits :
les droits en lecture (symbolisés par la lettre r) : est-il possible de lire le contenu de ce fichier
les droits en écriture (symbolisés par la lettre w) : est-il possible de modifier le contenu de ce fichier
les droits en exécution (symbolisés par la lettre x) : est-il
possible d’exécuter le contenu de ce fichier (quand le fichier du code
exécutable)
Il existe 3 types d’utilisateurs pour un fichier ou un répertoire :
le propriétaire du fichier (par défaut c’est la personne qui a créé le fichier), il est symbolisé par la lettre u
un fichier est associé à un groupe, tous les utilisateurs
appartenant à ce groupe possèdent des droits particuliers sur ce
fichier. Le groupe est symbolisé par la lettre g
tous les autres utilisateurs (ceux qui ne sont pas le propriétaire
du fichier et qui n’appartiennent pas au groupe associé au fichier).
Ces utilisateurs sont symbolisés
la lettre « o »
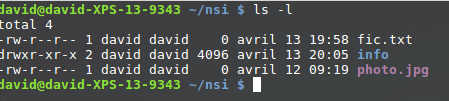
Il est possible d’utiliser la commande « ls » avec l’option « -l » afin d’avoir des informations supplémentaires.
Prenons la première ligne :
-rw-r--r-- 1 david david 0 avril 13 19:58 fic.txt
Lisons cette ligne de gauche à droite :
le premier symbole « – » signifie que l’on a affaire à un fichier,
dans le cas d’un répertoire, nous aurions un « d » (voir la 2e ligne)
les 3 symboles suivants « rw-« donnent les droits du propriétaire du
fichier : lecture autorisée (r), écriture autorisée (w), exécution
interdite (- à la place de x)
les 3 symboles suivants « r–« donnent les droits du groupe lié au
fichier : lecture autorisée (r), écriture interdite (- à la place de w),
exécution
interdite (- à la place de x)
les 3 symboles suivants « r–« donnent les droits des autres
utilisateurs : lecture autorisée (r), écriture interdite (- à la place
de w), exécution
interdite (- à la place de x)
le caractère suivant « 1 » donne le nombre de liens (nous n’étudierons pas cette notion ici)
le premier « david » représente le nom du propriétaire du fichier
le second « david » représente le nom du groupe lié au fichier
le « 0 » représente la taille du fichier en octet (ici notre fichier est vide)
« avril 13 19:58 » donne la date et l’heure de la dernière modification du fichier
« fic.txt » est le nom du fichier
Prenons la deuxième ligne :
drwxr-xr-x 2 david david 4096 avril 13 20:05 info
Lisons cette ligne de gauche à droite :
le premier symbole « d » signifie que l’on a un répertoire
les 3 symboles suivants « rwx »donnent les droits du propriétaire
du répertoire : lecture du contenu du répertoire autorisée (r),
modification du contenu du répertoire autorisée (w),
il est possible de parcourir le répertoire (voir le contenu du
répertoire) (x)
les 3 symboles suivants « r-x »donnent les droits du groupe lié au
répertoire : modification du contenu du répertoire interdite (- à la
place de w)
les 3 symboles suivants « r-x »donnent les droits des autres
utilisateurs : modification du contenu du répertoire interdite (- à la
place de w)
le caractère suivant « 2 » donne le nombre de liens (nous n’étudierons pas cette notion ici)
le premier « david » représente le nom du propriétaire du répertoire
le second « david » représente le nom du groupe lié au répertoire
le « 4096 » représente la taille du répertoire en octets
« avril 13 20:05 » donne la date et l’heure de la dernière modification du contenu du répertoire
« info » est le nom du répertoire
À faire vous-même 7
Analysez la 3e ligne du résultat de la commande « ls -l » ci-dessus
Il est important de ne pas perdre de vu que l’utilisateur « root » a
la possibilité de modifier les droits de tous les utilisateurs.
Le propriétaire d’un fichier peut modifier les permissions d’un
fichier ou d’un répertoire à l’aide de la commande « chmod ». Pour
utiliser cette commande, il est nécessaire de connaitre certains
symboles :
les symboles liés aux utilisateurs : « u » correspond au
propriétaire, « g » correspond au groupe lié au fichier (ou au
répertoire), « o » correspond aux autres utilisateurs et « a » correspond à
« tout le monde » (permet de modifier « u », « g » et « o » en même temps)
les symboles liés à l’ajout ou la suppression des permissions : « + »
on ajoute une permission, « – » on supprime une permission, « = » les
permissions sont réinitialisées (permissions par défaut)
les symboles liés aux permissions : « r » : lecture, « w » : écriture, « x » : exécution.
