fonction chercher : (tableau, clé) —-> booléen 1. Pour un tableau de taille 1, il contient la clé si valeur est la clé 2. On sépare le tableau en deux parties sensiblement de même taille (gauche et droite) 3. Le tableau contient la clé si chercher(gauche, clé) ou chercher(droite, clé) est vrai.
Exemple tableau = [4, 10, 20, 5] clé = 10 A-t-on clé dans tableau ? Exemple clé = 10 [4, 10, 20, 5]
diviser [4, 10] [20, 5]
diviser [4] [10] [20] [5]
combiner Faux ou Vrai Faux ou Faux
combiner Vrai ou Faux
combiner Vrai
Implémenter cette fonction sous python.
Exercice 2: Calcul y puissance x
On souhaite calculer N=752. La méthode basique consiste à multiplier le nombre 7 par lui-même 52 fois… Ce qui n’est pas très rapide !
L’idée consiste donc à diviser le problème en 2 : on va calculer 726× 726, c’est-à-dire( 726)2. Là, il n’y a plus que 26 + 1 opérations (26 multiplications pour calculer 726, et une dernière pour faire le carré du résultat.
On recommence ensuite avec 726 : on le calcule en faisant (713)2.
N se calcule alors en 13+1+1 opérations au lieu de 52 initialement.
On ne s’arrête pas là, bien entendu : on continue tant que l’on peut utiliser ce principe :
N=752
=(726)2
=((713)2)2
=[[(76)2×7]2]2
=[[((73)2)2×7]2]2
=[[((72×7)2)2×7]2]2
Le principe est, vous l’avez peut-être remarqué, récursif.
Implémentation en Python du “diviser pour régner”
Nous allons écrire une fonction “puissance(x,n)” basée sur ce paradigme, où x et n sont deux entiers (positif pour n). Pour cela, nous allons prendre en compte que:
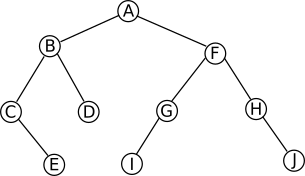
Avant d’entrer dans le vif du sujet (les algorithmes), nous allons un peu approfondir la notion d’arbre binaire :
À chaque nœud d’un arbre binaire, on associe une clé (« valeur » associée au nœud on peut aussi utiliser le terme « valeur » à la place de clé), un « sous-arbre gauche » et un « sous-arbre droit »
Soit l’arbre binaire suivant :
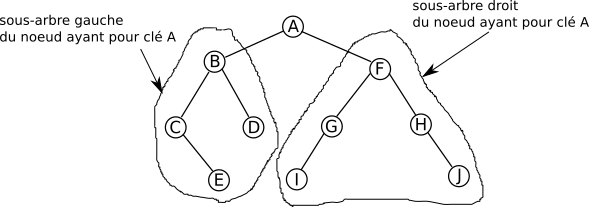
si on prend le nœud ayant pour clé A (le nœud racine de l’arbre) on a :
le sous-arbre gauche est composé du nœud ayant pour clé B, du nœud ayant pour clé C, du nœud ayant pour clé D et du nœud ayant pour clé E
le sous-arbre droit est composé du nœud ayant pour clé F, du nœud ayant pour clé G, du nœud ayant pour clé H, du nœud ayant pour clé I et du nœud ayant pour clé J
si on prend le noeud ayant pour clé B on a :
le sous-arbre gauche est composé du nœud ayant pour clé C et du nœud ayant pour clé E
le sous-arbre droit est uniquement composé du nœud ayant pour clé D
Un arbre (ou un sous-arbre) vide est noté NIL (NIL est une abréviation du latin nihil qui veut dire « rien »)
si on prend le nœud ayant pour clé G on a :
le sous-arbre gauche est uniquement composé du nœud ayant pour clé I
le sous-arbre droit est vide (NIL)
Il faut bien avoir en tête qu’un sous-arbre (droite ou gauche) est un arbre (même s’il contient un seul nœud ou pas de nœud de tout (NIL)).
Soit un arbre T : T.racine correspond au nœud racine de l’arbre T
Soit un nœud x :
x.gauche correspond au sous-arbre gauche du nœud x
x.droit correspond au sous-arbre droit du nœud x
x.clé correspond à la clé du nœud x
Il faut noter que si le nœud x est une feuille, x.gauche et x.droite sont des arbres vides (NIL)
Calculer la hauteur d’un arbre
Nous allons commencer à travailler sur les algorithmes en nous intéressant à l’algorithme qui permet de calculer la hauteur d’un arbre :
À faire vous-même 1
Étudiez cet algorithme :
VARIABLE
T : arbre
x : noeud
DEBUT
HAUTEUR(T) :
si T ≠ NIL :
x ← T.racine
renvoyer 1 + max(HAUTEUR(x.gauche), HAUTEUR(x.droit))
sinon :
renvoyer 0
fin si
FIN
N.B. la fonction max renvoie la plus grande valeur des 2 valeurs passées en paramètre (exemple : max(5,6) renvoie 6)
Cet algorithme est loin d’être simple, n’hésitez pas à écrire votre raisonnement sur une feuille de brouillon. Vous pourrez par exemple essayer d’appliquer cet algorithme sur l’arbre binaire ci-dessous. N’hésitez pas à poser des questions si nécessaire.
Si vraiment vous avez des difficultés à comprendre le fonctionnement de l’algorithme sur l’arbre ci-dessus, vous trouverez ici un petit calcul qui pourrait vous aider.
Comme vous l’avez sans doute remarqué, nous avons dans l’algorithme ci-dessus une fonction récursive. Vous aurez l’occasion de constater que c’est souvent le cas dans les algorithmes qui travaillent sur des structures de données telles que les arbres.
Calculer la taille d’un arbre
Nous allons maintenant étudier un algorithme qui permet de calculer le nombre de nœuds présents dans un arbre.
À faire vous-même 2
Étudiez cet algorithme :
VARIABLE
T : arbre
x : noeud
DEBUT
TAILLE(T) :
si T ≠ NIL :
x ← T.racine
renvoyer 1 + TAILLE(x.gauche) + TAILLE(x.droit)
sinon :
renvoyer 0
fin si
FIN
Cet algorithme ressemble beaucoup à l’algorithme étudié au « À faire vous-même 1 », son étude ne devrait donc pas vous poser de problème.
Appliquez cet algorithme à l’exemple suivant :
Il existe plusieurs façons de parcourir un arbre (parcourir un arbre = passer par tous les nœuds), nous allons en étudier quelques-unes :
Parcourir un arbre dans l’ordre infixe
À faire vous-même 3
Étudiez cet algorithme :
VARIABLE
T : arbre
x : noeud
DEBUT
PARCOURS-INFIXE(T) :
si T ≠ NIL :
x ← T.racine
PARCOURS-INFIXE(x.gauche)
affiche x.clé
PARCOURS-INFIXE(x.droit)
fin si
FIN
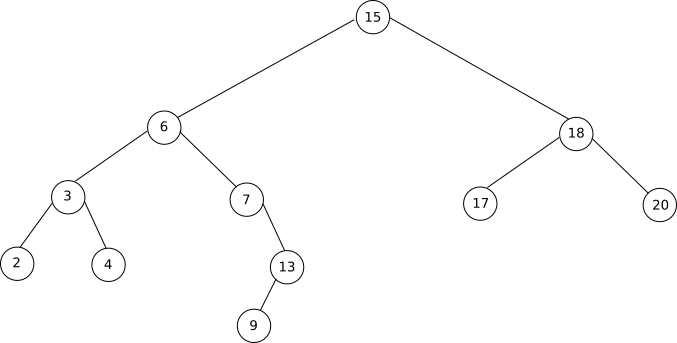
Vérifiez qu’en appliquant l’algorithme ci-dessus, l’arbre ci-dessous est bien parcouru dans l’ordre suivant : C, E, B, D, A, I, G, F, H, J
Parcourir un arbre dans l’ordre préfixe
À faire vous-même 4
Étudiez cet algorithme :
VARIABLE
T : arbre
x : noeud
DEBUT
PARCOURS-PREFIXE(T) :
si T ≠ NIL :
x ← T.racine
affiche x.clé
PARCOURS-PREFIXE(x.gauche)
PARCOURS-PREFIXE(x.droit)
fin si
FIN
Vérifiez qu’en appliquant l’algorithme ci-dessus, l’arbre ci-dessous est bien parcouru dans l’ordre suivant : A, B, C, E, D, F, G, I, H, J
Parcourir un arbre dans l’ordre suffixe
À faire vous-même 5
Étudiez cet algorithme :
VARIABLE
T : arbre
x : noeud
DEBUT
PARCOURS-SUFFIXE(T) :
si T ≠ NIL :
x ← T.racine
PARCOURS-SUFFIXE(x.gauche)
PARCOURS-SUFFIXE(x.droit)
affiche x.clé
fin si
FIN
Vérifiez qu’en appliquant l’algorithme ci-dessus, l’arbre ci-dessous est bien parcouru dans l’ordre suivant : E, C, D, B, I, G, J, H, F, A
Le choix du parcours infixe, préfixe ou suffixe dépend du problème à traiter, on pourra retenir pour les parcours préfixe et suffixe (le cas du parcours infixe sera traité un peu plus loin) que :
dans le cas du parcours préfixe, un nœud est affiché avant d’aller visiter ces enfants
dans le cas du parcours suffixe, on affiche chaque nœud après avoir affiché chacun de ses fils
Parcourir un arbre en largeur d’abord
À faire vous-même 6
Étudiez cet algorithme :
VARIABLE
T : arbre
Tg : arbre
Td : arbre
x : noeud
f : file (initialement vide)
DEBUT
PARCOURS-LARGEUR(T) :
enfiler(T, f) //on place la racine dans la file
tant que f non vide :
x ← defiler(f)
affiche x.clé
si x.gauche ≠ NIL :
Tg ← x.gauche
enfiler(Tg, f)
fin si
si x.droit ≠ NIL :
Td ← x.droite
enfiler(Td, f)
fin si
fin tant que
FIN
Vérifiez qu’en appliquant l’algorithme ci-dessus, l’arbre ci-dessous est bien parcouru dans l’ordre suivant : A, B, F, C, D, G, H, E, I, J
Selon vous, pourquoi parle-t-on de parcours en largeur ?
