Présentation des d’algorithmes gloutons avec exemples et TD. cet article est une copie d’un article du site www.math93.com/ , vous pouvez le voir ici .
Voici une petite vidéo sur les algorithmes Glouton
- Présentation de la notion d’algorithme glouton.
- Les problèmes d’optimisation.
- Résoudre un problème d’optimisation : les algorithmes gloutons
- Le problème du rendu de monnaie.
- Le TD sur les algorithmes gloutons et le rendu de monnaie.
1. Présentation de la notion d’algorithme glouton
1.1. Les problèmes d’optimisation
L’optimisation est une branche des mathématiques cherchant à modéliser, à analyser et à résoudre les problèmes qui consistent à minimiser ou maximiser une fonction sur un ensemble.
Les problèmes d’optimisation classiques sont par exemple :
- la répartition optimale de tâches suivant des critères précis (emploi du temps avec plusieurs contraintes) ;
- le problème du rendu de monnaie ;
- la recherche d’un plus court chemin dans un graphe ;
- le problème du voyageur de commerce.
1.2. Résoudre un problème d’optimisation : les algorithmes gloutons
De nombreuses techniques informatiques sont susceptibles d’apporter une solution exacte ou approchée à ces problèmes.
- Recherche de toutes les solutions
La technique la plus basique pour résoudre ce type de problème d’optimisation consiste à énumérer de façon exhaustive toutes les solutions possibles, puis à choisir la meilleure. Cette approche par force brute, impose souvent un coût en temps trop important pour être utilisée.
- Les algorithmes gloutons
Un algorithme glouton (greedy algorithm) est un algorithme qui suit le principe de faire, étape par étape, un choix optimum local.
Au cours de la construction de la solution, l’algorithme résout une partie du problème puis se focalise ensuite sur le sous-problème restant à résoudre.
La méthode gloutonne consiste à choisir des solutions locales optimales d’un problème dans le but d’obtenir une solution optimale globale au problème.- Le principal avantage des algorithmes gloutons est leur facilité de mise en œuvre.
- Le principal défaut est qu’il ne renvoie pas toujours la solution optimale nous le verrons.
- Dans certaines situations dites canoniques, il arrive qu’ils renvoient non pas un optimum mais l’optimum d’un problème
2. Le problème du rendu de monnaie
Un achat dit en espèces se traduit par un échange de pièces et de billets. Dans la suite, les pièces désignent indifféremment les véritables pièces que les billets.
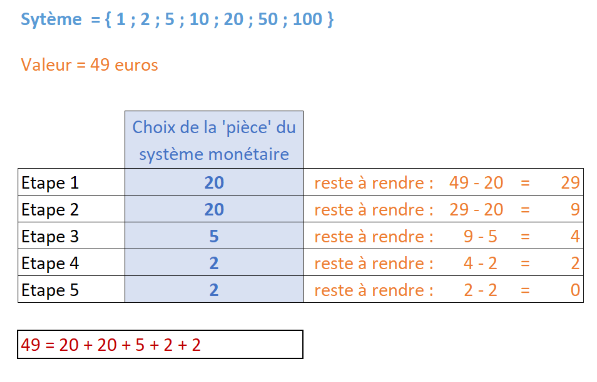
Supposons qu’un achat induise un rendu de 49 euros on considérant pour simplifier que les ‘pièces’ prennent les valeurs 1, 2, 5, 10, 20, 50, 100 euros. Quelles pièces peuvent être rendues ?
- 49=4×10+1×5+2×2
soit 7 pièces au total
(Quatre pièces de 10 euros, 1 pièce de 5 euros et deux pièces de 2 euros.) ou 49=9×5+2×2 soit 11 pièces au total ou 49=9×5+4×1 soit 13 pièces au total ou 49=49×1
- soit 49 pièces au total
Le problème du rendu de monnaie consiste à déterminer la solution avec le nombre minimal de pièces.
Rendre 49 euros avec un minimum de pièces est un problème d’optimisation. En pratique, tout individu met en œuvre un algorithme glouton.
- Il choisit d’abord la plus grandeur valeur de monnaie, parmi 1, 2, 5, 10, contenue dans 49 euros.
En l’occurrence, quatre fois une pièce de 10 euros. - La somme de 9 euros restant à rendre, il choisit une pièce de 5 euros,
- Puis deux pièces de 2 euros.

Solution optimale et système canonique du rendu de monnaie
Cette stratégie gagnante pour la somme de 49 euros l’est-elle pour n’importe quelle somme à rendre ?
- Un système canonique
- On peut montrer que l’algorithme glouton du rendu de monnaie renvoie une solution optimale pour le système monétaire français
{1,2,5,10,20,50,100} - Pour cette raison, un tel système de monnaie est qualifié de canonique.
- On peut montrer que l’algorithme glouton du rendu de monnaie renvoie une solution optimale pour le système monétaire français
- Des systèmes non canoniques
- D ’autres systèmes ne sont pas canoniques. L’algorithme glouton ne répond alors pas de manière optimale.