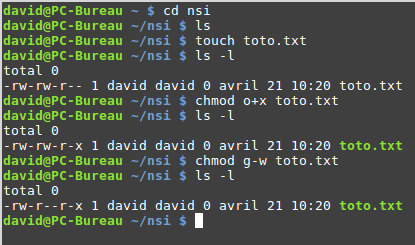
La commande « chmod » à cette forme :
chmod [u g o a] [+ - =] [r w x] nom_du_fichier
par exemple
chmod o+w toto.txt
attribuera la permission « écriture » pour le fichier « toto.txt » « aux autres utilisateurs »
Il est possible de combiner les symboles :
chmod g-wx toto.txt
La commande « chmod » ci-dessus permet de supprimer la permission
« écriture » et la permission « exécution » pour le fichier « toto.txt » « au
groupe lié au fichier »
Une fois de plus, « root » a tous les droits sur l’ensemble des fichiers
et des répertoires, il peut donc utiliser la commande « chmod » sur tous
les répertoires et tous les fichiers.
À faire vous-même 8
Analysez attentivement l’enchainement de commandes suivantes :
À faire vous-même 9
Créez un répertoire « test_nsi2 » dans votre répertoire personnel.
Placez-vous dans le répertoire « test_nsi2 ». Créez un fichier « titi.txt »,
vérifiez les permissions associées à ce fichier. Modifiez les
permissions associées au fichier « titi.txt » afin que les « autres
utilisateurs » aient la permission « écriture »
On se propose dans cette activité de traiter des données issues d’un fichier csv récupéré sur le site Strava afin de les filtrer dans un nouveau fichier. Le fichier de données de départ se nomme « liste_origine.csv ».
Il faudra écrire 5 fonctions : • « import_lignes » avec en argument le fichier de données de départ et qui renvoie une liste des lignes contenues dans le fichier. • « Separe_lignes » avec en argument la liste précédente et qui renvoie la liste avec les lignes séparées. • « creation_liste » qui créera la liste voulue en enlevant les champs inutiles. • « classement_annee » permettra de ne garder que les lignes de l’année courante. • « nouveau_fichier » qui écrira les lignes de l’année dans un nouveau fichier créé pour l’occasion.
Activité 1 : Présentation et découverte du format csv
Strava est un site qui est utilisé pour enregistrer des activités sportives. Les membres du site peuvent partager leurs activités préalablement enregistrées via GPS. En cyclisme et en course à pied, il existe des segments de route chronométrés où les athlètes peuvent se concurrencer. Nous travaillerons sur un fichier contenant les performances d’une montée du Mont-Ventoux, réalisée en cyclisme. Les données sont alors disponibles et téléchargeables dans un fichier au format csv. Un fichier csv est un fichier texte, représentant des données tabulaires sous forme de valeurs séparées par des virgules, tabulations ou points-virgules. Les lignes sont séparées par un retour à la ligne matérialisé par un « \n ».
Dans notre cas, ouvrir le fichier « liste_origine.csv » avec un éditeur de texte, et indiquer quel est le séparateur utilisé : Séparateur : ? Quels champs (étiquettes des colonnes) contient-il ? ? Nous souhaitons traiter ce fichier, en ne gardant uniquement que les performances de l’année en cours et en séparant le nom du prénom car dans le champ « nom » il y a les 2, mais également en supprimant les champs qui ne nous intéressent pas (« Vitesse », « HR », « Puissance », « Vit. Ascens. » et « Temps ») Pour cela, il faudra dans un premier temps récupérer les lignes contenues dans le fichier de départ et les placer dans une liste exploitable.
Activité 2 : Récupération des lignes du fichier de départ
Écrire une fonction « import_lignes » qui prend en argument un nom de fichier (on testera avec le nôtre « liste_origine.csv ») et qui renvoie la liste des lignes du fichier, c’est-à-dire une liste de chaînes de caractères, où chaque élément de la liste correspond à une ligne du fichier. Il faudra bien penser à fermer le fichier avant de faire le return ! Tester votre fonction en affichant le résultat de la liste créée.
Écrire une fonction « separe_lignes » qui prend en argument une chaine de caractère et qui renvoie une liste contenant les chaînes de caractères correspondants aux champs de notre fichier.