Il est important de bien noter l’utilisation d’une file (FIFO) pour cet algorithme de parcours en largeur. Vous noterez aussi que cet algorithme n’utilise pas de fonction récursive.
Arbre binaire de recherche
Un arbre binaire de recherche est un cas particulier d’arbre binaire. Pour avoir un arbre binaire de recherche :
il faut avoir un arbre binaire !
il faut que les clés de nœuds composant l’arbre soient ordonnables (on doit pouvoir classer les nœuds, par exemple, de la plus petite clé à la plus grande)
soit x un noeud d’un arbre binaire de recherche. Si y est un nœud du sous-arbre gauche de x, alors il faut que y.clé ⩽ x.clé. Si y est un nœud du sous-arbre droit de x, il faut alors que x.clé ⩽ y.clé
À faire vous-même 7
Vérifiez que l’arbre ci-dessus est bien un arbre binaire de recherche.
À faire vous-même 8
Appliquez l’algorithme de parcours infixe sur l’arbre ci-dessous :
Que remarquez-vous ?
Recherche d’une clé dans un arbre binaire de recherche
Nous allons maintenant étudier un algorithme permettant de rechercher une clé de valeur k dans un arbre binaire de recherche. Si k est bien présent dans l’arbre binaire de recherche, l’algorithme renvoie vrai, dans le cas contraire, il renvoie faux.
À faire vous-même 9
Étudiez l’algorithme suivant:
VARIABLE
T : arbre
x : noeud
k : entier
DEBUT
ARBRE-RECHERCHE(T,k) :
si T == NIL :
renvoyer faux
fin si
x ← T.racine
si k == x.clé :
renvoyer vrai
fin si
si k < x.clé :
ARBRE-RECHERCHE(x.gauche,k)
sinon :
ARBRE-RECHERCHE(x.droit,k)
fin si
FIN
À faire vous-même 10
Appliquez l’algorithme de recherche d’une clé dans un arbre binaire de recherche sur l’arbre ci-dessous. On prendra k = 13.
À faire vous-même 11
Appliquez l’algorithme de recherche d’une clé dans un arbre binaire de recherche sur l’arbre ci-dessous. On prendra k = 16.
Cet algorithme de recherche d’une clé dans un arbre binaire de recherche ressemble beaucoup à la recherche dichotomique vue en première. C’est principalement pour cette raison qu’en général, la complexité en temps dans le pire des cas de l’algorithme de recherche d’une clé dans un arbre binaire de recherche est O(log2(n))
À noter qu’il existe une version dite « itérative » (qui n’est pas récursive) de cet algorithme de recherche :
À faire vous-même 12
Étudiez l’algorithme suivant:
VARIABLE
T : arbre
x : noeud
k : entier
DEBUT
ARBRE-RECHERCHE_ITE(T,k) :
x ← T.racine
tant que T ≠ NIL et k ≠ x.clé :
x ← T.racine
si k < x.clé :
T ← x.gauche
sinon :
T ← x.droit
fin si
fin tant que
si k == x.clé :
renvoyer vrai
sinon :
renvoyer faux
fin si
FIN
Insertion d’une clé dans un arbre binaire de recherche
Il est tout à fait possible d’insérer un nœud y dans un arbre binaire de recherche (non vide) :
À faire vous-même 13
Étudiez l’algorithme suivant:
VARIABLE
T : arbre
x : noeud
y : noeud
DEBUT
ARBRE-INSERTION(T,y) :
x ← T.racine
tant que T ≠ NIL :
x ← T.racine
si y.clé < x.clé :
T ← x.gauche
sinon :
T ← x.droit
fin si
fin tant que
si y.clé < x.clé :
insérer y à gauche de x
sinon :
insérer y à droite de x
fin si
FIN
À faire vous-même 14
Appliquez l’algorithme d’insertion d’un nœud y dans un arbre binaire de recherche sur l’arbre ci-dessous. On prendra y.clé = 16.
Nous avons eu l’occasion d’étudier la structure d’une base de données relationnelle, nous allons maintenant apprendre à réaliser des requêtes, c’est-à-dire que nous allons apprendre à créer une base des données, créer des attributs, ajouter de données, modifier des données et enfin, nous allons surtout apprendre à interroger une base de données afin d’obtenir des informations.
Pour réaliser toutes ces requêtes, nous allons devoir apprendre un langage de requêtes : SQL (Structured Query Language). SQL est propre aux bases de données relationnelles, les autres types de bases de données utilisent d’autres langages pour effectuer des requêtes.
Pour créer une base de données et effectuer des requêtes sur cette dernière, nous allons utiliser le logiciel « DB Browser for SQLite » (il se stue dans APP22(W:)\SQLite_Browser_Portable ).
SQLite est un système de gestion de base de données relationnelle très répandu. Noter qu’il existe d’autres systèmes de gestion de base de données relationnelle comme MySQL ou PostgreSQL. Dans tous les cas, le langage de requête utilisé est le SQL (même si parfois on peut noter quelques petites différences). Ce qui sera vu ici avec SQLite pourra, à quelques petites modifications près, être utilisé avec, par exemple, MySQL.