- Par exemple, avec le système {1,3,6,12,24,30},l’algorithme glouton répond en proposant le rendu : 49=30+12+6+1 soit 4 pièces alors que la solution optimale est 49=2×24+1
- soit 3 pièces.
3. Le TD sur les algorithmes gloutons et le rendu de monnaie
- Prérequis au TD
- Python : liste, parcours de listes.
- Python : liste, parcours de listes.
On cherche à implémenter un algorithme glouton de rendu de monnaie en ne considérant que des valeurs entières des pièces du système.
Par ailleurs, la plus petite pièce du système sera toujours 1, on est ainsi certain de pouvoir rendre la monnaie quelque soit la somme choisie.
Fonctionnement de l’algorithme glouton du rendu de monnaie
- On choisit un
systèmede monnaies, par exemple systeme=[1,2,5,10,20,50,100] - On choisit une
valeur, par exemple valeur=49 euros . - On choisit la plus grande ‘pièce’ du système inférieure à la valeur et on l’ajoute à la liste des pièces à rendre.
- On calcule le reste à rendre et on recommence jusqu’à obtenir un reste à rendre nul.
Exercice 1
- Écrire une une fonction python qui reçoit deux arguments – la somme à rendre et le système de monnaie – et qui renvoie la liste des pièces choisies par l’algorithme glouton.
- Tester votre fonction avec les valeurs et les systèmes proposés dans les exemples du cours ci-dessus.
- Inventez un système non canonique différent de celui de l’exemple (mais toujours de valeur minimale 1) et trouver un exemple qui le prouve.
Votre fonction devra donc donner une solution mais qui n’est pas optimale. - Complément : créer un programme (ou une autre fonction) qui va afficher toutes les informations suivantes :
49=4×10+1×5+2×2
Soit 7 pièces au total
C’est à dire : Quatre pièces de 10 euros, 1 pièce de 5 euros et deux pièces de 2 euros.
Aide pour l’exercice 1:
- Etape 1
- Définissons le système de pièces à l’aide d’un tableau nommé
systemeconstitué des valeurs des pièces classées par valeurs croissantes (de plus petite pièce 1). - On définit aussi une valeur à tester, les 49 euros de l’exemple ci-dessus, dans la variable
valeur. - Ainsi que l’indice
ide la plus grande des pièces desysteme.
- Définissons le système de pièces à l’aide d’un tableau nommé
# valeurs des pièces du système choisi
systeme = [1,2,5,10,20,50,100]
# valeur à tester (par exemple 49 euros)
valeur=49
# indice de la première pièce à comparer à la somme à rendre
i = len(systeme) - 1
- Etape 2 : Fonctionnement de l’algorithme
- On cherche à déterminer les pièces à rendre pour la variable
valeur. - Initialisations
- La somme à rendre à rendre est initialement stockée dans la variable
somme_a_rendre. On l’initialise donc àvaleur. liste_pieces, la liste des pièces à rendre est initialisée à une liste videi = len(systeme) - 1: indice de la première pièce à comparer à la somme à rendre
- La somme à rendre à rendre est initialement stockée dans la variable
- On boucle tant que
somme_a_rendre > 0- La variable
pieceprend la valeur de la pièce desystemed’indicei - Si
somme_a_rendre < piece
- Alors
ipend la valeuri-1
- Alors
- Sinon
- alors on ajoute la
pieceà la liste des pièces à rendreliste_pieces - on enlève la valeur de
piecedesomme_a_rendre
- alors on ajoute la
- La variable
- On renvoie la liste :
liste_pieces
- On cherche à déterminer les pièces à rendre pour la variable
Exercice 2
- On cherche maintenant à généraliser notre algorithme avec le système de pièces et de billets utilisées en Europe et des valeurs décimales.
- On va donc considérer un système composé de pièces et de billets :
- Les pièces (en euros) : 0,01 – 0,02 – 0,05 – 0,10 – 0,20 – 0,50 – 1 – 2 ;
- Les billets (en euros) : 5 – 10 – 20 – 50 – 100 – 200 – 500.
- Modifier donc votre programme afin qu’il affiche le nombre les pièces à rendre et les billets.
- Tester les avec plusieurs exemples.
- Et si il n’y avait ni billet de 5, ni billet de 10 euros.
Montrer avec un exemple bien choisi que la solution donnée par l’algorithme n’est pas optimale
Exercice 3 – Une pièce de 7 euros
- On peut se demander pourquoi il n’y a pas de pièce de 7 euros par exemple.
- En fait c’est parce que si tel était le cas, l’algorithme glouton de rendu de monnaie ne serait plus optimal.
- Tester votre algorithme en ajoutant une pièce de 7 euros dans le système.
- Trouver un exemple qui renvoie une solution qui n’est pas optimale.






{kind=link}
{kind=link}