(par exemple: separe_lignes(’28;David POLVERONI;21/09/2012;17,7km/h;166bpm;300W;1368,0;01:05:56;3956\n’) renvoie une liste =[’28’, ‘David POLVERONI’, ’21/09/2012′, ‘17,7km/h’, ‘166bpm’, ‘300W’, ‘1368,0’, ’01:05:56′, ‘3956’] Elle sera obtenue en séparant la ligne le long des points-virgules. Pour cela, aidez-vous de la propriété « chaine_caractere.strip » qui permet d’enlever un éventuel \n (retour à la ligne) et/ou des espaces à la fin de la chaine de caractère, ainsi que de la propriété » chaine_caractere .split(« ; ») » qui sépare la ligne à chaque fois qu’un point-virgule est rencontré…
aide sur les méthodes s’appliquant au string w3schools
Activité 4 : Création d’un dictionnaire dico_coureur
Écrire une fonction « creation_dico » qui prend en argument une ligne (chaîne de caractères) et qui renvoie un dictionnaire correspondant au cycliste de la ligne, en omettant les champs non retenus (« Vitesse », « HR », « Puissance », « Vit. Ascens. » et « Temps »)… Exemple de résultat : creation_dico(‘2;Romain Bardet;17/06/2019;19,9km/h;-;-;1\xa0539,7;00:58:35;3515\n’) doit renvoyer : {‘classement’: ‘2’, ‘nomcomplet’: ‘Romain Bardet’, ‘date’: ’17/06/2019′, ‘temps_s’: ‘3515’} , si vous voulez séparer la clé nomcomplet en deux clé prenom et nom.
Activité 5 : Création d’une liste de dictionnaire
Écrire une fonction « liste_perf » qui prend en argument un nom de fichier et qui renvoie une liste de dictionnaire des performances correspondant aux lignes du fichier ( en omettant la première ligne).
Exemple de résultat: liste_perf (‘liste_origine.csv’) doit renvoyer : une liste de dictionnaire:
Écrire une fonction « classement_annee » qui prend en argument la liste de dictionnaire précédemment créée et qui renvoie une nouvelle liste contenant uniquement les performances de l’année 2019. Pour cela, vous devrez vous aider de la liste créer lors de l’activité précédente , pour rechercher l’année dans la date vous devrez utiliser la propriété .split(‘/’), vue précédemment ! Exemple de résultat : classement_annee([{‘classement’: ‘1’, ‘prenom’: ‘Laurens’, ‘nom’: ‘ten’, ‘date’: ’14/07/2013′, ‘temps_s’: 3497}, {‘classement’: ‘2’, ‘prenom’: ‘Romain’, ‘nom’: ‘Bardet’, ‘date’: ’17/06/2019′, ‘temps_s’: 3515}])
Si vous voulez vous pouvez ajouter l’année de tri en argument, et trié ainsi en fonction de l’année donnée en argument.
Pour aller plus loin : Écriture dans un nouveau fichier
On souhaite enfin réécrire tous ces résultats dans un nouveau fichier « classement_2019.csv ». Pour cela, écrire une fonction « nouveau_fichier » qui prend en argument la liste précédente et qui va l’écrire ligne à ligne dans le fichier « classement_2019.csv » en insérant des points-virgules entre les champs. La première ligne du fichier devra être : » ‘classement;prenom;nom;date;temps_s;’+’\n’ «
vous avez bien sûr le droit de définir des fonctions intermédiaires qui ne sont pas demandées, lorsque vous jugez cela pertinent. Lisez l’énoncé en entier avant de commencer pour repérer les éventuelles opérations qui se répètent souvent.
dans cet exercice, vous avez souvent besoin de convertir un mot en liste de lettres. Pour cela, il faut utiliser list(…) comme dans l’exemple suivant: list(‘oui’) vaut [‘o’, ‘u’, ‘i’].
on suppose que tous les mots considérés dans cet exercice ne contiennent que des lettres, sans accents et en minuscule (pas de caractères spéciaux, tirets, espaces, etc…)
1) Ecrire une fonction commence_par prenant en
argument une lettre et un mot et qui renvoie True
si le mot commence par la lettre donnée en argument, False
sinon.
Test:
commence_par('h', 'hello') vaut True
mais commence_par('e', 'roue') vaut False.
2) Ecrire une fonction contient_voyelle qui prend
en argument un mot et qui renvoie True
si le mot contient une voyelle, False
sinon.
3) Ecrire une fonction derniere_consonne qui
prend en argument un mot et qui renvoie deux valeurs de retour:
l’indice de sa dernière consonne ainsi que la dernière consonne
(comme pour les listes, on considérera que l’indice de la première
lettre est zéro). On ne traitera pas le cas problématique où le
mot ne contient pas de consonne.