Nous allons commencer par créer notre base de données :
À faire vous-même 1
Après avoir lancé le logiciel « DB Browser for SQLite », vous devriez obtenir ceci :
Cliquez sur Nouvelle base de données. Après avoir choisi un nom pour votre base de données (par exemple « db_livres.db »), vous devriez avoir la fenêtre suivante :
Cliquez alors sur Annuler
Notre base de données a été créée :
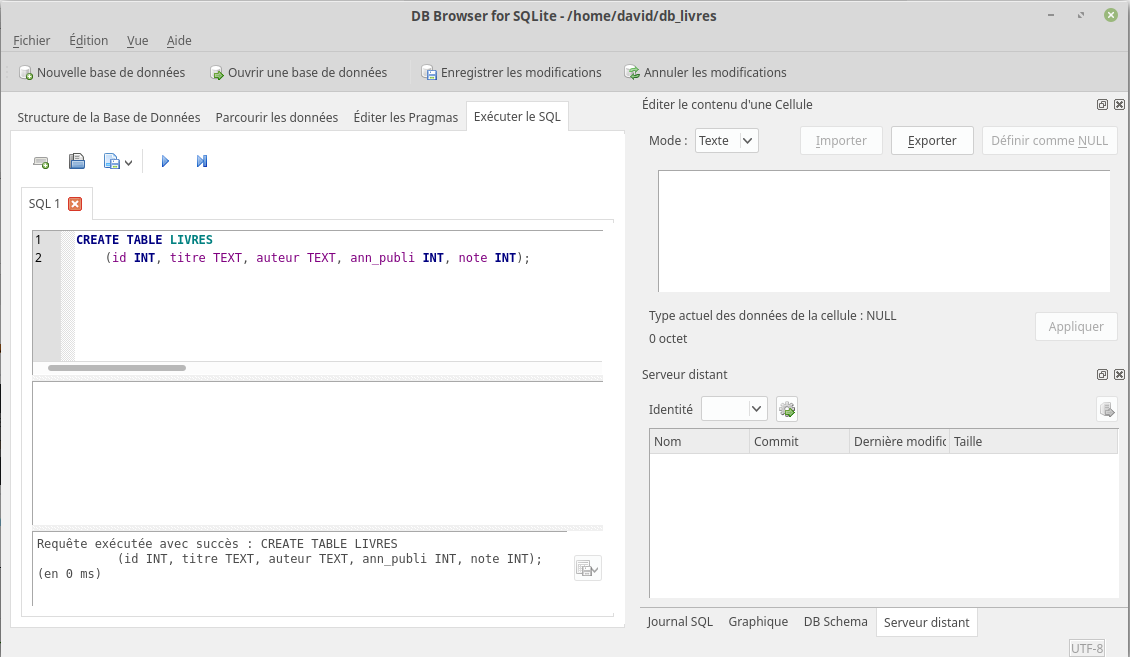
mais pour l’instant elle ne contient aucune table (aucune relation), pour créer une table, cliquez sur l’onglet « Exécuter le SQL ». On obtient alors :
Copiez-collez le texte ci-dessous dans la fenêtre « SQL 1 »
CREATE TABLE LIVRES
(id INT, titre TEXT, auteur TEXT, ann_publi INT, note INT);
Cliquez ensuite sur le petit triangle situé au-dessus de la fenêtre SQL 1 Exécuter (ou appuyez sur F5), vous devriez avoir ceci :
Comme indiqué dans la fenêtre, « Requête exécutée avec succès » !
Vous venez de créer votre première table.
Revenons sur cette première requête :
Le CREATE TABLE LIVRES ne devrait pas vous poser de problème : nous créons une nouvelle table nommée « LIVRES ».
La suite est à peine plus complexe :
nous créons ensuite les attributs :
id
titre
auteur
ann_pulbi
note
Nous avons pour chaque attribut précisé son domaine : id : entier (INT), titre : chaîne de caractères (TEXT), auteur : chaîne de caractères, ann_publi : entier et note : entier
L’attribut « id » va jouer ici le rôle de clé primaire. On peut aussi, par souci de sécurité (afin d’éviter que l’on utilise 2 fois la même valeur pour l’attribut « id »), modifier l’instruction SQL vue ci-dessus, afin de préciser que l’attribut « id » est bien notre clé primaire :
CREATE TABLE LIVRES
(id INT, titre TEXT, auteur TEXT, ann_publi INT, note INT, PRIMARY KEY (id));
Notre système de gestion de base de données nous avertira si l’on tente d’attribuer 2 fois la même valeur à l’attribut »id ».
Nous allons maintenant ajouter des données :
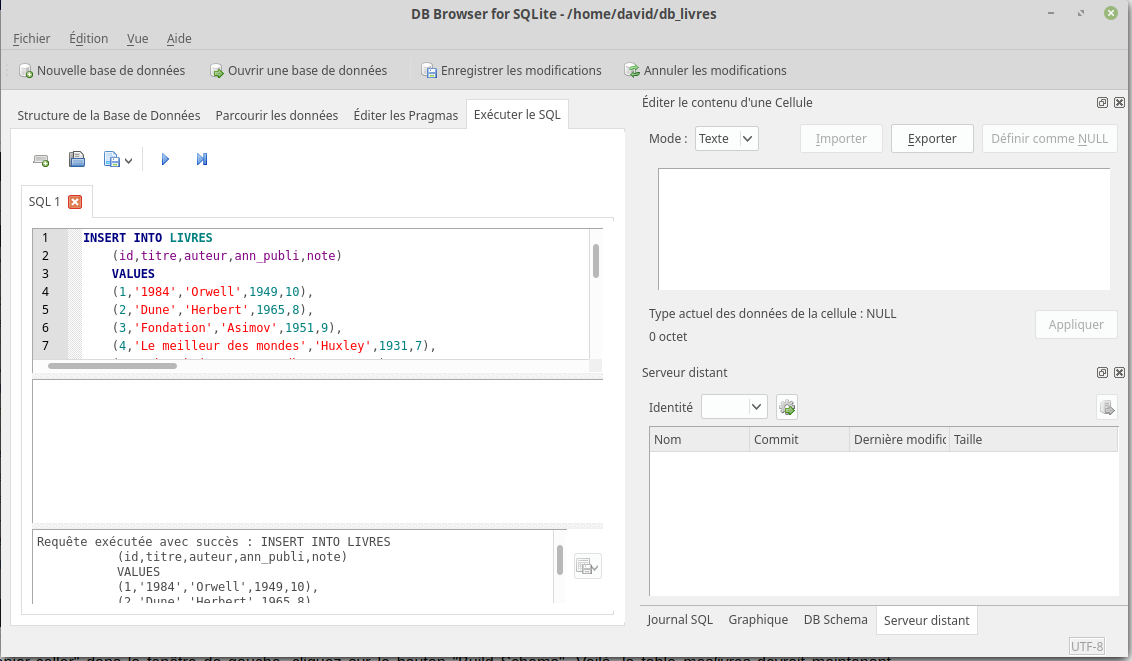
À faire vous-même 2
Toujours dans l’onglet « Exécuter le SQL », après avoir effacé la fenêtre SQL 1, copiez-collez dans cette même fenêtre la requête ci-dessous :
INSERT INTO LIVRES(id,titre,auteur,ann_publi,note)
VALUES
(1,'1984','Orwell',1949,10),
(2,'Dune','Herbert',1965,8),
(3,'Fondation','Asimov',1951,9),
(4,'Le meilleur des mondes','Huxley',1931,7),
(5,'Fahrenheit 451','Bradbury',1953,7),
(6,'Ubik','K.Dick',1969,9),
(7,'Chroniques martiennes','Bradbury',1950,8),
(8,'La nuit des temps','Barjavel',1968,7),
(9,'Blade Runner','K.Dick',1968,8),
(10,'Les Robots','Asimov',1950,9),
(11,'La Planète des singes','Boulle',1963,8),
(12,'Ravage','Barjavel',1943,8),
(13,'Le Maître du Haut Château','K.Dick',1962,8),
(14,'Le monde des Ā','Van Vogt',1945,7),
(15,'La Fin de l’éternité','Asimov',1955,8),
(16,'De la Terre à la Lune','Verne',1865,10);
Ici aussi, aucun problème, la requête a bien été exécutée :
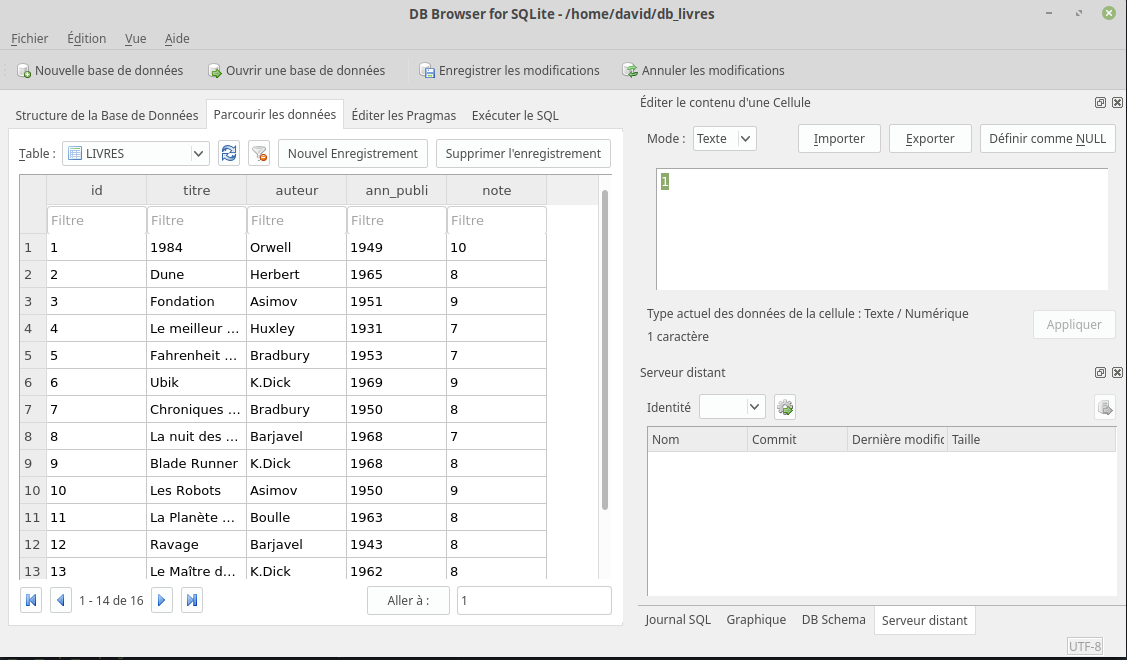
La table LIVRES contient bien les données souhaitées (onglet « Parcourir les données ») :
Nous allons apprendre à effectuer des requêtes d’interrogation sur la base de données que nous venons de créer.