Test::
derniere_consonne('arrivee') renvoie 4, ‘v’
4) Ecrire une fonction double_consonne qui prend
en argument un mot et qui a deux valeurs de retour: un booléen
valant True si le
mot contient une double consonne (deux fois la même consonne à la
suite), et dans ce cas la deuxième valeur de retour est la consonne
qui est doublée ; s’il n’y a pas de consonne doublée, la
fonction doit renvoyer False
et None. Pour
information: pour simplifier l’exercice, on ne testera pas votre
fonction sur un mot contenant plusieurs double consonnes (par
exemple, ‘successeur’).
Test:
double_consonne('arrivee') vaut True, ‘r’.
double_consonne('bonbon') vaut False, None
double_consonne('reussite') vaut True, ‘s’
5) Ecrire une fonction envers qui prend en
argument une liste li
(attention, pas un mot, contrairement aux autres fonctions de cet
exercice) et qui renvoie une liste obtenue à partir de li
en inversant l’ordre des éléments.
6) Ecrire une fonction palindrome qui prend en
argument un mot et qui renvoie un booléen indiquant si le mot est un
palindrome. Un palindrome est un mot qui reste identique lorsqu’il
est lu de droite à gauche au lieu de l’ordre habituel de gauche à
droite.
Test:
palindrome('ici') vaut True
mais palindrome('aller') vaut False.
7) Ecrire une fonction mot_autorise prenant en
argument un mot et une liste de mots interdits, et qui renvoie True
si le mot est autorisé, et False
si le mot est interdit.
Comme les listes, les dictionnaires permettent de « stocker » des
données. Chaque élément d’un dictionnaire est composé de 2 parties, on
parle de pairs « clé/valeur ». Voici un exemple de dictionnaire :
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
Comme vous pouvez le constater, nous utilisons des accolades {}
pour définir le début et la fin du dictionnaire (alors que nous
utilisons des crochets [] pour les listes et les parenthèses pour les
tuples).
Dans le dictionnaire ci-dessus, « nom », « prenom » et « date de
naissance » sont des clés et « Durand », « Christophe » et « 29/02/1981 » sont
des valeurs.
La clé « nom » est associée à la valeur « Durand », la clé « prenom » est
associée à la valeur « Christophe » et la clé « date de naissance » est
associée à la valeur « 29/02/1981 ».
Les clés sont des chaînes de caractères ou des nombres. Les valeurs
peuvent être des chaînes de caractères, des nombres, des booléens…
Pour créer un dictionnaire, il est aussi possible de procéder comme suit :
La variable « mon_dico » référence un dictionnaire. Il est
possible d’afficher le contenu du dictionnaire référencé par la variable
« mon_dico » en saisissant « mon_dico » dans la console. Faites le test
après avoir exécuté le programme ci-dessous.
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
Il est possible d’afficher la valeur associée à une clé :
À faire vous-même 2
Soit le programme suivant :
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
print(f'Bonjour je suis {mon_dico["prenom"]} {mon_dico["nom"]}, je suis né le {mon_dico["date de naissance"]}')
Quel est le résultat attendu après l’exécution de ce programme ? Vérifiez votre réponse.
Il est facile d’ajouter un élément à un dictionnaire (les dictionnaires sont mutables)
À faire vous-même 3
Soit le programme suivant :
mon_dico = {"nom": "Durand", "prenom": "Christophe", "date de naissance": "29/02/1981"}
print(f'Bonjour je suis {mon_dico["prenom"]} {mon_dico["nom"]}, je suis né le {mon_dico["date de naissance"]}')
mon_dico['lieu naissance'] = "Bonneville"
print (f'à {mon_dico["lieu naissance"]}')
Quel est le résultat attendu après l’exécution de ce programme ? Vérifiez votre réponse.
L’instruction « del » permet du supprimer une paire « clé/valeur »
À faire vous-même 4
Quel est le contenu du dictionnaire référencé par la variable
« mes_fruits » après l’exécution du programme ci-dessous ? Vérifiez votre
réponse à l’aide de la console.
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
del mes_fruits["pomme"]
Quel est le contenu du dictionnaire référencé par la variable
« mes_fruits » après l’exécution du programme ci-dessus ? Vérifiez votre
réponse à l’aide de la console.
Il est possible de parcourir un dictionnaire à l’aide d’une boucle for. Ce parcours peut se faire selon les clés ou les valeurs.