Toutes les requêtes se feront dans la fenêtre SQL 1 de l’onglet « Exécuter le SQL »
À faire vous-même 3
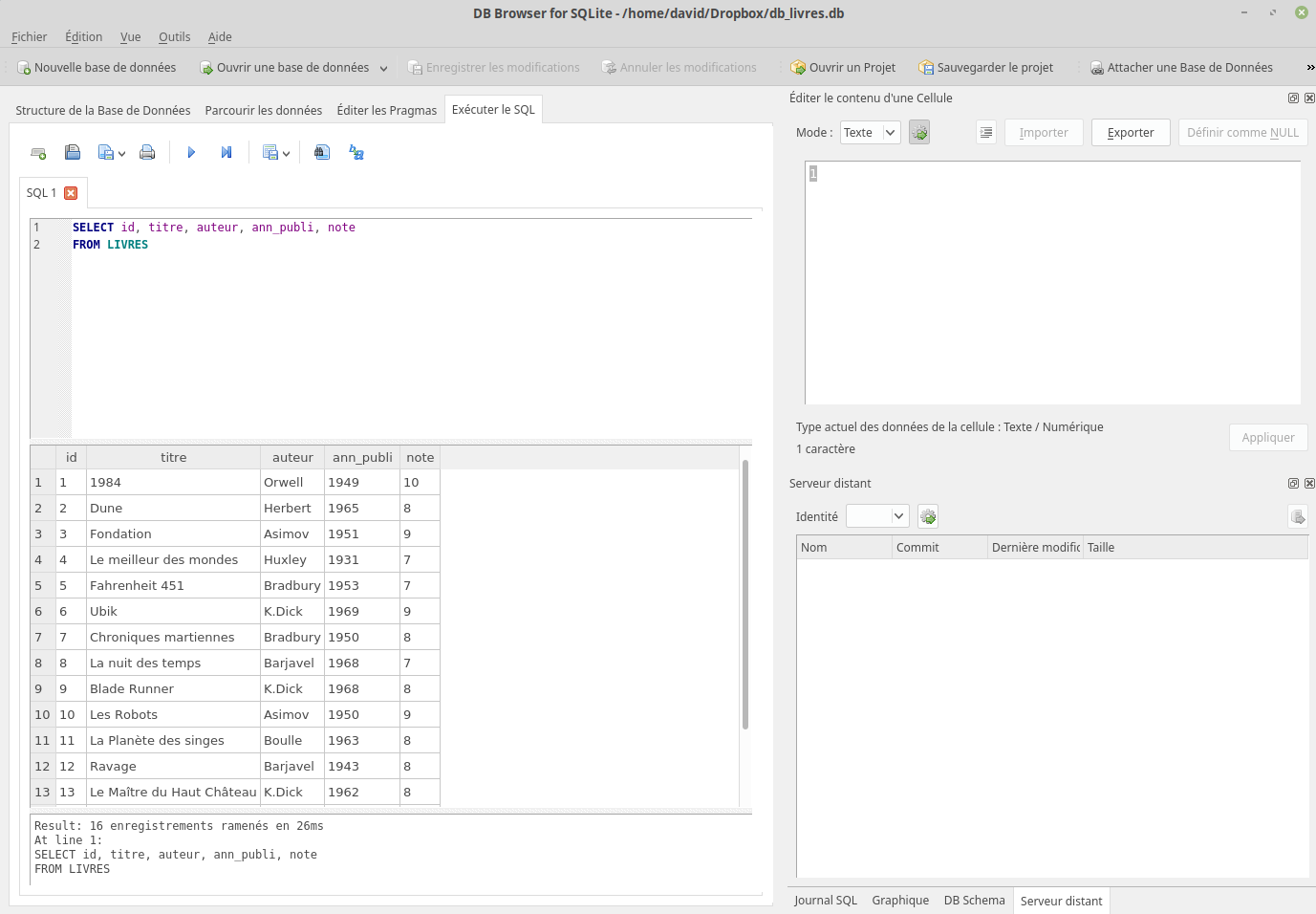
Saisissez la requête SQL suivante :
SELECT id, titre, auteur, ann_publi, note
FROM LIVRES
puis appuyez sur le triangle (ou la touche F5)
Après un temps plus ou moins long, vous devriez voir s’afficher ceci :
Comme vous pouvez le constater, notre requête SQL a permis d’afficher tous les livres. Nous avons ici 2 mots clés du langage SQL SELECTqui permet de sélectionner les attributs qui devront être « affichés » (je mets « affichés » entre guillemets, car le but d’une requête sql n’est pas forcément d’afficher les données) et FROMqui indique la table qui doit être utilisée.
Il est évidemment possible d’afficher seulement certains attributs (ou même un seul) :
À faire vous-même 4
Saisissez la requête SQL suivante :
SELECT titre, auteur
FROM LIVRES
Vérifiez que vous obtenez bien uniquement les titres et les auteurs des livres
À faire vous-même 5
Écrivez et testez une requête permettant d’obtenir uniquement les titres des livres.
N.B. Si vous désirez sélectionner tous les attributs, vous pouvez écrire :
SELECT *
FROM LIVRES
à la place de :
SELECT id, titre, auteur, ann_publi, note
FROM LIVRES
Pour l’instant nos requêtes affichent tous les livres, il est possible d’utiliser la clause WHEREafin d’imposer une (ou des) condition(s) permettant de sélectionner uniquement certaines lignes.
La condition doit suivre le mot-clé WHERE:
À faire vous-même 6
Saisissez et testez la requête SQL suivante :
SELECT titre, ann_publi
FROM LIVRES
WHERE auteur='Asimov'
Vérifiez que vous obtenez bien uniquement les livres écrits par Isaac Asimov.
À faire vous-même 7
Écrivez et testez une requête permettant d’obtenir uniquement les titres des livres écrits par Philip K.Dick.
Il est possible de combiner les conditions à l’aide d’un ORou d’un AND
À faire vous-même 8
Saisissez et testez la requête SQL suivante :
SELECT titre, ann_publi
FROM LIVRES
WHERE auteur='Asimov' AND ann_publi>1953
Vérifiez que nous obtenons bien le livre écrit par Asimov publié après 1953 (comme vous l’avez sans doute remarqué, il est possible d’utiliser les opérateurs d’inégalités).
À faire vous-même 9
D’après vous, quel est le résultat de cette requête :
SELECT titre
FROM LIVRES
WHERE auteur='K.Dick' OR note>=8
À faire vous-même 10
Écrire une requête permettant d’obtenir les titres des livres publiés après 1945 qui ont une note supérieure ou égale à 9.
Il est aussi possible de rajouter la clause SQL ORDER BY afin d’obtenir les résultats classés dans un ordre précis.
À faire vous-même 11
Saisissez et testez la requête SQL suivante :
SELECT titre
FROM LIVRES
WHERE auteur='K.Dick' ORDER BY ann_publi
Nous obtenons les livres de K.Dick classés du plus ancien ou plus récent.
Il est possible d’obtenir un classement en sens inverse à l’aide de la clause DESC
À faire vous-même 12
Saisissez et testez la requête SQL suivante :
SELECT titre
FROM LIVRES
WHERE auteur='K.Dick' ORDER BY ann_publi DESC
Nous obtenons les livres de K.Dick classés du plus récent au plus ancien.
À faire vous-même 13
Que se passe-t-il quand la clause ORDER BY porte sur un attribut de type TEXT ?
Vous pouvez constater qu’une requête du type :
SELECT auteur
FROM LIVRES
affiche plusieurs fois certains auteurs (les auteurs qui ont écrit plusieurs livres présents dans la base de données)
Il est possible d’éviter les doublons grâce à la clause DISTINCT
À faire vous-même 14
Saisissez et testez la requête SQL suivante :
SELECT DISTINCT auteur
FROM LIVRES
Nous avons vu précédemment qu’une base de données peut contenir plusieurs relations (plusieurs tables).