Commençons par parcourir les clés à l’aide de la méthode « keys »
À faire vous-même 6
Tester le programme suivant :
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
print("liste des fruits :")
for fruit in mes_fruits.keys():
print(fruit)
La méthode values() permet de parcourir le dictionnaire selon les valeurs
À faire vous-même 7
Tester le programme suivant :
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
for qte in mes_fruits.values():
print(qte)
Enfin, il est possible de parcourir un dictionnaire à la fois sur les clés et les valeurs en utilisant la méthode items().
À faire vous-même 8
Tester le programme suivant :
mes_fruits = {"poire": 3, "pomme": 4, "orange": 2}
print ("Stock de fruits :")
for fruit, qte in mes_fruits.items():
print (f"{fruit} : {qte}")
Vous avez sans doute remarqué l’utilisation de deux variables (« fruit » et « qte ») au niveau du « for…in »
Voici ci dessous des slides sur les dictionnaires réalisés par:–Amir Charif–Lydie Du Bousquet–Aurélie Lagoutte–Julie Peyre–Florence Thiard
Il est possible de « stocker » plusieurs grandeurs dans une même
structure, ce type de structure est appelé une séquence. De façon plus
précise, nous définirons une séquence comme un ensemble fini et ordonné
d’éléments indicés de 0 à n-1 (si cette séquence comporte n éléments).
Rassurez-vous,
nous reviendrons ci-dessous sur cette définition. Nous allons étudier
plus particulièrement 2 types de séquences : les tuples et les tableaux
(il en existe d’autres que nous n’évoquerons pas ici).
Les tuples en Python
Comme déjà dit ci-dessus, un tuple est une séquence. Voici un exemple très simple :
mon_tuple = (5, 8, 6, 9)
Dans le code ci-dessus, la variable « mon_tuple » référence un tuple,
ce tuple est constitué des entiers 5, 8, 6 et 9. Comme indiqué dans la
définition, chaque élément du tuple est indicé (il possède un indice):
le premier élément du tuple (l’entier 5) possède l’indice 0
le deuxième élément du tuple (l’entier 8) possède l’indice 1
le troisième élément du tuple (l’entier 6) possède l’indice 2
le quatrième élément du tuple (l’entier 9) possède l’indice 3
Comment accéder à l’élément d’indice i dans un tuple ?
Simplement en utilisant la « notation entre crochets » :
À faire vous-même 1
Testez le code suivant :
mon_tuple = (5, 8, 6, 9)
a = mon_tuple[2]
Quelle est la valeur référencée par la variable a (utilisez la console pour répondre à cette question)?
La variable mon_tuple référence le tuple (5, 8, 6, 9), la variable a
référence l’entier 6 car cet entier 6 est bien le troisième élément du
tuple, il possède donc l’indice 2
ATTENTION : dans les séquences les indices commencent toujours à 0
(le premier élément de la séquence a pour indice 0), oublier cette
particularité est une source d’erreur « classique ».
À faire vous-même 2
Complétez le code ci-dessous (en remplaçant les ..) afin qu’après
l’exécution de ce programme la variable a référence l’entier 8.
mon_tuple = (5, 8, 6, 9)
a = mon_tuple[..]
Un tuple ne contient pas forcément des nombres entiers, il peut aussi
contenir des nombres décimaux, des chaînes de caractères, des
booléens…
À faire vous-même 3
Quel est le résultat attendu après l’exécution de ce programme ?
Grâce au tuple, une fonction peut renvoyer plusieurs valeurs :
À faire vous-même 4
Analysez puis testez le code suivant :
def add(a, b):
c = a + b
return (a, b, c)
mon_tuple = add(5, 8)
print(f"{mon_tuple[0]} + {mon_tuple[1]} = {mon_tuple[2]}")
Il faut bien comprendre dans l’exemple ci-dessus que la variable
mon_tuple référence un tuple (puisque la fonction « add » renvoie un
tuple), d’où la « notation entre crochets » utilisée avec mon_tuple
(mon_tuple[1]…)
La console permet d’afficher les éléments présents dans un tuple simplement en :
À faire vous-même 5
Après avoir exécuté le programme ci-dessous, saisissez mon_tuple dans la console.
mon_tuple = (5, 8, 6, 9)
Il est possible d’assigner à des variables les valeurs contenues dans un tuple :
À faire vous-même 6
a, b, c, d = (5, 8, 6, 9)
Quelle est la valeur référencée par la variable a ? La variable b ?
La variable c ? La variable d ? Vérifiez votre réponse à l’aide de la
console Python.
Les tableaux ou liste en Python
ATTENTION : Dans la suite nous allons employer le terme « tableau ».