À faire vous-même 15
Créez une nouvelle base de données que vous nommerez par exemple db_livres_auteurs.db
À faire vous-même 16
Créez une table AUTEURS(id INT, nom TEXT, prenom TEXT, ann_naissance INT, langue_ecriture TEXT) à l’aide d’une requête SQL.
À faire vous-même 17
Créez une table LIVRES(id INT, titre TEXT, id_auteur INT, ann_publi INT, note INT) à l’aide d’une requête SQL.
À faire vous-même 18
Ajoutez des données à la table AUTEURS à l’aide de la requête SQL suivante :
Ajoutez des données à la table LIVRES à l’aide de la requête SQL suivante :
INSERT INTO LIVRES
(id,titre,id_auteur,ann_publi,note)
VALUES
(1,'1984',1,1949,10),
(2,'Dune',2,1965,8),
(3,'Fondation',3,1951,9),
(4,'Le meilleur des mondes',4,1931,7),
(5,'Fahrenheit 451',5,1953,7),
(6,'Ubik',6,1969,9),
(7,'Chroniques martiennes',5,1950,8),
(8,'La nuit des temps',7,1968,7),
(9,'Blade Runner',6,1968,8),
(10,'Les Robots',3,1950,9),
(11,'La Planète des singes',8,1963,8),
(12,'Ravage',7,1943,8),
(13,'Le Maître du Haut Château',6,1962,8),
(14,'Le monde des Ā',9,1945,7),
(15,'La Fin de l’éternité',3,1955,8),
(16,'De la Terre à la Lune',10,1865,10);
Nous avons 2 tables, grâce aux jointures nous allons pouvoir associer ces 2 tables dans une même requête.
En général, les jointures consistent à associer des lignes de 2 tables. Elles permettent d’établir un lien entre 2 tables. Qui dit lien entre 2 tables dit souvent clef étrangère et clef primaire.
Dans notre exemple l’attribut « id_auteur » de la tables LIVRES est bien une clé étrangère puisque cet attribut correspond à l’attribut « id » de la table « AUTEURS« .
À noter qu’il est possible de préciser au moment de la création d’une table qu’un attribut jouera le rôle de clé étrangère. Dans notre exemple, à la place d’écrire :
CREATE TABLE LIVRES
(id INT, titre TEXT, id_auteur INT, ann_publi INT, note INT, PRIMARY KEY (id));
grâce à cette précision, sqlite sera capable de détecter les anomalies au niveau de clé étrangère : essayez par exemple d’ajouter un livre à la table LIVRES avec l’attribut « id_auteur » égal à 11 !
Passons maintenant aux jointures :
À faire vous-même 20
Saisissez et testez la requête SQL suivante :
SELECT *
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
Le « FROM LIVRES INNER JOIN AUTEURS » permet de créer une jointure entre les tables LIVRES et AUTEURS (« rassembler » les tables LIVRES et AUTEURS en une seule grande table). Le « ON LIVRES.id_auteur = AUTEURS.id » signifie qu’une ligne quelconque A de la table LIVRES devra être fusionnée avec la ligne B de la table AUTEURS à condition que l’attribut id de la ligne A soit égal à l’attribut id_auteur de la ligne B.
Par exemple, la ligne 1 (id=1) de la table LIVRES (que l’on nommera dans la suite ligne A) sera fusionnée avec la ligne 1 (id=1) de la table AUTEURS (que l’on nommera dans la suite B) car l’attribut id_auteur de la ligne A est égal à 1 et l’attribut id de la ligne B est aussi égal à 1.
Autre exemple, la ligne 1 (id=1) de la table LIVRES (que l’on nommera dans la suite ligne A) ne sera pas fusionnée avec la ligne 2 (id=2) de la table AUTEURS (que l’on nommera dans la suite B’) car l’attribut id_auteur de la ligne A est égal à 1 alors que l’attribut id de la ligne B’ est égal à 2.
Cette notion de jointure n’est pas évidente, prenez votre temps pour bien réfléchir et surtout n’hésitez pas à poser des questions.
À faire vous-même 21
Saisissez et testez la requête SQL suivante :
SELECT *
FROM AUTEURS
INNER JOIN LIVRES ON LIVRES.id_auteur = AUTEURS.id
Comme vous pouvez le constater, le résultat est différent, cette fois-ci ce sont les lignes de la table LIVRES qui viennent se greffer sur la table AUTEURS.
Dans le cas d’une jointure, il est tout à fait possible de sélectionner certains attributs et pas d’autres :
À faire vous-même 22
Saisissez et testez la requête SQL suivante :
SELECT nom, prenom, titre
FROM AUTEURS
INNER JOIN LIVRES ON LIVRES.id_auteur = AUTEURS.id
À faire vous-même 23
Saisissez et testez la requête SQL suivante :
SELECT titre,nom, prenom
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
Si un même nom d’attribut est présent dans les 2 tables (par exemple ici l’attribut id), il est nécessaire d’ajouter le nom de la table devant afin de pouvoir les distinguer (AUTEURS.id et LIVRES.id)
À faire vous-même 24
Saisissez et testez la requête SQL suivante :
SELECT titre,AUTEURS.id,nom, prenom
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
Il est possible d’utiliser la clause WHERE dans le cas d’une jointure :
À faire vous-même 25
Saisissez et testez la requête SQL suivante :
SELECT titre,nom, prenom
FROM LIVRES
INNER JOIN AUTEURS ON LIVRES.id_auteur = AUTEURS.id
WHERE ann_publi>1950
Enfin, pour terminer avec les jointures, vous devez savoir que nous avons abordé la jointure la plus simple (INNER JOIN). Il existe des jointures plus complexes (CROSS JOIN, LEFT JOIN, RIGHT JOIN), ces autres jointures ne seront pas abordées ici.
Nous en avons terminé avec les requêtes d’interrogation, intéressons-nous maintenant aux requêtes de mise à jour (INSERT, UPDATE, DELETE).
Nous allons repartir avec une base de données qui contient une seule table :
À faire vous-même 26
Créez une nouvelle base de données que vous nommerez par exemple db_livres2.db
À faire vous-même 27
Créez une table LIVRES à l’aide de la requête SQL suivante :
CREATE TABLE LIVRES
(id INT, titre TEXT, auteur TEXT, ann_publi INT, note INT, PRIMARY KEY (id));
À faire vous-même 28
Ajoutez des données à la table LIVRES à l’aide de la requête SQL suivante :
INSERT INTO LIVRES
(id,titre,auteur,ann_publi,note)
VALUES
(1,'1984','Orwell',1949,10),
(2,'Dune','Herbert',1965,8),
(3,'Fondation','Asimov',1951,9),
(4,'Le meilleur des mondes','Huxley',1931,7),
(5,'Fahrenheit 451','Bradbury',1953,7),
(6,'Ubik','K.Dick',1969,9),
(7,'Chroniques martiennes','Bradbury',1950,8),
(8,'La nuit des temps','Barjavel',1968,7),
(9,'Blade Runner','K.Dick',1968,8),
(10,'Les Robots','Asimov',1950,9),
(11,'La Planète des singes','Boulle',1963,8),
(12,'Ravage','Barjavel',1943,8),
(13,'Le Maître du Haut Château','K.Dick',1962,8),
(14,'Le monde des Ā','Van Vogt',1945,7),
(15,'La Fin de l’éternité','Asimov',1955,8),
(16,'De la Terre à la Lune','Verne',1865,10);
Nous avons déjà eu l’occasion de voir la requête permettant d’ajouter une entrée (utilisation d’INSERT)
À faire vous-même 29
Que va faire cette requête ? Vérifiez votre réponse en l’exécutant et en faisant une requête « SELECT * FROM LIVRES« .
INSERT INTO LIVRES
(id,titre,auteur,ann_publi,note)
VALUES
(17,'Hypérion','Simmons',1989,8);
À faire vous-même 30
Écrivez et testez une requête permettant d’ajouter le livre de votre choix à la table LIVRES.
« UPDATE » va permettre de modifier une ou des entrées. Nous utiliserons « WHERE« , comme dans le cas d’un « SELECT« , pour spécifier les entrées à modifier.
Voici un exemple de modification :
À faire vous-même 31
Que va faire cette requête ? Vérifiez votre réponse en l’exécutant et en faisant une requête « SELECT * FROM LIVRES« .
UPDATE LIVRES
SET note=7
WHERE titre = 'Hypérion'
À faire vous-même 32
Écrivez une requête permettant d’attribuer la note de 10 à tous les livres écrits par Asimov publiés après 1950. Testez cette requête.
« DELETE » est utilisée pour effectuer la suppression d’une (ou de plusieurs) entrée(s). Ici aussi c’est le « WHERE » qui permettra de sélectionner les entrées à supprimer.
À faire vous-même 33
Que va faire cette requête ? Vérifiez votre réponse en l’exécutant et en faisant une requête « SELECT * FROM LIVRES« .
DELETE FROM LIVRES
WHERE titre='Hypérion'
À faire vous-même 34
Écrivez une requête permettant de supprimer les livres publiés avant 1945. Testez cette requête.
Dans la section
précédente, vous avez utilisé un logiciel de traitement d’image (Photofiltre)
qui contient différents algorithmes permettant de modifier automatiquement des
images. Dans un appareil photo ou un smartphone, il y a aussi de tels types
d’algorithmes. Ici, vous allez programmer vous-mêmes en Python différents
algorithmes permettant de modifier des images.
INDISPENSABLE : Pour travailler avec Python, il faut créer un répertoire (par exemple travail) dans lequel vous enregistrerez à la fois vos fichiers Python (format .py) et vos images (format .png)
A la fin
de la section, vous zipperez (= clic droit > compresser) ce répertoire
contenant l’intégralité des fichiers .py et .png pour nous le rendre avec votre
compte-rendu.
A faire vous-même 0 : Configurer le logiciel Thonny dans lequel on va programmer en Python
Ouvrez le logiciel Thonny (faire une recherche avec la loupe)
Une boite de dialogue apparaît avec le message suivant : « Can’t find backend ‘LocalCPython’. Please select another backend from options »
ouvrir le menu Outils > Options > Onglet Interpéteur
choisir l’option par défaut : « Le même interpréteur qui exécute Thonny »
Ensuite, il est nécessaire d’importer la librairie PILLOW (Python Imaging Library) qui fournit les outils nécessaires pour les manipulations d’images :
de nouveau, ouvrir le Menu Outil > Gérer les paquets…
écrire « Pillow » dans la barre de recherche et cliquer sur rechercher
Cliquer sur le lien « pillow » dans la liste obtenue
A faire vous-même 1 : Créer une image avec Python
Voici un script qui
génère deux images en couleurs RVB (=RGB en anglais) de dimension 100 x 100.
Tapez-le dans l’éditeur de script de Thonny (fenêtre du haut) et enregistrez-le sous le nom afvm1.pydans votre dossier de travailcréé précédemment.
Vérifiez que vous avez 2 images créées dans le dossier de travail(sinon demander de l’aide)
Lancez le logiciel Photofiltre et ouvrez les 2 images créées
Expliquez
la couleur de l’image afvm1_1.png
Pour modifier la couleur de l’image, il suffit de modifier la couleur de chaque pixel.
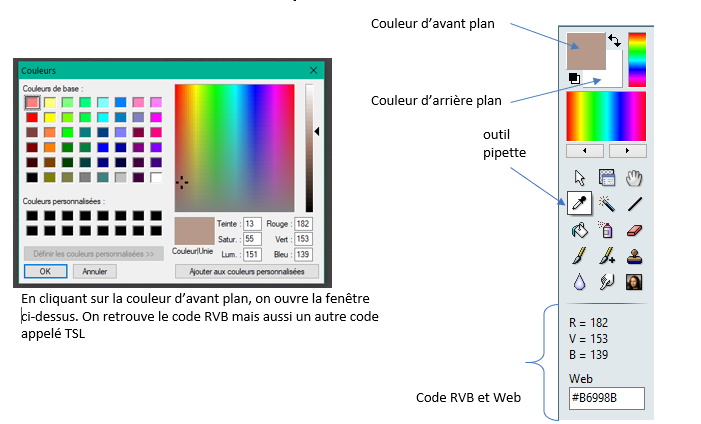
On va utiliser la commande putpixel((x,y), (a, b, c)) qui permet de colorer le pixel de coordonnées (x, y) avec la couleur RVB (a, b, c) où a, b et c sont les valeurs de luminance de chaque canal, comprises entre 0 et 255.
Remarque : x est le n° de colonne et y est le n° de ligne. Le 1er pixel en haut à gauche a pour coordonnées (0,0)
A faire vous-même 2 : mettre de la couleur
Dans l’éditeur Thonny, modifiez le script précédent en ajoutant la boucle « for » suivante.
Attention !
respectez l’indentation qui délimite les blocs de code (Elle se fait avec la touche de tabulation « tab »)
n’oubliez pas les « deux-points » : à la fin de la ligne for
from PIL import Imageim=Image.new("RGB", (100, 100))for x in range (100):
for y in range(100):
im.putpixel((x,y),(0,255,0))im.save("afvm2.png")
Expliquez
ce que produit la boucle ajoutée sur l’image.
Remplacez
la boucle par celle donnée ci-dessous et expliquez le résultat.
for x in range (50):
for y in range (50,100):
im.putpixel((x,y),(0,255,0))
A faire vous-même 3 : coder des drapeaux
Le script suivant permet de produire le drapeau français sous forme d’une image de dimension 120×100 pixels. Une première boucle « for » permet de parcourir les lignes de l’image. Les boucles for imbriquées (attention aux indentations) parcourent les colonnes dans un rectangle donné et y affectent une couleur.
from PIL import Image
col=120
lgn=100
im=Image.new("RGB", (col,lgn))
#il y a 3 bandes verticales, on définit la variable bande :
bande=col//3
for y in range (100):
for x in range (bande):
im.putpixel((x,y),(0,0,255))
for x in range (bande, (2*bande)):
im.putpixel((x,y),(255,255,255))
for x in range ((2*bande), col):
im.putpixel((x,y),(255,0,0))
im.save("france.png")
Après avoir compris le script précédent, vous allez le modifier pour produire d’autres drapeaux. Pensez à enregistrer votre script modifié sous un autre nom et à modifier également le nom de l’image enregistrée par python pour ne pas écraser l’image précédente.
Enregistrez vos différentes versions de script jusqu’à ce que cela fonctionne. Vous joindrez vos scripts python afvm3-irlande et afm3-colombie à votre compte-rendu.
Modifiez les arguments de la commande putpixel() pour reproduire le drapeau irlandais. (pour avoir le code RGV des couleurs, vous pouvez les sélectionner sur une image avec Pixie ou avec la pipette de Photofiltre)
Pour ceux qui aiment les défis : plus difficile : modifiez les arguments de la commande putpixel() pour reproduire le drapeau colombien
A faire vous-même 4 : apporter des nuances
Avec quelques petites astuces, on peut aussi produire des dégradés assez facilement. Voici un script qui permet d’obtenir deux dégradés de bleu différents.
from PIL import Image
largeur = 255
hauteur = 255
im=Image.new('RGB', (largeur, hauteur))
for x in range(largeur):
for y in range(hauteur):
im.putpixel((x, y), (0, 0, y))
im2=Image.new('RGB', (largeur, hauteur))
for x in range(largeur):
for y in range(hauteur):
im2.putpixel((x, y), (0, 0, x))
im.save("camaieubleu1.png")
im2.save("camaieubleu2.png")
Expliquez
la ligne 7 du script précédent.
Expliquez
la différence entre les 2 images.
Modifiez
le script pour produire le dégradé suivant et enregistrer l’image sous le nom degrade.png
Dans un logiciel de traitement d’image comme Photofiltre, ou celui qui est présent dans l’appareil photo, il est possible de faire des corrections automatiques comme passer l’image en négatif.
Le principe de
l’algorithme est de donner pour chaque pixel la couleur inverse : cette couleur
est calculée selon le principe suivant :
A faire vous-même 5 : l’image en négatif
Enregistrez
une image de votre choix dans votre répertoire de travail (pensez à choisir une
image dont la licence vous permet sa modification)
Voici une partie du
script permettant de créer le même effet négatif.
La commande pix = img.getpixel((x,y)) permet d’affecter dans une variable pix les valeurs des canaux RVB extraites du pixel de coordonnées (x,y).
On peut exprimer ces valeurs sous forme d’un 3-tuple (c’est-à-dire une collection de 3 valeurs, ici correspondant aux 3 canaux RVG) : p = (pix[0], pix[1], pix[2]) que l’on peut affecter à une variable (ici p) pour l’utiliser ensuite.