Pour parler de ces « tableaux » les concepteurs de Python ont choisi
d’utiliser le terme de « list » (« liste » en français). Pour éviter toute
confusion,
notamment par rapport à des notions qui seront abordées en terminale,
le choix a été fait d’employer « tableau » à la place de « liste » (dans la
documentation vous rencontrerez le terme « list », cela ne devra pas vous
pertuber)
Il n’est pas possible de modifier un tuple après sa création (on parle
d’objet « immutable »), si vous essayez de modifier un tuple existant,
l’interpréteur Python vous renverra une erreur.
Les tableaux sont,comme les tuples, des séquences, mais à la
différence des tuples, ils sont modifiables (on parle d’objets
« mutables »).
Pour créer un tableau, il existe différentes méthodes : une de ces méthodes ressemble beaucoup à la création d’un tuple :
mon_tab = [5, 8, 6, 9]
Notez la présence des crochets à la place des parenthèses.
Un tableau est une séquence, il est donc possible de « récupérer » un
élément d’un tableau à l’aide de son indice (de la même manière que pour
un tuple)
À faire vous-même 7
Quelle est la valeur référencée par la variable ma_variable après
l’exécution du programme ci-dessous ? (utilisez la console pour vérifier
votre réponse)
mon_tab = [5, 8, 6, 9]
ma_variable = mon_tab[2]
N.B. Il est possible de saisir directement mon_tab[2] dans la console
sans passer par l’intermédiaire de la variable ma_variable
Il est possible de modifier un tableau à l’aide de la « notation entre crochets » :
À faire vous-même 8
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
mon_tab[2] = 15
Comme vous pouvez le constater avec l’exemple ci-dessus, l’élément
d’indice 2 (le nombre entier 6) a bien été remplacé par le nombre entier
15
Il est aussi possible d’ajouter un élément en fin de tableau à l’aide de la méthode « append » :
À faire vous-même 9
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
mon_tab.append(15)
L’instruction « del » permet de supprimer un élément d’un tableau en utilisant son index :
À faire vous-même 10
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
del mon_tab[1]
La fonction « len » permet de connaitre le nombre d’éléments présents dans une séquence (tableau et tuple)
À faire vous-même 11
Quelle est la valeur référencée par la variable nb_ele après l’exécution du programme ci-dessous ? (utilisez la console pour vérifier votre réponse)
mon_tab = [5, 8, 6, 9]
nb_ele = len(mon_tab)
Une petite parenthèse : on pourrait s’interroger sur l’intérêt
d’utiliser un tuple puisque le tableau permet plus de choses ! La
réponse est simple : les opérations
sur les tuples sont plus « rapides ». Quand vous savez que votre
tableau ne sera pas modifié, il est préférable d’utiliser un tuple à la
place d’un tableau.
la boucle « for » : parcourir les éléments d’un tableau
La boucle for… in permet de parcourir chacun des éléments d’une séquence (tableau ou tuple) :
À faire vous-même 12
Analysez puis testez le code suivant :
mon_tab = [5, 8, 6, 9]
for element in mon_tab:
print(element)
Quelques explications : comme son nom l’indique, la boucle « for » est
une boucle ! Nous « sortirons » de la boucle une fois que tous les
éléments du tableau mon_tab auront
été parcourus. element est une variable qui va :
au premier tour de boucle, référencer le premier élément du tableau (l’entier 5)
au deuxième tour de boucle, référencer le deuxième élément du tableau (l’entier 8)
au troisième tour de boucle, référencer le troisième élément du tableau (l’entier 6)
au quatrième tour de boucle, référencer le quatrième élément de le tableau (l’entier 9)
Une chose importante à bien comprendre : le choix du nom de la
variable qui va référencer les éléments du tableau les uns après les
autres (element) est totalement arbitraire,
il est possible de choisir un autre nom sans aucun problème, le code
suivant aurait donné exactement le même résultat :
mon_tab = [5, 8, 6, 9]
for toto in mon_tab:
print (toto)
Dans la boucle for… in il est possible d’utiliser la fonction prédéfinie range à la place d’un tableau d’entiers :
À faire vous-même 13
Analysez puis testez le code suivant :
for element in range(0, 5):
print (element)
Comme vous pouvez le constater, « range(0,5) » est, au niveau de la
boucle « for..in », équivalent au tableau [0,1,2,3,4], le code ci-dessous
donnerait le même résultat que le programme vu dans le « À faire
vous-même 12 » :
mon_tab = [0, 1, 2, 3, 4]
for element in mon_tab:
print (element)
ATTENTION : si vous avez dans un programme « range(a,b) », a est la
borne inférieure et b a borne supérieure. Vous ne devez surtout pas
perdre de vu que la borne inférieure est incluse, mais
que la borne supérieure est exclue.
Il est possible d’utiliser la méthode « range » pour « remplir » un tableau :
À faire vous-même 14
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = []
for element in range(0, 5):
mon_tab.append(element)
Créer un tableau par compréhension
Nous avons vu qu’il était possible de « remplir » un tableau en renseignant les éléments du tableau les uns après les autres :
mon_tab = [5, 8, 6, 9]
ou encore à l’aide de la méthode « append » (voir « À faire vous-même 13 »).
Il est aussi possible d’obtenir exactement le même résultat qu’au « À
faire vous-même 13 » en une seule ligne grâce à la compréhension de
tableau :
À faire vous-même 15
Quel est le contenu du tableau référencée par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
mon_tab = [p for p in range(0, 5)]
Les compréhensions de tableau permettent de rajouter une condition (if) :
À faire vous-même 16
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
l = [1, 7, 9, 15, 5, 20, 10, 8]
mon_tab = [p for p in l if p > 10]
Autre possibilité, utiliser des composants « arithmétiques » :
À faire vous-même 17
Quel est le contenu du tableau référencé par la variable mon_tab
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
l = [1, 7, 9, 15, 5, 20, 10, 8]
mon_tab = [p**2 for p in l if p < 10]
Rappel : p**2 permet d’obtenir la valeur de p élevée au carrée
Comme vous pouvez le remarquer, nous obtenons un tableau (mon_tab)
qui contient tous les éléments du tableau l élevés au carré à condition
que ces éléments de l soient inférieurs à 10.
Comme vous pouvez le constater, la compréhension de tableau permet
d’obtenir des combinaisons relativement complexes.
Travailler sur des « tableaux de tableaux »
Chaque élément d’un tableau peut être un tableau, on parle de tableau de tableau.
Voici un exemple de tableau de tableau :
m = [[1, 3, 4], [5 ,6 ,8], [2, 1, 3], [7, 8, 15]]
Le premier élément du tableau ci-dessus est bien un tableau ([1, 3,
4]), le deuxième élément est aussi un tableau ([5, 6, 8])…
Il est souvent plus pratique de présenter ces « tableaux de tableaux » comme suit :
m = [[1, 3, 4],
[5, 6, 8],
[2, 1, 3],
[7, 8, 15]]
Nous obtenons ainsi quelque chose qui ressemble beaucoup à un « objet mathématique » très utilisé : une matrice
Il est évidemment possible d’utiliser les indices de position avec
ces « tableaux de tableaux ». Pour cela nous allons considérer notre
tableau de tableaux comme une matrice, c’est à dire
en utilisant les notions de « ligne » et de « colonne ». Dans la matrice
ci-dessus :
En ce qui concerne les lignes :
1, 3, 4 constituent la première ligne
5, 6, 8 constituent la deuxième ligne
2, 1, 3 constituent la troisième ligne
7, 8, 15 constituent la quatrième ligne
En ce qui concerne les colonnes :
1, 5, 2, 7 constituent la première colonne
3, 6, 1, 8 constituent la deuxième colonne
4, 8, 3, 15 constituent la troisième colonne
Pour cibler un élément particulier de la matrice, on utilise la
notation avec « doubles crochets » : m[ligne][colonne] (sans perdre de vu
que la première ligne et la première colonne ont pour indice 0)
À faire vous-même 18
Quelle est la valeur référencée par la variable a après
l’exécution du programme ci-dessous ? (utilisez la console pour vérifier
votre réponse)
m = [[1, 3, 4],
[5, 6, 8],
[2, 1, 3],
[7, 8, 15]]
a = m[1][2]
Comme vous pouvez le constater, la variable a référence bien l’entier
situé à la 2e ligne (indice 1) et à la 3e colonne (indice 2),
c’est-à-dire 8.
À faire vous-même 19
Quel est le contenu du tableau référencé par la variable mm
après l’exécution du programme ci-dessous ? (utilisez la console pour
vérifier votre réponse)
m = [1, 2, 3]
mm = [m, m, m]
m[0] = 100
Comme vous pouvez le constater, la modification du tableau référencé
par la variable m entraine la modification du tableau référencé par la
variable mm (alors que
nous n’avons pas directement modifié le tableau référencé par mm).
Il faut donc être très prudent lors de ce genre de manipulation afin
d’éviter des modifications non désirées.