Remarque : les indices entre [ ] permettent d’accéder aux différents éléments du tuple. Pour accéder à un élément d’indice i d’un tuple t , on écrit t[i]
On veut transformer
chaque pixel de l’image (variablepix) en son négatif (variable pixneg). Trouvez comment calculer pixneg à partir
de pix.
L’extrait de script
ci-dessous permet d’ouvrir l’image que vous avez enregistrée, puis de créer une
nouvelle image qui sera son négatif. Il manque dans le script suivant 3
lignes (respectez les indentations !) qui permettent de passer l’image en
négatif.
À vous
de les écrire et de tester le résultat. Vous joindrez vos images et votre
script à votre compte-rendu.
from PIL import Image
img = Image.open(MonImage)
col,lgn = img.size
imgF = Image.new(img.mode,img.size)
print("Patientez pendant l'exécution du script …")
for x in range(col):
for y in range(lgn):
...
...
...
print("… C'est fait !, voir le résultat avec Photofiltre")
imgF.save("image_negatif.png")
Parmi les retouches d’images très utilisées pour
incruster un logo, un copyright ou une signature dans une image, il y a la
fusion de deux images. Il s’agit de transformer plus ou moins légèrement la
couleur des pixels de manière à ce que l’incrustation ne puisse pas être enlevée
facilement.
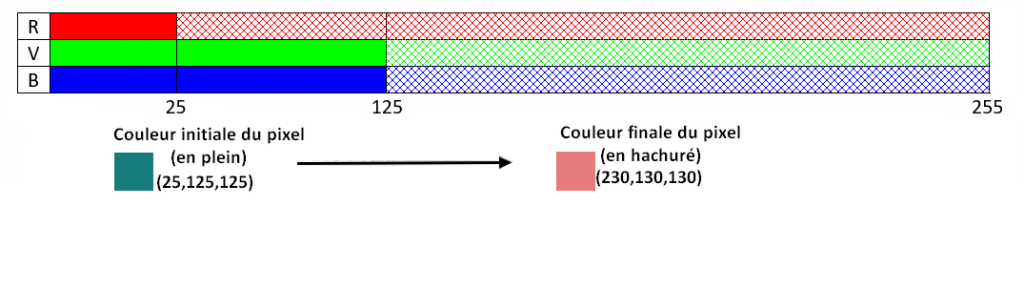
L’opération mathématique à appliquer pour modifier l’encodage des pixels est la suivante :
(R1, V1,
B1) est le
3-tuple de l’image 1,
(R2, V2,
V2) est le 3-tuple
de l’image 2
a est le coefficient de dominance d’une image sur l’autre, dont la valeur est comprise entre 0 et 1.
A faire vous-même 6 : fusion d’images
Utilisez
les informations ci-dessus pour compléter le script suivant de façon à obtenir
une fusion des drapeaux de la France et de la Colombie.
Astuce : les valeurs (R,V,B) d’un pixel sont obligatoirement des entiers à utilisez int()
La ligne 2 indique qu’il faudra entrer la valeur de a dans le shell (fenêtre de droite). Vous pourrez essayer différentes valeurs de a et comparer les images produites. Dans ce cas, pensez à modifier le nom du fichier enregistré (ligne 17) sous peine d’écraser le fichier précédent.
(Vous pouvez bien sûr utiliser des images de votre choix dans ce script, mais
les 2 images doivent avoir les mêmes dimensions)
from PIL import Image
a=float(input("Entrez la valeur de a : "))
im1 = Image.open('france.png')
im2 = Image.open('colombie.png')
largeur,hauteur = im1.size
im = Image.new('RGB', (largeur, hauteur))
for x in range(largeur):
for y in range(hauteur):
pix1 = im1.getpixel((x,y))
pix2 = im2.getpixel((x,y))
fusion = ..........................
im.putpixel((x,y),fusion)
im.save('fusion.jpg')
Commençons par un bref historique de la photo sur cette vidéo:
La photo : de l’argentique au numérique
Revenons un petit peu en arrière à l’époque du Noir et Blanc:
Bien entendu, le codage en noir et blanc ne donne pas des images de bonne qualité !
On appelle profondeur
de couleur le nombre de bits utilisés pour coder la couleur d’un pixel.
Pour une image en noir et blanc, la profondeur est de 2 bits. Cela ne suffit
pas pour donner une image correcte d’un ensemble complexe : en fait, la
photographie en « noir et banc », n’est pas codée en noir et banc,
mais en nuances de gris.
Ces 2 images correspondent
à une même prise de vue, mais l’une est en noir et blanc (image en noir et blanc)
et l’autre en nuances de gris (= image monochrome)
Souris en Noir et Blanc
La même souris, en nuances de gris
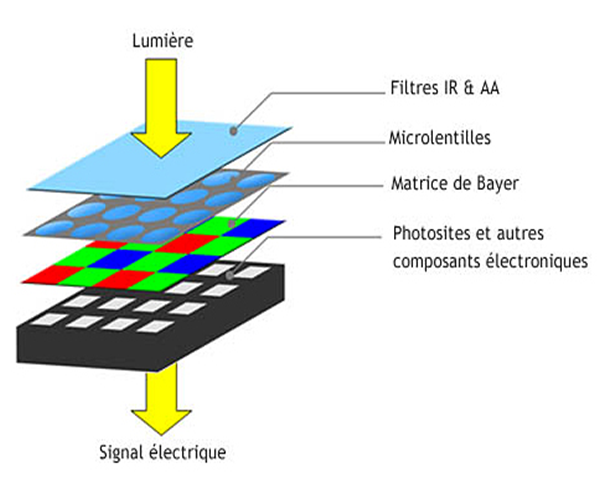
Un capteur photographique (dans un appareil photo ou un smartphone) contient des photosites : il s’agit de composants électroniques qui convertissent l’énergie lumineuse en tension électrique. Les tensions électriques seront converties en valeurs numériques par l’ordinateur afin de reconstituer les pixels.
A faire vous-même 1: codage en niveau de gris
Dans les travaux précédents, vous avez utilisé des images en noir et
blanc : chaque pixel était encodé sur 1 bit. Pour avoir des nuances de
gris, il est nécessaire d’avoir un encodage plus complexe utilisant davantage
de bits pour un pixel. Par exemple, chaque bit pouvant prendre 2 valeurs, avec
2 bits, on peut obtenir 4 nuances.
En général, pour une image monochrome, la profondeur
de couleur est de 8 bits : combien de nuances de gris sont possibles ?
Une photographie en couleur rendra encore mieux la
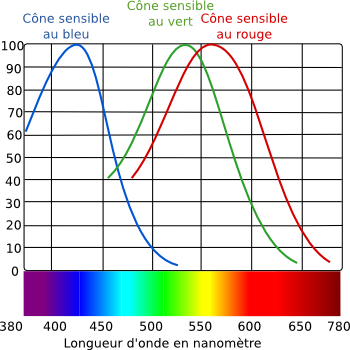
réalité. Dans l’œil humain, la rétine contient des cellules sensibles au
changement de luminosité (les bâtonnets) et des cellules sensibles à des radiations
particulières de la lumière : les cônes. Il existe 3 types de cônes : ceux qui
sont sensibles aux radiations bleues, ceux qui sont sensibles au vert et ceux
qui captent plutôt les rouges. Grâce à
ces 3 types de cônes, on peut voir toutes les couleurs par synthèse additive.
Ces 3 couleurs de lumière sont dites primaires.
Pour obtenir une photographie en couleurs, il y a devant
le capteur photographique des filtres colorés comme la matrice Bayer RVB
(Rouge, Vert, Bleu). On utilise donc un codage en Rouge/Vert/bleu.
La matrice Bayer est composée de 50 % de filtres verts (car
l’œil humain est capable de distinguer de très nombreuses nuances de verts), 25
% de filtres rouges et autant de bleus.
Un pixel sera donc composé des informations en luminance
des photosites par synthèse additive des couleurs primaires R, V, B
Expliquez en quoi consiste la synthèse additive (si
besoin, faites une recherche)
On codera donc un
pixel à l’aide d’un triplet de valeurs (par exemple 247, 56, 98). La première
valeur donnant l’intensité du canal rouge, la deuxième valeur donnant
l’intensité du canal vert et la troisième valeur donnant l’intensité du canal
bleu (RVB ou RGB en anglais).
Expliquez pourquoi, pour chaque canal de chaque pixel, l’intensité lumineuse est comprise entre 0 et 255.
Si chaque canal est codé avec 8 bits, quelle est la profondeur de couleur ?
Combien de couleurs différentes sont-elles possibles avec une telle profondeur ?
A faire vous-même 2
Lancez le logiciel photofiltre puis ouvrez l’image souris.jpeg
Le codage le plus simple de l’image est celui en noir et blanc. Dans ce type de codage, la couleur est encodée sur un bit (=binary digit) qui peut prendre 2 valeurs (vrai ou faux, 0 ou 1, blanc ou noir, ouvert ou fermé… etc.)
Pour une image
matricielle en noir et blanc, telle que votre image initiale1.png,
chaque pixel est encodé par 1 bit noir ou blanc. Le format le plus élémentaire
d’image en noir et blanc est le format .pbm
(Portable Bit Map).
Vous disposez du fichier carré8×8.pbm qui correspond à un carré blanc de 8 X 8 pixels. Vous allez manipuler l’image avec le logiciel EditHexa ou éditeur en ligne HexEd.it.
Télécharger l’image zippé ci dessous, pensez à la dézipper et à l’enregistrer dans votre dossier.
Vous allez créer
une image en manipulant son encodage. Pour chaque étape, votre compte-rendu
comportera la copie d’écran de l’encodage et l’image obtenue.
A faire vous-même 1 : le codage
d’un carré blanc
Lancez le logiciel EditHexa (ou HexEd.it en ligne) et ouvrez le fichier carré8×8.pbm
Dans la fenêtre
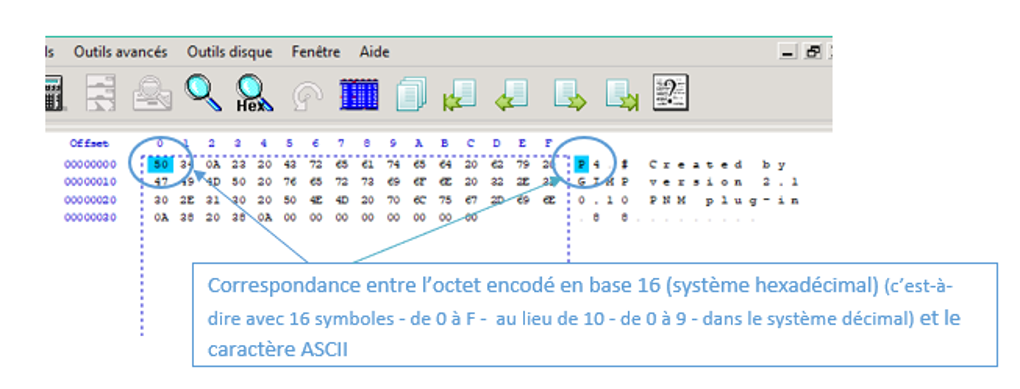
centrale, la partie encadrée contient l’encodage en octets et à droite,
il y a la traduction sous forme de texte selon la norme ASCII (à un code sur 7
ou 8 bits, correspond un caractère ou une commande)
Copie d’écran de EditHexa (pour HexEd.it, c’est le même principe)
A partir de ce
fichier,
Quel est le nombre d’octets qui encodent l’entête de l’image ? (astuce : cliquer sur différents octets dans la fenêtre centrale et vérifier à droite, à quelle « partie » du fichier cela correspond)
Déterminez le nombre d’octets qui encodent l’image elle-même.Quelle valeur ont-ils ?
Vous avez vu précédemment qu’un octet de l’image (ou du texte de l’entête) correspond à un « nombre » à 2 éléments.
Exemples : le G de GIMP correspond à 47, l’espace entre les deux 8, c’est 20 ou le point correspond à 0A.
Le système décimal utilise 10 symboles (de 0 à 9) : c’est notre système habituel de numération.
Le système binaire utilise 2 symboles (0 et 1) : utilisé car en électronique, le courant passe ou pas.
Le système hexadécimal utilise 16 symboles (0 à 9 et A à F) : cela permet d’écrire des nombres plus longs avec moins de symboles à avantage pour le stockage en informatique. C’est l’idéal pour les images !
Pour faire le travail suivant, il va falloir convertir un octet écrit avec 8 bits dans le système binaire (donc une série de huit 0 ou 1) en sa correspondance dans le système hexadécimal.
Prenons l’exemple de 2 octets 0000 0000 et 0011 1101. (remarque, on on écrit le nombre binaire en 2 paquets de 4 )
Pour convertir ces octets dans le système hexadécimal, on utilise le tableau de conversion ci-dessous pour chaque paquet de 4.
0000 0000 du système binaire devient 00 dans le système hexadécimal.
0011 1101 du système binaire devient 3D dans le système hexadécimal.
Hexadécimal
Binaire
0
0000
1
0001
2
0010
3
0011
4
0100
5
0101
6
0110
7
0111
8
1000
9
1001
A
1010
B
1011
C
1100
D
1101
E
1110
F
1111
A faire vous-même 2 : le codage d’un carré noir et d’un damier
Modifiez les bits des octets de l’image de manière à former un carré noir. (si besoin, revoir ce qui a été fait sur le codage d’un pixel dans la section précédente)
Avec l’outil en ligne HexEd.it, modifiez les valeurs des octets de l’image.
Avec EditHexa : Utilisez menu Outils avancés > manipuler les bitsou modifiez directement les valeurs dans la fenêtre centrale.
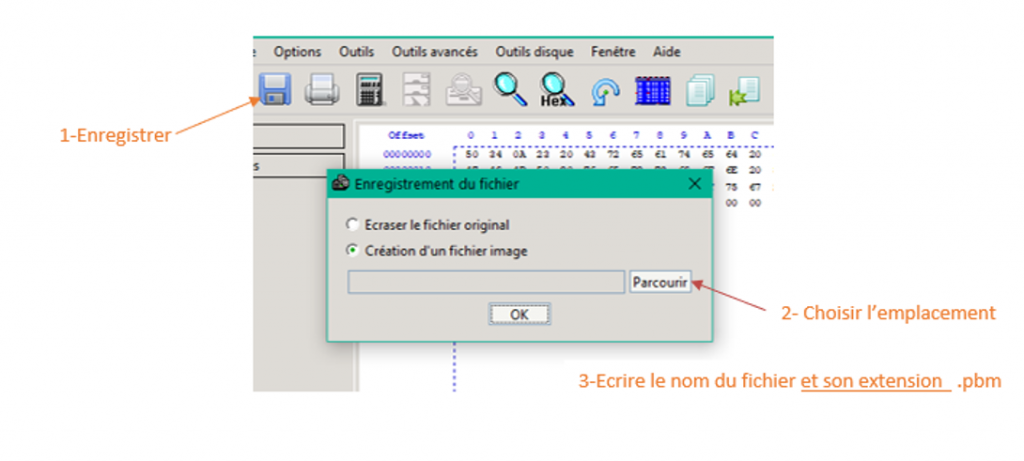
Enregistrez votre image sous le nom carrénoir.pbm
Vérifiez votre manipulation en ouvrant le fichier avec Photofiltre ou Gimp (Par défaut, les fichiers du format .pbm sont masqués : cliquez sur le menu déroulant « images les plus courantes » puis sélectionnez « toutes les images »)
Pour obtenir un carré 8×8 à rayure, il faut par exemple que la première ligne soit noire. Ce sera donc une suite de huit bits à 1, c’est-à-dire un octet dont tous les bits valent 1 qu’on peut écrire 1111 1111 ou alors FF. La deuxième ligne doit être blanche, donc c’est l’octet 0000 0000 ou 00 dans le système hexadécimal. Et ainsi de suite…
Procédez de la même façon pour obtenir un damier que vous appellerez damier.pbm astuce : au brouillon, réalisez un tableau de 8×8, coloriez les cases noires du damier que vous voulez obtenir.
A faire vous-même 3 : le codage de
l’initiale
Avec Photofiltre ou Gimp, ouvrez l’image initiale2.png créée à la séance précédente. Affichez la grille de repérage avec un pas de 2 pixels.
Avec EditHexa ou HexEd.it, modifiez l’encodage de l’image carré8×8.pbm de manière à reproduire le motif de votre initiale2.png Vous obtenez alors votre image (vérifiez avec Photofiltre) sur 8 X 8 pixels.
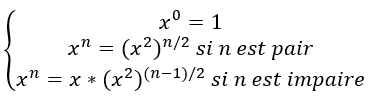


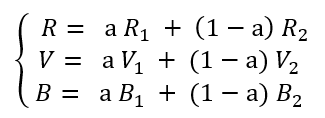



{kind=link}