Il est possible de parcourir l’ensemble des éléments d’une matrice à l’aide d’une « double boucle for » :
À faire vous-même 20
Analysez puis testez le code suivant :
m = [[1, 3, 4],
[5, 6, 8],
[2, 1, 3],
[7, 8, 15]]
nb_colonne = 3
nb_ligne = 4
for i in range(0, nb_ligne):
for j in range(0, nb_colonne):
a = m[i][j]
print(a)
Voici ci dessous des slides sur les listes réalisés par:–Amir Charif–Lydie Du Bousquet–Aurélie Lagoutte–Julie Peyre–Florence Thiard
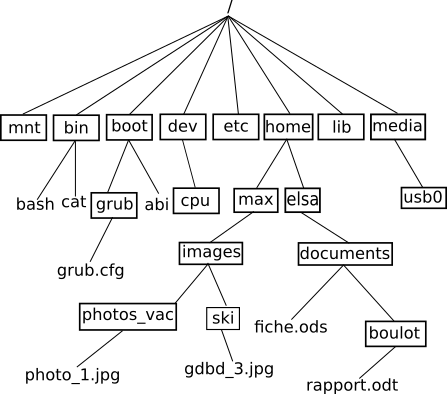 système de fichiers de type UNIX
système de fichiers de type UNIX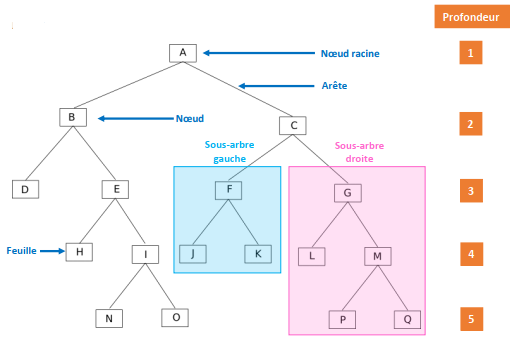


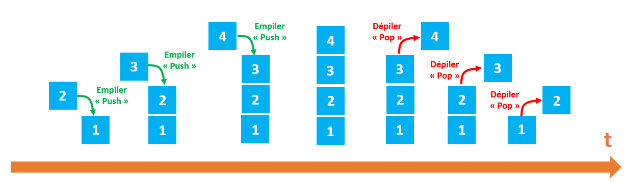
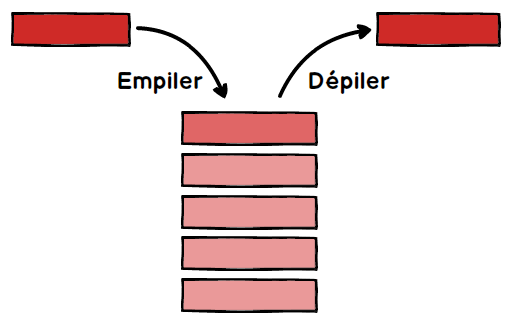
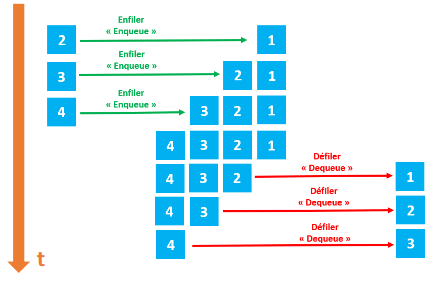
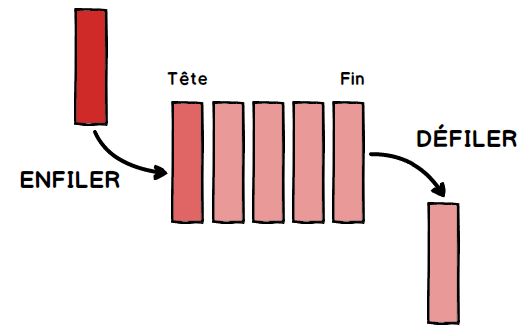
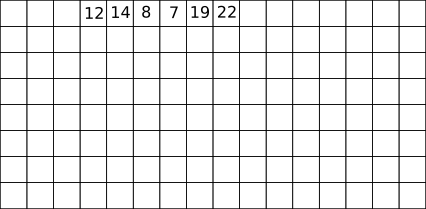
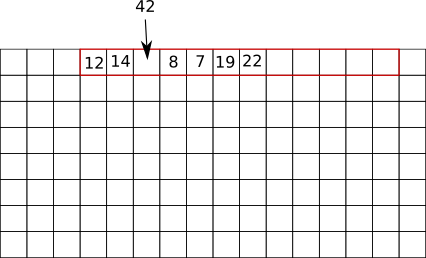 tableau dynamique
tableau dynamique